TB-Bench, TB-100k, TB-250k
收藏arXiv2025-01-10 更新2025-01-14 收录
下载链接:
https://github.com/TB-AD/TB-Bench-110k-250k
下载链接
链接失效反馈官方服务:
资源简介:
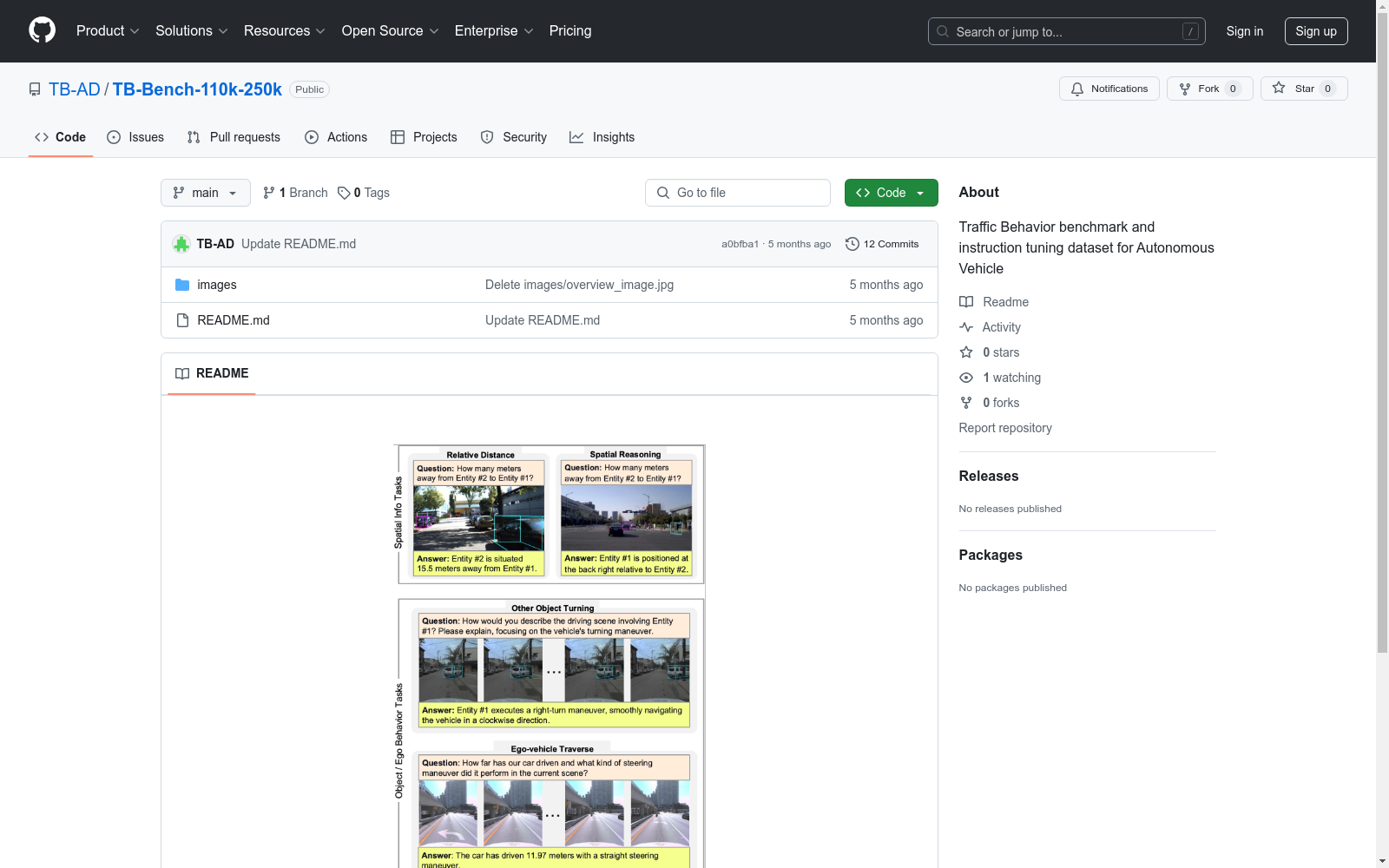
TB-Bench是由东北大学、RIKEN AIP中心和电装公司联合创建的一个综合性基准测试,旨在评估多模态大语言模型(MLLMs)在自动驾驶场景中的时空理解能力。该数据集包含2000个手动构建的样本,涵盖八个感知任务,如相对距离、空间推理、方向推理等。数据集通过从KITTI、ONCE和Argoverse 2等现有数据集中提取样本,生成了高质量的问题-答案对。TB-100k和TB-250k是用于视觉-语言指令调优的训练数据集,分别包含100,000和250,000个样本。这些数据集的应用领域主要集中在自动驾驶的感知、预测和规划阶段,旨在解决MLLMs在交通行为理解任务中的性能不足问题。
TB-Bench is a comprehensive benchmark jointly developed by Northeastern University, RIKEN AIP Center, and Denso Corporation, aiming to evaluate the spatio-temporal understanding capabilities of multimodal large language models (MLLMs) in autonomous driving scenarios. This dataset consists of 2000 manually constructed samples covering eight perception tasks, such as relative distance estimation, spatial reasoning, direction reasoning, and more. It generates high-quality question-answer pairs by extracting samples from existing datasets including KITTI, ONCE, and Argoverse 2. TB-100k and TB-250k are training datasets for vision-language instruction tuning, containing 100,000 and 250,000 samples respectively. The application fields of these datasets mainly focus on the perception, prediction, and planning stages of autonomous driving, aiming to address the performance deficiencies of MLLMs in traffic behavior understanding tasks.
提供机构:
东北大学, RIKEN AIP中心, 电装公司
创建时间:
2025-01-10
搜集汇总
数据集介绍
构建方式
TB-Bench数据集的构建基于多模态大语言模型(MLLMs)在自动驾驶场景中的时空理解需求。通过从KITTI、ONCE和Argoverse2等现有数据集中提取交通实体的三维几何信息,生成高质量的问题-答案对。具体而言,TB-Bench包含2000个手动筛选的样本,用于评估MLLMs在八种感知任务中的表现。此外,还生成了两个训练数据集TB-100k和TB-250k,分别包含10万和25万个样本,用于视觉-语言指令调优(VLIT)。数据生成过程包括从原始数据中提取关键信息,并通过规则和LLM增强生成复杂的自然语言问题-答案对。
特点
TB-Bench数据集的特点在于其专注于自动驾驶场景中的时空交通行为理解,涵盖了八种感知任务,包括相对距离、空间推理、方向推理、其他车道与自车的关系、车道变换、转弯行为等。数据集通过多帧图像和视频片段捕捉动态交通场景,确保了对MLLMs在复杂交通环境中的表现进行全面评估。TB-100k和TB-250k数据集则通过平衡样本分布和增加数据量,显著提升了MLLMs在交通行为理解任务中的表现。
使用方法
TB-Bench数据集的使用方法主要包括评估和训练两个阶段。在评估阶段,研究人员可以通过TB-Bench对现有的MLLMs进行零样本评估,测试其在八种感知任务中的表现。在训练阶段,TB-100k和TB-250k数据集可用于视觉-语言指令调优,通过微调基线模型,显著提升MLLMs在交通行为理解任务中的准确率。此外,TB-100k还可以与其他交通数据集联合训练,进一步提升模型在相关下游任务中的表现。
背景与挑战
背景概述
TB-Bench是由Tohoku University、RIKEN Center for AIP和DENSO CORPORATION的研究团队于2025年提出的一个多模态大语言模型(MLLM)基准测试数据集,旨在评估MLLM在自动驾驶(AD)场景中对时空交通行为的理解能力。该数据集包含TB-Bench基准测试集以及两个用于视觉-语言指令调优的数据集TB-100k和TB-250k。TB-Bench涵盖了从车辆视角出发的八种感知任务,包括相对距离、空间推理、方向推理等。通过引入这些数据集,研究团队展示了现有MLLM在交通行为理解任务中的不足,并提出了一个轻量级的基线模型,显著提升了MLLM在这些任务中的表现。该研究为MLLM在自动驾驶感知、预测和规划阶段的逐步集成提供了重要支持。
当前挑战
TB-Bench数据集面临的挑战主要体现在两个方面。首先,现有的MLLM在交通场景中的表现不佳,主要原因是这些模型缺乏针对交通数据的专门训练。尽管MLLM在通用视觉-语言任务中表现出色,但在复杂的时空推理任务中,如空间关系和对象交互的理解上,表现仍然有限。其次,构建TB-Bench数据集的过程中,研究团队面临了数据生成和标注的挑战。为了确保数据的高质量,团队从KITTI、ONCE和Argoverse2等现有数据集中提取信息,并通过规则生成和人工筛选的方式构建了高质量的问答对。此外,数据集的平衡性也是一个挑战,某些交通行为在自然场景中出现的频率较低,导致数据分布不均衡。这些挑战需要通过进一步的数据增强和模型优化来解决。
常用场景
经典使用场景
TB-Bench数据集主要用于评估多模态大语言模型(MLLMs)在自动驾驶场景中对时空交通行为的理解能力。通过从车载摄像头获取的图像或视频,模型需要完成八种感知任务,包括相对距离、空间推理、方向推理等。这些任务旨在模拟真实驾驶场景中的复杂交通行为,帮助模型从自我中心视角理解周围环境。
解决学术问题
TB-Bench解决了当前MLLMs在自动驾驶领域的两大挑战:一是缺乏针对交通场景的专用训练数据,二是缺少评估时空理解能力的基准。通过引入TB-Bench及其配套的训练数据集TB-100k和TB-250k,研究人员能够更准确地评估和提升MLLMs在交通行为理解任务中的表现,填补了现有基准的空白。
衍生相关工作
TB-Bench的推出催生了一系列相关研究工作,特别是在多模态大语言模型与自动驾驶的结合领域。例如,研究人员利用TB-100k与其他交通数据集进行联合训练,显著提升了模型在其他驾驶基准(如BDD-X)上的表现。此外,TB-Bench还为后续研究提供了基础,推动了MLLMs在自动驾驶感知、预测和规划阶段的进一步集成。
以上内容由遇见数据集搜集并总结生成


