video
收藏Hugging Face2026-03-27 更新2026-03-28 收录
下载链接:
https://huggingface.co/datasets/lyl472324464/video
下载链接
链接失效反馈官方服务:
资源简介:
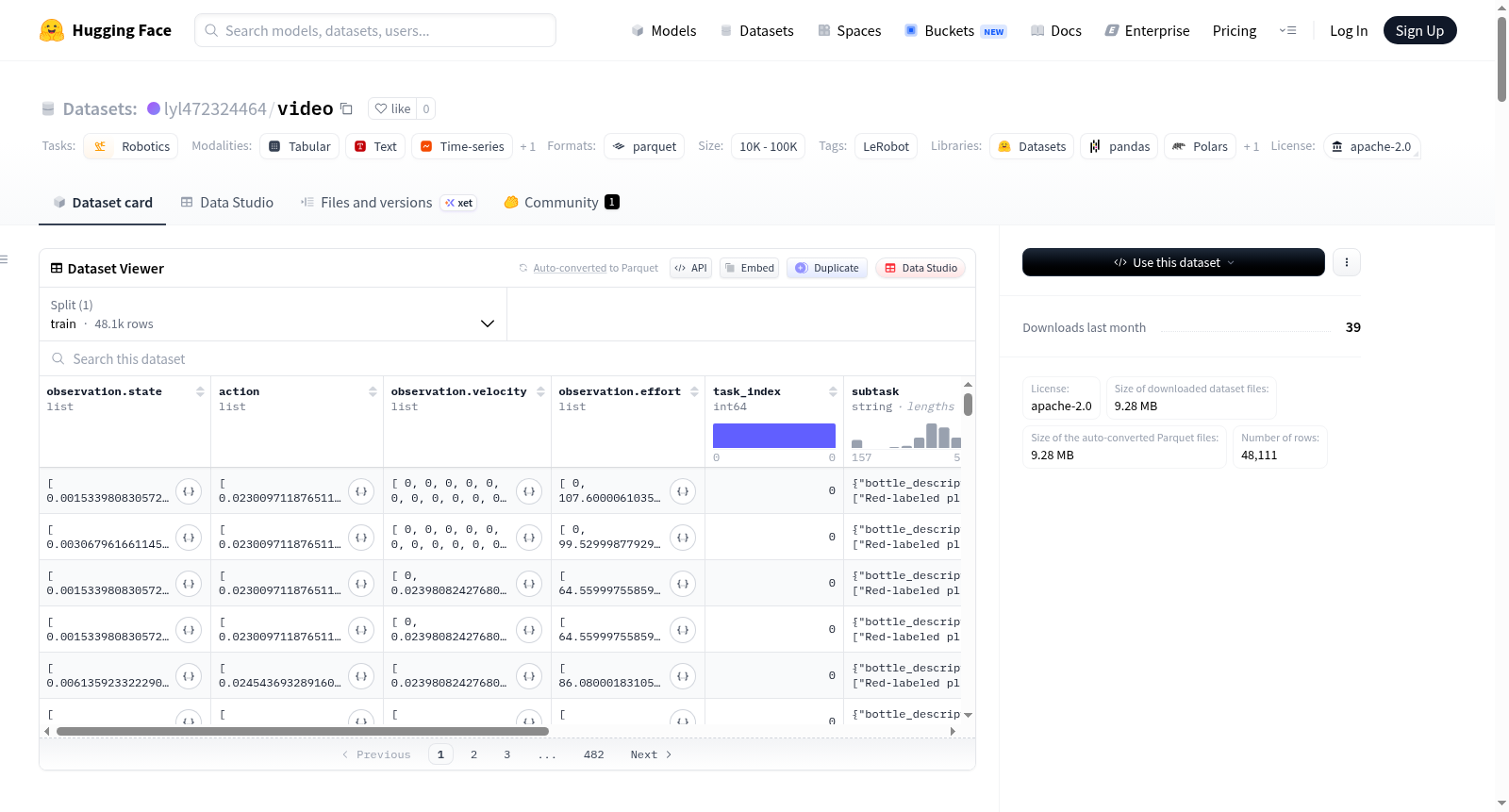
该数据集由LeRobot创建,专为机器人学任务设计,采用apache-2.0许可证。数据集包含32个总片段,40,172帧,涉及1个总任务。数据以parquet文件格式存储,总数据文件和视频文件大小各为200MB,帧率为50fps。数据集结构包括训练分割(0:32)。数据特征丰富,包括机器人状态观察(14个浮点型关节状态)、动作(14个浮点型关节动作)、速度(14个浮点型关节速度)、力矩(14个浮点型关节力矩)以及来自四个不同摄像头(cam_high, cam_low, cam_left_wrist, cam_right_wrist)的视频图像(3通道,480x640分辨率,50fps,AV1编码)。此外,还包含任务索引、子任务、训练标志、时间戳、帧索引、片段索引等辅助信息。适用于机器人控制、行为克隆等研究场景。
This dataset was created by LeRobot, specifically designed for robotics tasks and licensed under Apache-2.0. It contains a total of 32 segments and 40,172 frames, covering 1 overall task. The data is stored in Parquet file format, with both the total data files and video files being 200 MB in size, and the frame rate is 50 fps. The dataset structure includes the training split (0:32). It has rich data features, including robot state observations (14 floating-point joint states), actions (14 floating-point joint actions), velocities (14 floating-point joint velocities), torques (14 floating-point joint torques), as well as video images from four distinct cameras (cam_high, cam_low, cam_left_wrist, cam_right_wrist) with 3 channels, 480×640 resolution, 50 fps, and AV1 encoding. Additionally, it includes auxiliary information such as task index, subtasks, training flag, timestamp, frame index, and segment index. It is suitable for research scenarios such as robot control and behavior cloning.
创建时间:
2026-03-27
原始信息汇总
数据集概述
基本信息
- 数据集名称: video
- 创建工具: LeRobot (https://github.com/huggingface/lerobot)
- 许可协议: Apache-2.0
- 任务类别: 机器人学
- 标签: LeRobot
数据集规模与结构
- 总情节数: 32
- 总帧数: 48,111
- 总任务数: 1
- 数据块大小: 1,000
- 数据文件大小: 200 MB
- 视频文件大小: 200 MB
- 帧率: 50 FPS
- 数据分割: 训练集 (0:32)
数据文件路径
- 数据文件路径模式:
data/chunk-{chunk_index:03d}/file-{file_index:03d}.parquet - 视频文件路径模式:
videos/{video_key}/chunk-{chunk_index:03d}/file-{file_index:03d}.mp4
数据特征
机器人状态与动作
- observation.state: 浮点32位数组,形状[14],表示左右机械臂的14个关节状态。
- action: 浮点32位数组,形状[14],表示左右机械臂的14个关节动作。
- observation.velocity: 浮点32位数组,形状[14],表示左右机械臂的14个关节速度。
- observation.effort: 浮点32位数组,形状[14],表示左右机械臂的14个关节力/力矩。
图像观测
- observation.images.cam_high: 视频数据,形状[3, 480, 640],编码格式AV1,像素格式yuv420p,50 FPS,3通道,无音频。
- observation.images.cam_low: 视频数据,形状[3, 480, 640],编码格式AV1,像素格式yuv420p,50 FPS,3通道,无音频。
- observation.images.cam_left_wrist: 视频数据,形状[3, 480, 640],编码格式AV1,像素格式yuv420p,50 FPS,3通道,无音频。
- observation.images.cam_right_wrist: 视频数据,形状[3, 480, 640],编码格式AV1,像素格式yuv420p,50 FPS,3通道,无音频。
元数据
- task_index: 整型64位,形状[1]。
- subtask: 字符串,形状[1]。
- is_for_training: 布尔型,形状[1]。
- timestamp: 浮点32位,形状[1]。
- frame_index: 整型64位,形状[1]。
- episode_index: 整型64位,形状[1]。
- index: 整型64位,形状[1]。
技术详情
- 代码库版本: v3.0
- 机器人类型: aloha
- 关节命名: left_waist, left_shoulder, left_elbow, left_forearm_roll, left_wrist_angle, left_wrist_rotate, left_gripper, right_waist, right_shoulder, right_elbow, right_forearm_roll, right_wrist_angle, right_wrist_rotate, right_gripper。
引用信息
- 主页: 信息缺失
- 论文: 信息缺失
- BibTeX引用: 信息缺失
搜集汇总
数据集介绍
构建方式
在机器人学习领域,高质量的数据集是推动算法进步的关键基石。本数据集依托LeRobot框架构建,专门针对双臂机器人ALOHA系统,通过采集32个完整任务片段,累计48111帧数据,以50帧每秒的速率记录多视角视频与机器人状态信息。数据以分块Parquet格式存储,每块包含1000帧,确保了高效的数据管理与读取,为模仿学习与强化学习研究提供了结构化的时序交互记录。
特点
该数据集的核心特征在于其多维度的同步观测能力,不仅包含14维关节状态、速度与力矩的精确数值,还整合了四个高清摄像头(全局高/低视角及双腕部视角)的视觉流,形成多模态感知矩阵。视频数据采用AV1编码,以480×640分辨率呈现,兼具轻量化与视觉保真度。数据字段涵盖任务索引、子任务描述及训练标识等元信息,支持细粒度的任务分析与轨迹切片,为复杂操作策略的端到端学习创造了条件。
使用方法
研究者可通过HuggingFace平台直接加载数据集,利用LeRobot工具链进行数据解析与预处理。数据集已预分为训练集,涵盖全部32个片段,用户可依据帧索引、任务索引等字段灵活提取特定片段或时序窗口。多模态数据允许联合训练视觉-动作映射模型,亦支持单独使用状态数据进动力学建模。数据集的标准化格式便于集成至主流机器人学习框架,加速从仿真到实机的算法迁移与验证。
背景与挑战
背景概述
在机器人学习领域,高质量、大规模的真实世界交互数据对于推动模仿学习与强化学习算法的进步至关重要。该数据集依托LeRobot开源框架构建,专注于双手机械臂(ALOHA系统)的灵巧操作任务,其核心研究问题在于如何从多视角视觉观测与高维关节状态数据中,学习能够泛化至复杂物理环境的机器人控制策略。尽管具体创建时间与主要研究人员信息在现有文档中尚未明确披露,但该数据集通过整合关节状态、速度、力矩及多路高清视频流,为端到端机器人策略学习提供了宝贵的多模态数据基础,有望促进机器人自主操作能力的实质性突破。
当前挑战
该数据集旨在解决机器人模仿学习中的核心挑战,即如何从高维、异构的感知-动作数据中学习鲁棒且可泛化的控制策略。其面临的领域挑战包括:多模态数据(如视频流与关节状态)的时间对齐与高效融合、在动态物理环境中动作序列的长时程依赖建模,以及从有限任务演示中实现对新场景与对象的零样本泛化。在构建过程中,挑战则体现于大规模机器人数据采集的硬件同步与校准、海量视频数据的高效压缩存储与读取,以及确保数据序列在长时间采集过程中的完整性与一致性。
常用场景
经典使用场景
在机器人学习领域,该数据集以其多视角视频流与高维状态动作对的同步记录,为模仿学习与行为克隆提供了典型范例。研究者可基于此数据集训练深度神经网络,使机器人通过观察人类演示视频,学习复杂操作任务,如双手机械臂的协调控制。数据集包含来自固定摄像头及腕部摄像头的视觉信息,结合精确的关节状态、速度与力矩数据,构建了从感知到动作的端到端学习框架,有效支持了视觉-运动映射模型的开发与验证。
解决学术问题
该数据集直接应对机器人学中样本效率低下与泛化能力不足的核心挑战。通过提供大规模、多模态的演示数据,它使得数据驱动的策略学习成为可能,缓解了传统强化学习对大量环境交互的依赖。数据集的结构化设计促进了模仿学习、离线强化学习等算法的比较与评估,为解决现实世界中机器人操作任务的高维状态空间与动态不确定性提供了基准。其存在推动了从仿真到实物的迁移研究,为构建通用型机器人技能库奠定了数据基础。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在提升模仿学习的鲁棒性与泛化性上。例如,研究者利用其多视角视频数据开发了视角不变的行为克隆模型,或结合状态动作对训练了用于策略蒸馏的变分自编码器。此外,该数据集常被用作基准,评估不同离线强化学习算法在机器人操作任务上的性能。这些工作不仅深化了对视觉-运动协同的理解,也催生了如扩散策略、Transformer-based策略网络等新颖架构,持续推动着机器人学习前沿的发展。
以上内容由遇见数据集搜集并总结生成


