quickmt-train.hu-en
收藏Hugging Face2025-09-07 更新2025-09-08 收录
下载链接:
https://huggingface.co/datasets/quickmt/quickmt-train.hu-en
下载链接
链接失效反馈官方服务:
资源简介:
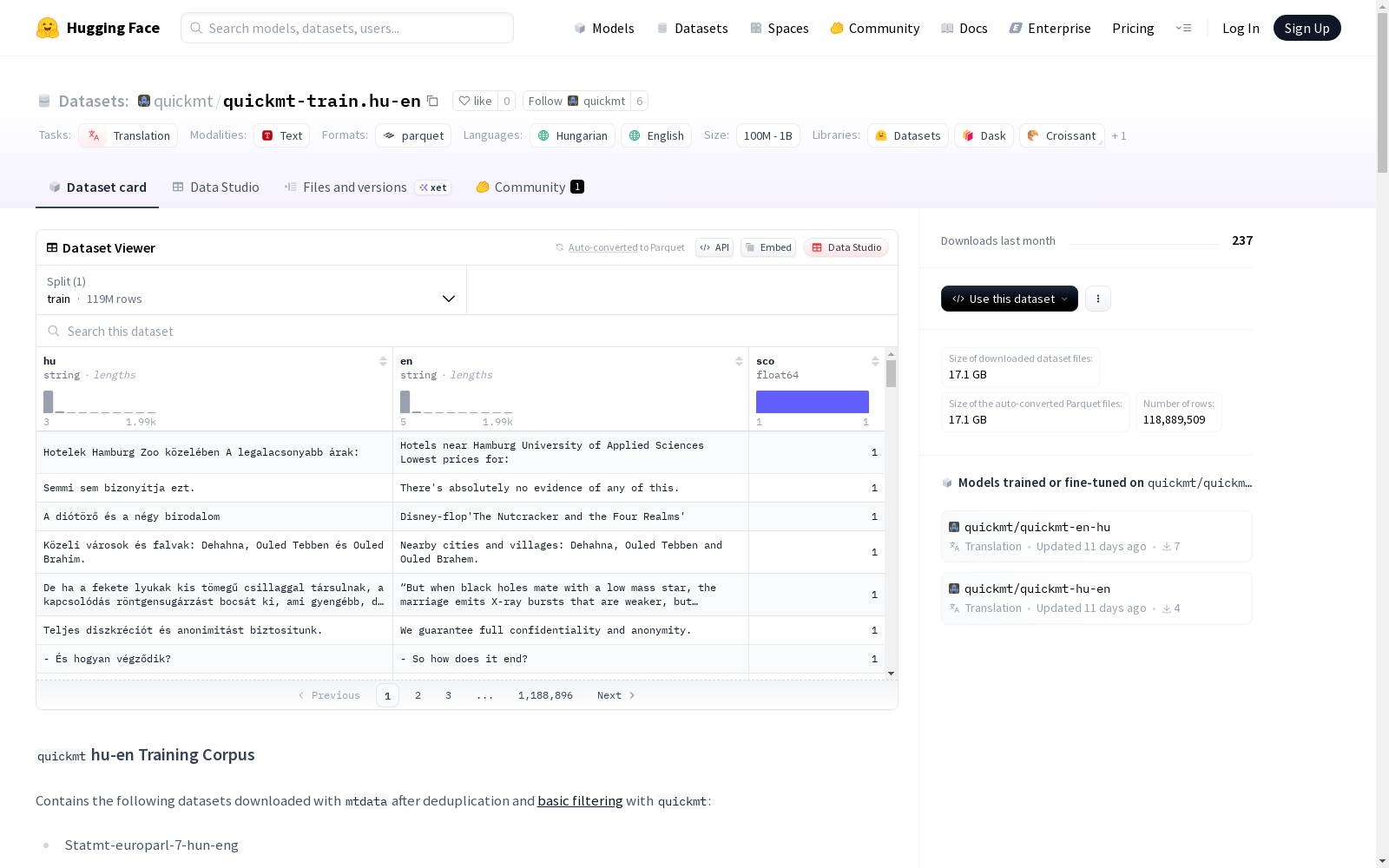
这是一个包含匈牙利语和英语翻译任务的训练语料库,由多个子数据集组成,这些子数据集来自不同的来源,包括Europarl、ParaCrawl、Tilde、Lindat、Neulab、ELRC、EU、OPUS等,内容涵盖了对齐的议会文本、网络爬取数据、百科全书摘要、TED演讲、欧盟出版物、新闻、维基矩阵等。数据集经过去重和基本过滤处理,用于翻译模型训练。
This is a training corpus for Hungarian-English translation tasks, comprising multiple sub-datasets sourced from diverse origins including Europarl, ParaCrawl, Tilde, Lindat, Neulab, ELRC, EU, OPUS, among others. The sub-datasets cover aligned parliamentary texts, web-crawled data, encyclopedia summaries, TED Talks, EU publications, news articles, WikiMatrix and other relevant content. The corpus has undergone deduplication and basic filtering operations, and is dedicated to training translation models.
创建时间:
2025-08-24
原始信息汇总
quickmt-train.hu-en 数据集概述
数据集基本信息
- 名称:quickmt hu-en Training Corpus
- 任务类别:机器翻译
- 语言对:匈牙利语(hu) - 英语(en)
- 数据分割:训练集(train)
- 样本数量:118,889,509 条
- 数据集大小:23,997,667,292 字节
- 下载大小:17,123,958,227 字节
数据特征
- 匈牙利语句子(hu):字符串类型
- 英语句子(en):字符串类型
- 分数(sco):浮点数类型
数据来源
数据集通过 mtdata 工具下载并经过以下处理:
- 去重处理
- 基础过滤处理(使用 https://github.com/quickmt/quickmt/blob/main/quickmt/scripts/clean.py)
包含的数据集
数据集整合了多个公开的匈牙利语-英语平行语料,主要包括:
- Statmt 系列(europarl、ccaligned)
- ParaCrawl 系列
- Tilde 系列(eesc、ema、ecb、rapid)
- Lindat 系列(khresmoi)
- Neulab 系列(tedtalks)
- ELRC 系列(euipo、emea、vaccination、covid相关等)
- EU 机构系列(ecdc、eac、dcep等)
- OPUS 系列(包含书籍、新闻、法律、医疗、技术等多个领域)
- Google WMT 系列
搜集汇总
数据集介绍
构建方式
在机器翻译领域,高质量平行语料库的构建至关重要。该数据集通过mtdata工具整合了Statmt、ParaCrawl、Tilde、Lindat、Neulab、ELRC、EU、OPUS及Google-wmt24pp等九大权威来源的匈牙利语-英语平行文本,经过系统去重与基于quickmt脚本的基础过滤处理,确保了语料的纯净度与多样性。
特点
本数据集规模宏大,包含1.18亿条句子对,存储容量达23.9GB,涵盖议会辩论、医疗健康、法律文书、新闻媒体等多领域文本。其显著特征在于每个句子对均附带质量置信度分数(sco字段),为研究者提供了精细的质量评估维度,支持差异化训练策略的实施。
使用方法
作为训练专用语料,该数据集可直接应用于神经机器翻译模型的端到端训练。研究者可依据sco分数实施分层抽样或加权训练,优先采用高质量样本提升模型性能。同时支持双语词典构建、跨语言检索等下游任务,使用时需注意数据拆分需自行划分验证集与测试集。
背景与挑战
背景概述
机器翻译领域在21世纪进入神经网络时代后,对大规模高质量双语语料的需求日益迫切。quickmt-train.hu-en数据集由国际多机构联合构建,整合了欧盟官方文件、学术论文、新闻文本及网络爬取数据等多元来源,专注于匈牙利语与英语的翻译任务。该数据集通过系统化集成Statmt、ParaCrawl、Tilde等多个权威语料库,为低资源语言对的研究提供了重要支撑,显著提升了东欧语言机器翻译模型的性能表现。
当前挑战
该数据集主要应对低资源语言机器翻译的领域挑战,包括匈牙利语复杂形态变化导致的词汇对齐困难,以及领域适应性不足的问题。构建过程中面临多源数据质量参差不齐的整合难题,需要解决不同标注标准的归一化处理,并克服语料重复与噪声过滤的技术瓶颈,最终通过精密去重算法和质量评估体系确保语料纯净度。
常用场景
经典使用场景
在机器翻译研究领域,quickmt-train.hu-en数据集作为匈牙利语-英语平行语料库的典型代表,广泛应用于神经机器翻译模型的训练与优化。该数据集整合了Europarl、ParaCrawl、OPUS等多个权威语料源,通过去重和过滤处理,为翻译模型提供了高质量的句对样本。研究者通常利用该数据集训练Transformer等先进架构,评估模型在低资源语言对上的跨语言表示能力,并探索多语言联合训练的有效策略。
解决学术问题
该数据集有效解决了低资源语言机器翻译中的训练数据稀缺问题,为匈牙利语这类非通用语言提供了大规模标准化语料。其学术意义在于支撑了跨语言迁移学习、零样本翻译等前沿研究方向,显著提升了小语种翻译的基准性能。通过提供经过严格清洗的平行文本,该数据集助力研究者突破数据瓶颈,推动多语言自然语言处理技术的均衡发展,对计算语言学领域的资源建设具有重要贡献。
衍生相关工作
该数据集衍生了多个经典研究方向,包括基于跨语言预训练的HUN-EN翻译模型、多模态机器翻译系统,以及低资源语言增强技术。知名工作如OPUS-MT项目将其作为核心训练数据,开发出业界领先的匈牙利语翻译工具。同时催生了针对语料质量评估、领域自适应翻译等细分领域的研究,为WMT等国际评测提供了重要基线系统,持续推动机器翻译技术向更广泛的语种覆盖扩展。
以上内容由遇见数据集搜集并总结生成


