hf-audio/open-asr-leaderboard
收藏Hugging Face2026-04-15 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/hf-audio/open-asr-leaderboard
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: ami
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 7313111859.091001
num_examples: 12643
download_size: 1300234949
dataset_size: 7313111859.091001
- config_name: common_voice
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 1312573669.596
num_examples: 16334
download_size: 720365151
dataset_size: 1312573669.596
- config_name: earnings22
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 2066334348.212
num_examples: 2741
download_size: 1103772123
dataset_size: 2066334348.212
- config_name: gigaspeech
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 9091854755.2
num_examples: 19931
download_size: 4034348699
dataset_size: 9091854755.2
- config_name: librispeech
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test.clean
num_bytes: 367597326.0
num_examples: 2620
- name: test.other
num_bytes: 352273450.594
num_examples: 2939
download_size: 683412729
dataset_size: 719870776.594
- config_name: spgispeech
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 18550272796.201
num_examples: 39341
download_size: 11377636910
dataset_size: 18550272796.201
- config_name: tedlium
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 301767463.0
num_examples: 1155
download_size: 301633880
dataset_size: 301767463.0
- config_name: voxpopuli
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 1612296642.268
num_examples: 1842
download_size: 944084987
dataset_size: 1612296642.268
- config_name: voxpopuli_cleaned_aa
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: dataset
dtype: string
- name: text
dtype: string
- name: id
dtype: string
- name: audio_length_s
dtype: float64
splits:
- name: test
num_bytes: 456030310.0
num_examples: 628
download_size: 377880242
dataset_size: 456030310.0
configs:
- config_name: ami
data_files:
- split: test
path: ami/test-*
- config_name: common_voice
data_files:
- split: test
path: common_voice/test-*
- config_name: earnings22
data_files:
- split: test
path: earnings22/test-*
- config_name: gigaspeech
data_files:
- split: test
path: gigaspeech/test-*
- config_name: librispeech
data_files:
- split: test.clean
path: librispeech/test.clean-*
- split: test.other
path: librispeech/test.other-*
- config_name: spgispeech
data_files:
- split: test
path: spgispeech/test-*
- config_name: tedlium
data_files:
- split: test
path: tedlium/test-*
- config_name: voxpopuli
data_files:
- split: test
path: voxpopuli/test-*
- config_name: voxpopuli_cleaned_aa
data_files:
- split: test
path: voxpopuli_cleaned_aa/test-*
extra_gated_prompt: "Three of the ESB datasets have specific terms of usage that must\
\ be agreed to before using the data. \nTo do so, fill in the access forms on the\
\ specific datasets' pages:\n * Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0\n\
\ * GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech\n * SPGISpeech:\
\ https://huggingface.co/datasets/kensho/spgispeech"
extra_gated_fields:
? I hereby confirm that I have registered on the original Common Voice page and
agree to not attempt to determine the identity of speakers in the Common Voice
dataset
: checkbox
I hereby confirm that I have accepted the terms of usages on GigaSpeech page: checkbox
I hereby confirm that I have accepted the terms of usages on SPGISpeech page: checkbox
---
# ESB Test Sets: Parquet & Sorted
This dataset takes the [open-asr-leaderboard/datasets-test-only](hf.co/datasets/open-asr-leaderboard/datasets-test-only) data and sorts each split by audio length.
The format is also changed, from custom loading script (un-safe remote code) to parquet (safe).
Broadly speaking, this dataset was generated with the following code-snippet:
```py
from datasets import load_dataset, get_dataset_config_names
DATASET = "open-asr-leaderboard/datasets-test-only" # dataset to load from
HUB_DATASET_ID = "hf-audio/esb-datasets-test-only-sorted" # dataset id to push to
config_names = get_dataset_config_names(DATASET)
for config in config_names:
dataset = load_dataset(DATASET, config)
sampling_rate = dataset[next(iter(dataset))].features["audio"].sampling_rate
def compute_audio_length(audio):
return {"audio_length_s": len(audio["array"]) / sampling_rate}
dataset = dataset.map(compute_audio_length, input_columns=["audio"])
dataset = dataset.sort("audio_length_s", reverse=True)
dataset.push_to_hub(HUB_DATASET_ID, config_name=config, private=True)
```
All eight of datasets in ESB can be downloaded and prepared in just a single line of code through the Hugging Face Datasets library:
```python
from datasets import load_dataset
librispeech = load_dataset("esb/datasets", "librispeech", split="train")
```
- `"esb/datasets"`: the repository namespace. This is fixed for all ESB datasets.
- `"librispeech"`: the dataset name. This can be changed to any of any one of the eight datasets in ESB to download that dataset.
- `split="train"`: the split. Set this to one of train/validation/test to generate a specific split. Omit the `split` argument to generate all splits for a dataset.
The datasets are full prepared, such that the audio and transcription files can be used directly in training/evaluation scripts.
## Dataset Information
A data point can be accessed by indexing the dataset object loaded through `load_dataset`:
```python
print(librispeech[0])
```
A typical data point comprises the path to the audio file and its transcription. Also included is information of the dataset from which the sample derives and a unique identifier name:
```python
{
'dataset': 'librispeech',
'audio': {'path': '/home/sanchit-gandhi/.cache/huggingface/datasets/downloads/extracted/d2da1969fe9e7d06661b5dc370cf2e3c119a14c35950045bcb76243b264e4f01/374-180298-0000.flac',
'array': array([ 7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ...,
-2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000},
'text': 'chapter sixteen i might have told you of the beginning of this liaison in a few lines but i wanted you to see every step by which we came i to agree to whatever marguerite wished',
'id': '374-180298-0000'
}
```
### Data Fields
- `dataset`: name of the ESB dataset from which the sample is taken.
- `audio`: a dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate.
- `text`: the transcription of the audio file.
- `id`: unique id of the data sample.
### Data Preparation
#### Audio
The audio for all ESB datasets is segmented into sample lengths suitable for training ASR systems. The Hugging Face datasets library decodes audio files on the fly, reading the segments and converting them to a Python arrays. Consequently, no further preparation of the audio is required to be used in training/evaluation scripts.
Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, i.e. `dataset[0]["audio"]` should always be preferred over `dataset["audio"][0]`.
#### Transcriptions
The transcriptions corresponding to each audio file are provided in their 'error corrected' format. No transcription pre-processing is applied to the text, only necessary 'error correction' steps such as removing junk tokens (_<unk>_) or converting symbolic punctuation to spelled out form (_<comma>_ to _,_). As such, no further preparation of the transcriptions is required to be used in training/evaluation scripts.
Transcriptions are provided for training and validation splits. The transcriptions are **not** provided for the test splits. ESB requires you to generate predictions for the test sets and upload them to https://huggingface.co/spaces/esb/leaderboard for scoring.
### Access
All eight of the datasets in ESB are accessible and licensing is freely available. Three of the ESB datasets have specific terms of usage that must be agreed to before using the data. To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
### Diagnostic Dataset
ESB contains a small, 8h diagnostic dataset of in-domain validation data with newly annotated transcriptions. The audio data is sampled from each of the ESB validation sets, giving a range of different domains and speaking styles. The transcriptions are annotated according to a consistent style guide with two formats: normalised and un-normalised. The dataset is structured in the same way as the ESB dataset, by grouping audio-transcription samples according to the dataset from which they were taken. We encourage participants to use this dataset when evaluating their systems to quickly assess performance on a range of different speech recognition conditions. For more information, visit: [esb/diagnostic-dataset](https://huggingface.co/datasets/esb/diagnostic-dataset).
## Summary of ESB Datasets
| Dataset | Domain | Speaking Style | Train (h) | Dev (h) | Test (h) | Transcriptions | License |
|--------------|-----------------------------|-----------------------|-----------|---------|----------|--------------------|-----------------|
| LibriSpeech | Audiobook | Narrated | 960 | 11 | 11 | Normalised | CC-BY-4.0 |
| Common Voice | Wikipedia | Narrated | 1409 | 27 | 27 | Punctuated & Cased | CC0-1.0 |
| Voxpopuli | European Parliament | Oratory | 523 | 5 | 5 | Punctuated | CC0 |
| TED-LIUM | TED talks | Oratory | 454 | 2 | 3 | Normalised | CC-BY-NC-ND 3.0 |
| GigaSpeech | Audiobook, podcast, YouTube | Narrated, spontaneous | 2500 | 12 | 40 | Punctuated | apache-2.0 |
| SPGISpeech | Fincancial meetings | Oratory, spontaneous | 4900 | 100 | 100 | Punctuated & Cased | User Agreement |
| Earnings-22 | Fincancial meetings | Oratory, spontaneous | 105 | 5 | 5 | Punctuated & Cased | CC-BY-SA-4.0 |
| AMI | Meetings | Spontaneous | 78 | 9 | 9 | Punctuated & Cased | CC-BY-4.0 |
## LibriSpeech
The LibriSpeech corpus is a standard large-scale corpus for assessing ASR systems. It consists of approximately 1,000 hours of narrated audiobooks from the [LibriVox](https://librivox.org) project. It is licensed under CC-BY-4.0.
Example Usage:
```python
librispeech = load_dataset("esb/datasets", "librispeech")
```
Train/validation splits:
- `train` (combination of `train.clean.100`, `train.clean.360` and `train.other.500`)
- `validation.clean`
- `validation.other`
Test splits:
- `test.clean`
- `test.other`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
librispeech = load_dataset("esb/datasets", "librispeech", subconfig="clean.100")
```
- `clean.100`: 100 hours of training data from the 'clean' subset
- `clean.360`: 360 hours of training data from the 'clean' subset
- `other.500`: 500 hours of training data from the 'other' subset
## Common Voice
Common Voice is a series of crowd-sourced open-licensed speech datasets where speakers record text from Wikipedia in various languages. The speakers are of various nationalities and native languages, with different accents and recording conditions. We use the English subset of version 9.0 (27-4-2022), with approximately 1,400 hours of audio-transcription data. It is licensed under CC0-1.0.
Example usage:
```python
common_voice = load_dataset("esb/datasets", "common_voice", use_auth_token=True)
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## VoxPopuli
VoxPopuli is a large-scale multilingual speech corpus consisting of political data sourced from 2009-2020 European Parliament event recordings. The English subset contains approximately 550 hours of speech largely from non-native English speakers. It is licensed under CC0.
Example usage:
```python
voxpopuli = load_dataset("esb/datasets", "voxpopuli")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## TED-LIUM
TED-LIUM consists of English-language TED Talk conference videos covering a range of different cultural, political, and academic topics. It contains approximately 450 hours of transcribed speech data. It is licensed under CC-BY-NC-ND 3.0.
Example usage:
```python
tedlium = load_dataset("esb/datasets", "tedlium")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## GigaSpeech
GigaSpeech is a multi-domain English speech recognition corpus created from audiobooks, podcasts and YouTube. We provide the large train set (2,500 hours) and the standard validation and test splits. It is licensed under apache-2.0.
Example usage:
```python
gigaspeech = load_dataset("esb/datasets", "gigaspeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (2,500 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
gigaspeech = load_dataset("esb/datasets", "spgispeech", subconfig="xs", use_auth_token=True)
```
- `xs`: extra-small subset of training data (10 h)
- `s`: small subset of training data (250 h)
- `m`: medium subset of training data (1,000 h)
- `xl`: extra-large subset of training data (10,000 h)
## SPGISpeech
SPGISpeech consists of company earnings calls that have been manually transcribed by S&P Global, Inc according to a professional style guide. We provide the large train set (5,000 hours) and the standard validation and test splits. It is licensed under a Kensho user agreement.
Loading the dataset requires authorization.
Example usage:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (~5,000 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", subconfig="s", use_auth_token=True)
```
- `s`: small subset of training data (~200 h)
- `m`: medium subset of training data (~1,000 h)
## Earnings-22
Earnings-22 is a 119-hour corpus of English-language earnings calls collected from global companies, with speakers of many different nationalities and accents. It is licensed under CC-BY-SA-4.0.
Example usage:
```python
earnings22 = load_dataset("esb/datasets", "earnings22")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## AMI
The AMI Meeting Corpus consists of 100 hours of meeting recordings from multiple recording devices synced to a common timeline. It is licensed under CC-BY-4.0.
Example usage:
```python
ami = load_dataset("esb/datasets", "ami")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
# Citation
If you use this dataset, please cite the following:
```bibtex
@misc{srivastav2025openasrleaderboardreproducible,
title={Open ASR Leaderboard: Towards Reproducible and Transparent Multilingual and Long-Form Speech Recognition Evaluation},
author={Vaibhav Srivastav and Steven Zheng and Eric Bezzam and Eustache Le Bihan and Nithin Koluguri and Piotr Żelasko and Somshubra Majumdar and Adel Moumen and Sanchit Gandhi},
year={2025},
eprint={2510.06961},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2510.06961},
}
```
提供机构:
hf-audio
搜集汇总
数据集介绍
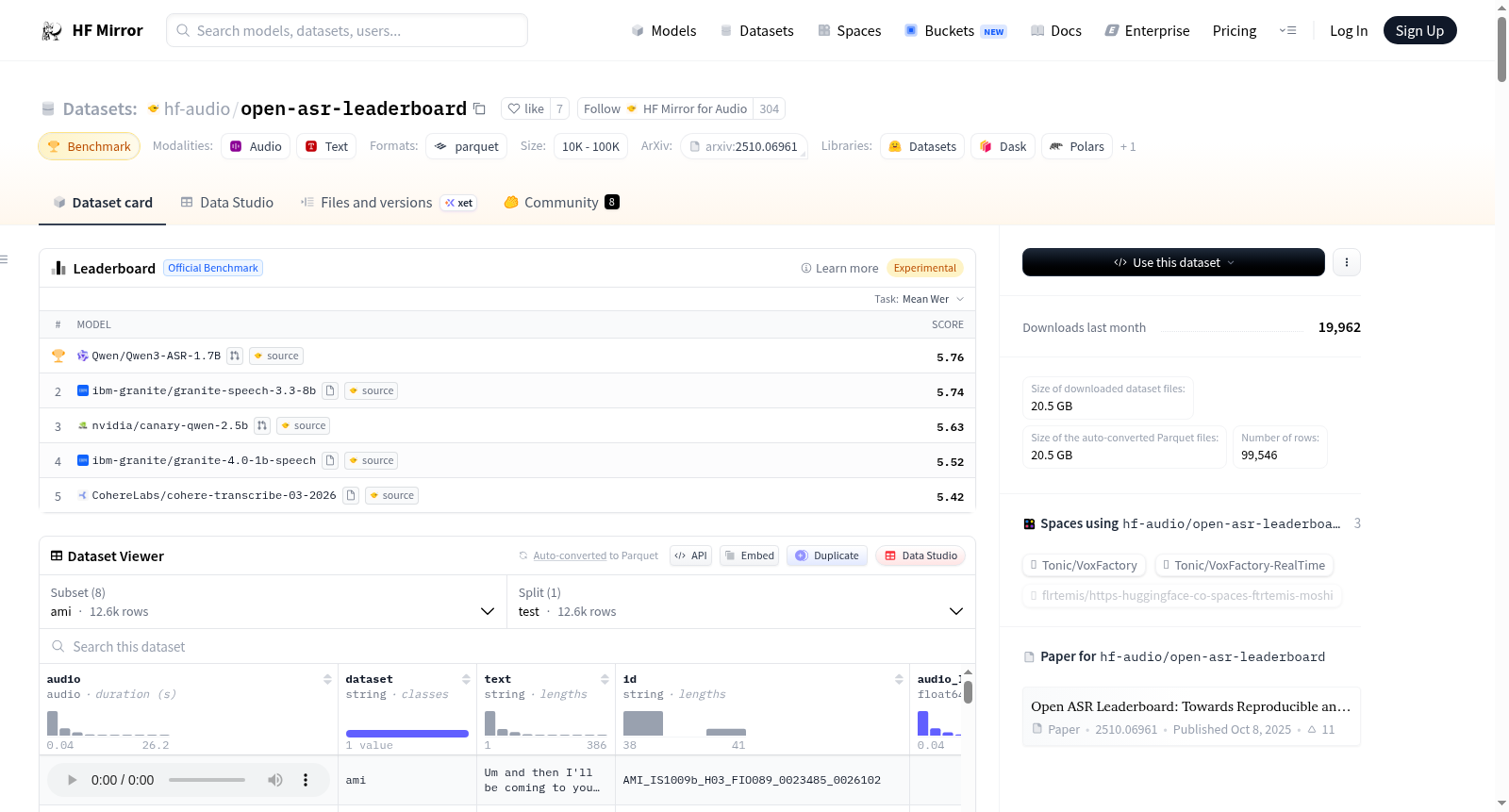
构建方式
在自动语音识别领域,构建一个全面且标准化的评估基准对于推动技术进步至关重要。open-asr-leaderboard数据集通过整合八个广泛使用的公开语音识别测试集,包括LibriSpeech、Common Voice、VoxPopuli等,形成了一个统一的评估框架。其构建过程采用了系统化的数据整理方法,从原始数据源加载各子集后,统一将音频采样率标准化为16kHz,并计算每条音频的时长信息。随后,数据按照音频长度进行降序排列,并将存储格式转换为更安全、高效的Parquet格式,确保了数据加载的便捷性与处理过程的可复现性。
特点
该数据集的核心特征在于其高度的集成性与多样性,涵盖了从有声读物、会议录音到公开演讲、播客等多种语音领域和说话风格,为评估模型在不同场景下的鲁棒性提供了丰富素材。所有音频数据均经过预处理,分割为适合模型训练的片段,并配有经过纠错处理的文本转录,确保了数据质量的统一性。数据集结构设计清晰,每个样本均包含音频路径、波形数组、转录文本、唯一标识符及所属子集名称,便于研究者进行精确的索引与调用。
使用方法
使用该数据集进行模型评估或训练时,研究者可通过Hugging Face Datasets库以简洁的代码行加载任意子集,例如调用`load_dataset("esb/datasets", "librispeech", split="test")`即可获取LibriSpeech的测试数据。加载后的数据对象可直接用于训练或评估脚本,音频文件在访问时自动解码并重采样至指定频率。需要注意的是,对于测试集,转录文本不予提供,研究者需将模型预测结果提交至指定平台进行自动化评分。部分子集如Common Voice、GigaSpeech等在使用前需遵循其特定许可协议,完成相应的访问授权流程。
背景与挑战
背景概述
在自动语音识别(ASR)领域,构建标准化、可复现的评估基准是推动技术进步的关键。Open ASR Leaderboard数据集由Hugging Face社区的研究人员于2025年创建,旨在整合多个权威语音数据集,形成一个统一的、透明的多领域ASR评估平台。该数据集汇集了LibriSpeech、Common Voice、GigaSpeech等八个核心数据集,覆盖了从有声读物、播客到会议录音等多种语音领域和说话风格。其核心研究问题在于解决以往ASR评估中存在的领域偏差、评估标准不一致以及结果难以复现的难题,为研究人员提供了一个全面、公平的性能比较框架,显著提升了ASR系统评估的科学性与可靠性。
当前挑战
该数据集致力于解决自动语音识别领域内模型泛化能力评估的挑战,其核心在于如何设计一个能够公平、全面衡量ASR系统在不同领域(如朗读、自发性对话、演讲)和不同声学条件下性能的基准。具体挑战包括:处理来自八个独立数据集的语音在录音质量、说话人背景、文本规范(如标点符号处理、大小写)方面的巨大异质性;确保评估过程的可复现性与透明度,避免因数据预处理或评估流程的差异导致结果偏差。在构建过程中,挑战主要集中于数据整合与标准化,例如将不同格式的原始音频统一转换为16kHz采样率,对转录文本进行一致的错误校正与规范化处理,同时需严格遵守各源数据集复杂的许可协议与使用条款,确保数据分发的合法合规性。
常用场景
经典使用场景
在自动语音识别领域,open-asr-leaderboard数据集作为标准化评估基准,其经典使用场景在于为各类ASR模型提供统一、全面的性能测试平台。该数据集整合了八个不同领域和风格的语音测试集,涵盖从朗读式有声书到自发式会议讨论的多样化语音样本,研究人员能够通过单一接口加载这些数据,便捷地评估模型在多种真实场景下的识别准确率与鲁棒性。这种集成化设计极大简化了跨领域语音识别系统的对比实验流程。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作,特别是基于其构建的开放ASR排行榜(Open ASR Leaderboard)本身已成为领域内重要的成果展示与比较平台。相关研究通过利用该数据集的多领域测试集,深入探索了端到端语音识别模型的领域自适应、少样本学习以及长语音处理等前沿课题。此外,数据集的标准格式也促进了诸如Whisper、Wav2Vec 2.0等主流开源模型在其上的系统性评估与性能基准的建立,推动了整个语音识别社区向更透明、可比较的方向发展。
数据集最近研究
最新研究方向
在自动语音识别领域,open-asr-leaderboard数据集作为标准化评估基准,正推动着多领域、多风格语音识别技术的前沿探索。该数据集整合了LibriSpeech、Common Voice、GigaSpeech等八个涵盖有声读物、会议、演讲等多样化场景的测试集,为模型在复杂声学环境与多口音条件下的鲁棒性提供了统一度量。当前研究热点聚焦于利用该基准进行跨领域自适应学习、长序列语音处理以及低资源场景下的泛化能力评估,特别是在金融会议、自发对话等专业领域,其标准化测试流程显著提升了研究成果的可比性与可复现性,加速了端到端语音识别模型向实用化迈进。
以上内容由遇见数据集搜集并总结生成


