OmniAgentBench
收藏Hugging Face2026-04-17 更新2026-04-18 收录
下载链接:
https://huggingface.co/datasets/omniagentbench/OmniAgentBench
下载链接
链接失效反馈官方服务:
资源简介:
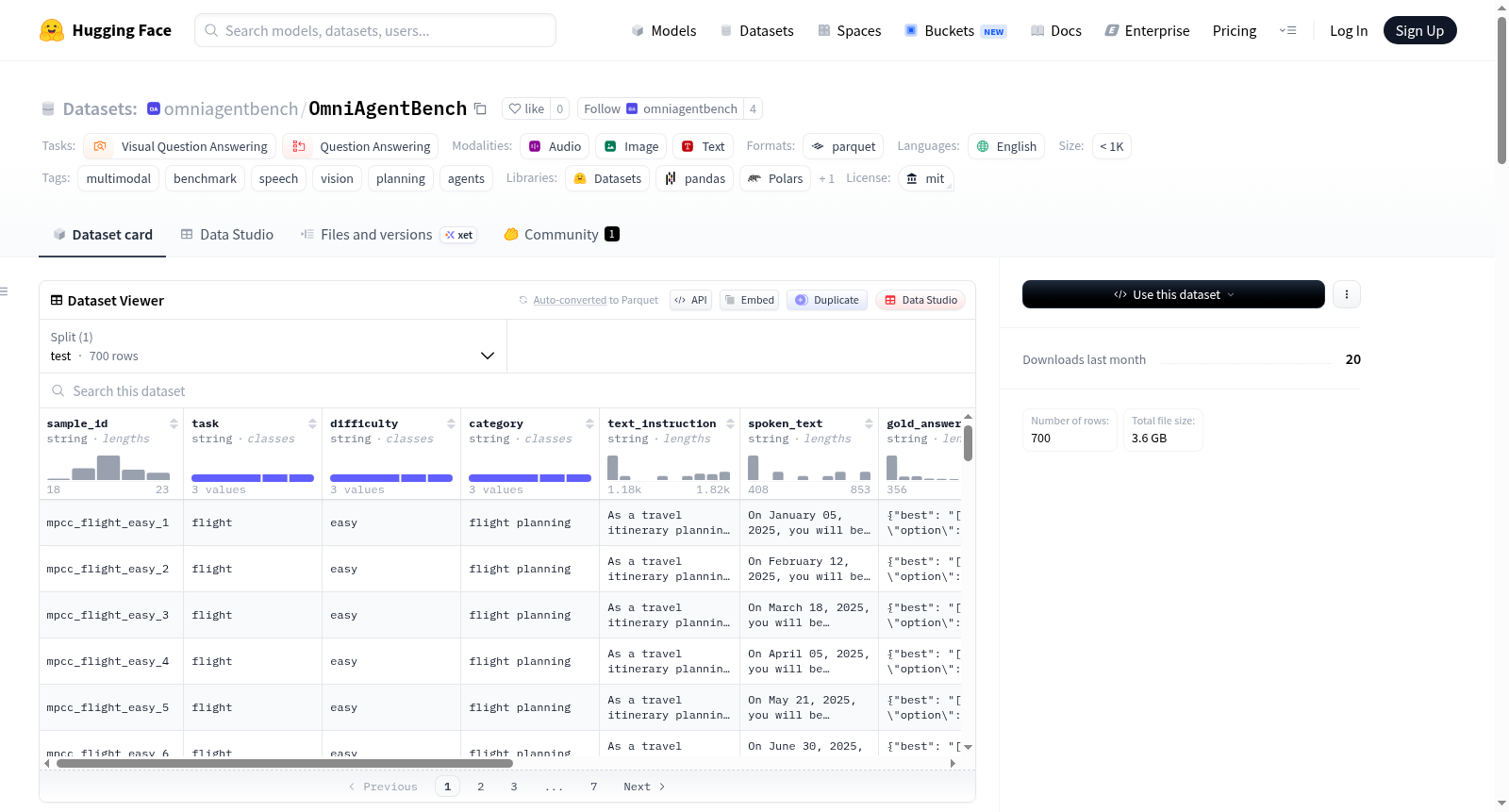
OmniAgentBench 是一个多模态基准数据集,旨在评估多模态 LLM 代理在真实条件下处理规划任务的鲁棒性。数据集包含文本、图像和语音音频三种模态,构建于 MPCC(多模态规划与协调挑战)数据集之上,涵盖三种规划任务:航班规划、日历规划和会议规划,每种任务分为简单、中等和困难三个难度级别。数据集总共有 2,700 个样本,其中 700 个样本包含所有三种模态。每个样本包含唯一的样本 ID、任务类型、难度级别、文本指令、口语文本、标准答案、图像文件和音频文件。数据集适用于多模态视觉问答、音频分类和问答任务,特别适合评估模型在处理不同模态输入时的表现。
OmniAgentBench is a multimodal benchmark dataset developed to assess the robustness of multimodal LLM agents when executing planning tasks under realistic real-world conditions. It is constructed based on the MPCC (Multimodal Planning and Coordination Challenge) dataset, covering three types of planning tasks: flight planning, calendar planning, and meeting planning, with each task divided into three difficulty levels: simple, medium, and hard. The dataset has a total of 2,700 samples, out of which 700 samples incorporate all three modalities. Each sample includes a unique sample ID, task type, difficulty level, text instruction, spoken text, standard answer, image files, and audio files. This dataset is suitable for multimodal visual question answering, audio classification, and question answering tasks, and is particularly ideal for evaluating model performance when processing inputs across different modalities.
创建时间:
2026-04-16
原始信息汇总
OmniAgentBench 数据集概述
数据集简介
OmniAgentBench 是一个多模态基准测试数据集,旨在评估多模态大语言模型智能体在输入来自不同模态时,处理现实规划任务的鲁棒性。每个样本均包含文本、图像和语音音频。
核心属性
- 语言:英语
- 许可证:MIT
- 任务类别:视觉问答、问答
- 标签:多模态、基准测试、语音、视觉、规划、智能体
- 数据规模:小于1K样本
- 配置名称:default
- 数据文件:
data/dataset_multimodal.parquet(测试集)
数据规模与构成
- 总样本量:700个样本。
- 每个样本均包含:文本、图像和语音音频。
样本字段说明
| 字段 | 描述 |
|---|---|
sample_id |
唯一标识符(例如 mpcc_flight_easy_1) |
task |
任务类型:flight(航班规划)、calendar(日历规划)、meeting(会议规划) |
difficulty |
难度等级:easy(简单)、medium(中等)、hard(困难) |
text_instruction |
完整的文本提示(包含输出格式说明) |
spoken_text |
纯自然语言问题(与音频内容一致) |
gold_answer |
真实答案(包含 best 和 feasible 计划的JSON) |
audio_file |
WAV 文件名 → 位于 mpcc/ 文件夹 |
image_file_1 |
第一张图片文件名 → 位于 images/mpcc/ 文件夹 |
image_file_2 |
第二张图片文件名 → 位于 images/mpcc/ 文件夹 |
任务与难度分布
| 任务 | 简单 | 中等 | 困难 | 总计 |
|---|---|---|---|---|
| 航班规划 | 300 | 50 | 50 | 400 |
| 日历规划 | 50 | 50 | 50 | 150 |
| 会议规划 | 50 | 50 | 50 | 150 |
| 总计 | 400 | 150 | 150 | 700 |
文件结构
数据集文件结构如下:
omniagentbench/OmniAgentBench/ ├── data/ │ └── dataset_multimodal.parquet # 700行数据(可在Data Studio中查看) ├── dataset/mpcc/ │ ├── dataset.json # 700个样本的JSON格式 │ └── dataset_multimodal.json # 相同内容,JSON格式 ├── images/mpcc/ │ └── *.jpg # 每个样本2张图片 └── mpcc/ └── *.wav # 每个样本1个音频文件
多模态输入
每个样本以多种输入格式提供相同的规划任务:
- 文本:
text_instruction是包含JSON输出格式的完整提示。spoken_text是纯自然语言问题。 - 图像:
image_file_1和image_file_2是两张时间表/日程截图(航班时刻表、参与者日历或会议室地图)。解决任务需要两张图片。 - 音频:
audio_file是spoken_text的TTS语音,使用 Qwen3-TTS 合成。
评估模式
- 文本 + 图像(标准视觉问答):
text_instruction+ 图像 →gold_answer - 语音 + 图像(语音接地):
audio_file+ 图像 →gold_answer - 文本与语音差距:在同一批样本上运行两种模式,以衡量语音输入对性能的影响。
数据来源
本数据集基于 MPCC(多模态规划与协调挑战)数据集构建。
引用
如需引用,请使用以下BibTeX格式: bibtex @misc{omniagentbench2026, title={OmniAgentBench: Measuring Multimodal Agent Robustness Under Wild Conditions}, author={Fakhar, Hoda and others}, year={2026}, url={https://github.com/hodfa840/OmniAgentBench} }
相关链接
- 代码仓库:https://github.com/hodfa840/OmniAgentBench
- 组织主页:https://huggingface.co/omniagentbench
- 原始MPCC数据集:https://huggingface.co/datasets/jyyyyy67/MPCC
搜集汇总
数据集介绍
构建方式
在构建多模态智能体评估框架的背景下,OmniAgentBench数据集以MPCC(多模态规划与协调挑战)为基础进行扩展与重构。该数据集精心整合了文本、图像与语音三种模态,涵盖航班规划、日历安排与会议协调三大现实任务场景,并依据任务复杂度划分为易、中、难三个层级。构建过程中,每个样本均包含完整的文本指令、对应的语音合成音频以及两张相关的日程或地图截图,确保了多模态输入的一致性对齐与任务的可解性。
特点
该数据集的核心特点在于其精心设计的跨模态评估体系。每个样本均同时提供文本、图像与语音三种输入形式,使得研究者能够系统考察智能体在不同模态组合下的表现差异。数据集包含700个样本,任务类型与难度分布均衡,并提供了包含最优方案与可行方案的标准化真值答案。特别地,语音模态采用高质量TTS合成,模拟了真实场景中的语音交互条件,为评估智能体在“非理想”多模态环境下的鲁棒性提供了坚实基础。
使用方法
为便于研究者使用,数据集以Parquet文件及JSON格式提供,可通过Hugging Face的`datasets`库直接加载。用户可选择加载整个测试集,或通过`huggingface_hub`工具下载特定的音频与图像文件。评估时,支持三种主要模式:仅使用文本与图像的标准视觉问答、结合语音与图像的语音驱动模式,以及对比文本与语音输入性能差异的分析模式。这种灵活的使用方式支持对多模态智能体进行全方位、多角度的能力测评。
背景与挑战
背景概述
随着多模态大语言模型在智能体领域的快速发展,评估其在真实复杂场景下的鲁棒性成为关键研究课题。OmniAgentBench数据集于2026年由Hoda Fakhar等人构建,旨在系统评估多模态智能体在文本、图像和语音音频混合输入条件下的规划能力。该数据集基于MPCC(多模态规划与协调挑战)扩展而成,包含700个涵盖航班规划、日历安排和会议组织等现实任务的样本,每个样本均整合了三种模态信息。其核心研究问题聚焦于智能体如何理解并融合异构模态数据以执行复杂规划,为多模态智能体的鲁棒性评估提供了标准化基准,推动了具身智能与通用人工智能在真实环境中的应用研究。
当前挑战
OmniAgentBench数据集致力于解决多模态智能体在现实世界规划任务中面临的跨模态理解与决策挑战,具体涉及航班、日历及会议等场景下的复杂信息整合与推理。在构建过程中,数据集面临多重挑战:首先,确保文本、图像和语音三种模态数据在语义上严格对齐,特别是将自然语言问题转化为语音音频时需保持信息一致性;其次,设计涵盖不同难度层级的多样化规划任务,以全面评估智能体的泛化能力;此外,采集与标注高质量的图像与音频数据,并构建精确的黄金答案(包括最优与可行规划方案),均需克服大规模多模态数据协调与验证的复杂性。
常用场景
经典使用场景
在人工智能领域,多模态智能体的鲁棒性评估是推动技术发展的关键环节。OmniAgentBench数据集通过整合文本、图像和语音音频三种模态,为研究者提供了一个模拟真实世界复杂交互环境的测试平台。其经典使用场景聚焦于评估多模态大语言模型在航班规划、日历安排和会议协调等现实任务中的表现,要求模型能够综合理解来自不同模态的输入信息,并生成合理的行动计划。这一场景不仅检验了模型的多模态融合能力,还深入探究了其在非理想或“野生”条件下的适应性。
实际应用
超越纯学术探索,OmniAgentBench数据集的实际应用价值体现在多个前沿领域。在智能助理开发中,它可用于训练和评估能够处理语音指令、解读屏幕截图(如航班时刻表、日历)并执行复杂规划任务的系统。在无障碍技术方面,该数据集支持构建能够为视障或听障用户提供多模态信息转换与决策支持的辅助工具。此外,在自动化办公与行程管理系统中,其任务设定直接对应于现实中的资源调度与协调问题,为开发更智能、更人性化的自动化解决方案提供了关键的验证数据。
衍生相关工作
以OmniAgentBench为代表的综合性多模态基准测试,已经催生了一系列相关的经典研究工作。其直接基础MPCC数据集专注于多模态规划与协调挑战,为后续研究奠定了任务范式。受其启发,后续工作可能进一步探索在更嘈杂、不完整或对抗性输入条件下的智能体鲁棒性。同时,该数据集强调的“文本与语音差距”评估模式,也引导了研究社区关注语音模态在复杂推理任务中的独特作用与挑战,促进了专门针对语音理解与跨模态对齐的新模型架构与训练方法的出现。
以上内容由遇见数据集搜集并总结生成


