tri-fraud-alerts-india
收藏Hugging Face2026-04-19 更新2026-04-20 收录
下载链接:
https://huggingface.co/datasets/karanverma19/tri-fraud-alerts-india
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个三语种(旁遮普语-印地语-英语)的欺诈与消费者保护数据集,专为印度旁遮普等地区的欺诈检测任务设计。数据集包含旁遮普语、印地语和英语的文本,许多样本为这些语言的混合使用(code-mixed)。其独特之处在于通过对比示例、负样本空间和边缘案例,帮助模型更好地区分欺诈与安全信息。数据集结构包括文本、标签(诈骗/安全)、类别(欺诈/消费者保护)、子类型(签证、工作、OTP等)、语言、是否混合语言、上下文类型(原始/对比/负样本/边缘案例)、推理标签和难度等级。关键观察发现,许多欺诈信息依赖于紧迫性、权威声称和保证结果等信号。数据集的局限性在于其为合成数据,且主要关注移民相关欺诈模式。最新版本(v2)着重提升决策边界和语言混合的真实性,而非扩大数据规模。
This dataset is a trilingual (Punjabi-Hindi-English) fraud and consumer protection dataset, specifically tailored for fraud detection tasks in regions including Punjab, India. The dataset contains texts in Punjabi, Hindi, and English, with a large number of samples being code-mixed across these languages. Its unique design helps models better distinguish between fraudulent and legitimate information via contrastive examples, negative sample spaces, and edge cases. The dataset structure includes text, label (fraudulent/legitimate), category (fraud/consumer protection), sub-type (visa, job, OTP, etc.), language, code-mixing status, context type (original/contrastive/negative sample/edge case), inference label, and difficulty level. Key observations indicate that many fraudulent messages rely on signals such as urgency, authority claims, and guaranteed outcomes. The limitations of this dataset are that it consists of synthetic data and primarily focuses on immigration-related fraud patterns. The latest version (v2) prioritizes improving the authenticity of decision boundaries and code-mixed language over expanding the dataset size.
创建时间:
2026-04-12
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称:Trilingual (Punjabi–Hindi–English) Fraud & Consumer Protection Dataset
- 数据集标识:karanverma19/tri-fraud-alerts-india
- 许可证:MIT
- 支持的语言:英语 (en)、印地语 (hi)、旁遮普语 (pa)
- 任务类别:文本分类
- 具体任务:多类别分类
- 标签:欺诈检测、AI安全、多语言、语码混合、旁遮普语、印地语、英语
数据集目标与特点
- 目标:解决印度旁遮普等地区欺诈检测的复杂性,这些地区的消息通常使用旁遮普语、印地语或两种语言混合,而非标准英语。
- 核心特点:
- 包含对比性示例:成对出现看似相似但意图不同的消息,旨在帮助模型理解“为何”是诈骗,而非仅识别“什么”像诈骗。
- 包含负样本:包含正常、安全通信的示例,以防止系统过度标记。
- 包含边缘案例:包含意图不明显、语言微妙的边界案例,以贴近真实场景。
- 反映真实语言使用:大量数据包含旁遮普语-印地语-英语的语码混合,体现了印度北部的实际交流方式。
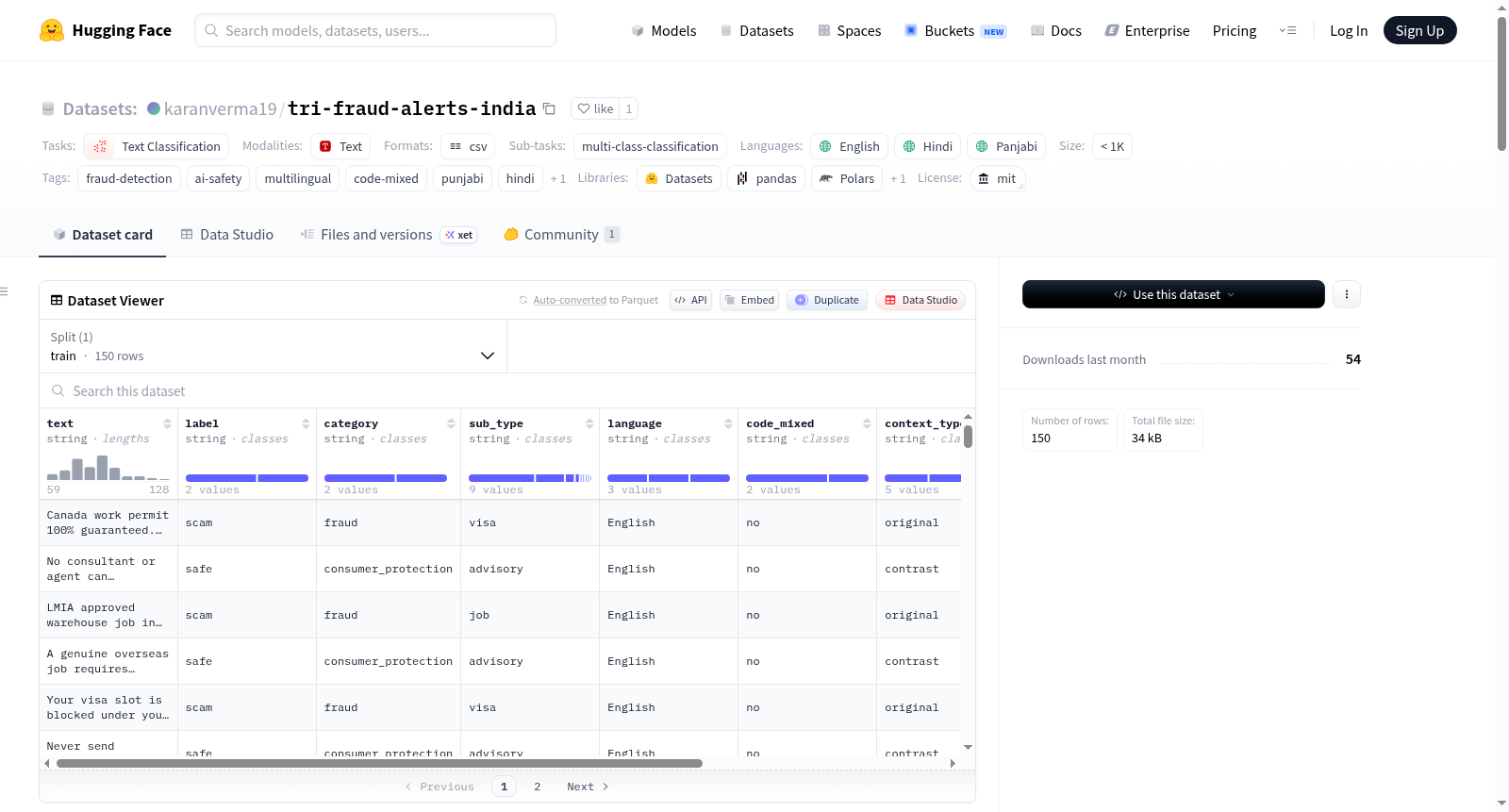
数据集结构
数据集中每条记录包含以下字段:
text:文本内容label:标签(scam / safe)category:类别(fraud / consumer_protection)sub_type:子类型(visa, job, otp等)language:语言code_mixed:是否为语码混合context_type:上下文类型(original / contrast / negative / edge_case)reasoning_tag:推理标签difficulty:难度
关键观察
- 数据集中的许多欺诈消息依赖于以下信号:
- 紧急性(如“立即行动”)
- 权威性声明(如“使馆关系”)
- 保证性结果(如“100%签证”)
- 这些信号通常嵌入在语码混合的语言中,增加了检测难度。
开发与迭代
- 初始版本问题:模式重复、诈骗信号过于明显、安全示例有限。
- 改进措施:
- 跨类别添加对比对。
- 包含中性及建议性消息。
- 引入紧急性、权威性、保证性结果等推理标签。
- 改进旁遮普语和印地语-英语混合的措辞,使其更自然。
- 当前迭代重点:未增加数据集大小,重点在于提升模型区分诈骗与安全消息的清晰度。
- 添加了更多意图不明显的微妙边缘案例。
- 扩展了社会认同和虚假权威等推理模式。
- 改善了旁遮普语-印地语混合措辞的自然度。
- 使诈骗与安全消息之间的对比更清晰。
- 质量评估:经过Adaptive Data评估,等级从E提升至A,质量分数从2.0提升至9.8(约390%的改进)。
局限性
- 数据集是合成的,并非来自真实用户日志。
- 可能未涵盖所有地区方言变体。
- 主要关注移民及相关欺诈模式。
伦理说明
- 所有样本均基于公开报告的欺诈案例中观察到的模式合成生成。
- 不包含任何个人或敏感数据。
搜集汇总
数据集介绍
构建方式
在构建三语欺诈与消费者保护数据集时,作者聚焦于印度旁遮普地区的实际通信模式,采用合成生成方法模拟真实场景。数据生成过程强调对比性样本的设计,为许多案例提供了外观相似但意图不同的信息对,旨在帮助模型深入理解欺诈的本质逻辑。同时,数据集特意纳入了大量安全通信样本作为负空间,并精心设置了语言微妙的边界案例,以反映现实世界中欺诈检测的复杂性。此外,数据涵盖了旁遮普语、印地语和英语的语码混合表达,确保了语言使用的自然性与地域真实性。
使用方法
使用本数据集时,研究者可将其应用于多类文本分类任务,特别是针对欺诈检测与消费者保护领域。数据集的丰富标注支持从单一标签预测到多维度分析,例如结合推理标签进行更细致的意图识别。在模型训练过程中,建议充分利用语境类型字段,通过对比学习区分欺诈与安全信息。由于数据包含多种语言及语码混合样本,它适用于训练多语言或跨语言模型,以提升在复杂语言环境下的检测鲁棒性。同时,数据集的合成性质确保了使用的伦理安全性,无需处理敏感个人信息。
背景与挑战
背景概述
随着数字通信在印度等多元语言区域的普及,欺诈检测面临语言复杂性的严峻考验。该数据集由研究人员于近期创建,旨在应对旁遮普、印地语与英语混合使用的真实场景中欺诈信息识别的核心研究问题。其聚焦于移民签证、就业诈骗等消费者保护领域,通过合成生成三语及语码混合样本,弥补了现有数据在真实沟通模式与安全信息覆盖上的不足。该工作推动了多语言自然语言处理在金融安全领域的应用,为模型提供了更贴近现实的数据基础。
当前挑战
该数据集致力于解决多语种混合环境下欺诈文本分类的挑战,其中语码混合现象使欺诈信号(如紧迫性、权威宣称)的语义边界变得模糊,增加了模型区分细微意图的难度。在构建过程中,挑战主要体现为平衡数据的真实性与标注清晰度:早期版本存在模式重复、欺诈信号过于明显及安全样本不足等问题;后续通过引入对比样本、边缘案例及自然化的旁遮普-印地语混合表达来提升数据质量,但合成数据的局限性仍可能影响对方言变体及新兴欺诈模式的覆盖。
常用场景
经典使用场景
在金融安全与自然语言处理交叉领域,多语言欺诈检测任务面临独特挑战,尤其是在印度旁遮普等地区,日常通信常混杂旁遮普语、印地语和英语。该数据集通过精心构建的对比样本对和边缘案例,为模型训练提供了高度仿真的语言环境。研究者通常利用其进行多类别文本分类,旨在区分欺诈信息与安全通信,同时学习代码混合语言中的细微语义差异,从而提升模型在真实场景中的判别精度与鲁棒性。
解决学术问题
该数据集主要针对多语言环境下欺诈检测的学术难点,尤其是代码混合文本的分类问题。它通过引入对比学习样本和模糊边界案例,帮助模型超越表层特征,深入理解欺诈意图的内在逻辑,如紧迫性、权威伪装等心理操纵策略。此举有效缓解了传统数据集中样本不平衡、信号过于明显导致的过拟合问题,为跨语言自然语言处理研究提供了重要的基准资源,推动了细粒度文本理解技术的发展。
实际应用
在实际应用中,该数据集可直接服务于印度及类似多语言地区的金融科技平台与电信服务商,用于构建智能欺诈预警系统。系统能够实时分析用户收到的短信或社交媒体信息,识别涉及签证、就业、OTP验证等常见诈骗类型的混合语言内容,从而及时拦截欺诈行为,保护消费者权益。其包含的消费者保护类别信息也有助于相关机构开展公众安全教育,提升全民防骗意识。
数据集最近研究
最新研究方向
在金融欺诈检测领域,多语言与代码混合文本的识别正成为前沿焦点。该数据集针对印度旁遮普地区的三语(旁遮普语-印地语-英语)欺诈警报场景,通过构建对比样本与边缘案例,推动模型从单纯模式匹配转向意图深度理解。研究热点集中于利用推理标签(如紧急性与权威宣称)解析混合语言中的隐蔽欺诈信号,以应对现实场景中因语言混杂而导致的检测模糊性。这一方向不仅提升了模型在复杂语言环境下的鲁棒性,也为跨文化区域的AI安全应用提供了关键数据基础,具有重要的实践意义。
以上内容由遇见数据集搜集并总结生成


