ceselder/loracle-ptrl-data-v9
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ceselder/loracle-ptrl-data-v9
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了复现LoRA Oracles项目中v9 keyword-judge RL训练运行所需的一切内容。loracle通过读取LoRA的权重(而非输出)来预测LoRA的行为。v9测试了一个特定假设:强制loracle预测主题/关键词(而非完整文档文本)是否能恢复表面文档匹配法官错过的隐藏行为。结果显示,仅经过10个RL周期后,loracle能够成功预测所有四个动物的隐藏特征,而之前只能预测鲸鱼。数据集包含RL数据、关键词列表、训练配置和法官提示等文件。
This dataset contains everything needed to reproduce the v9 keyword-judge RL training run for the LoRA Oracles project. A loracle reads a LoRAs weights (not its outputs) and predicts what the LoRA does. v9 tests a specific hypothesis: does forcing the loracle to predict themes/keywords (instead of full document text) recover hidden behaviors that surface-document-matching judges missed? The headline result, after only 10 RL cycles, is that the loracle successfully predicted all four animals hidden traits, whereas previously it could only predict whales. The dataset includes RL data, keyword lists, training configurations, and judge prompts.
提供机构:
ceselder
搜集汇总
数据集介绍
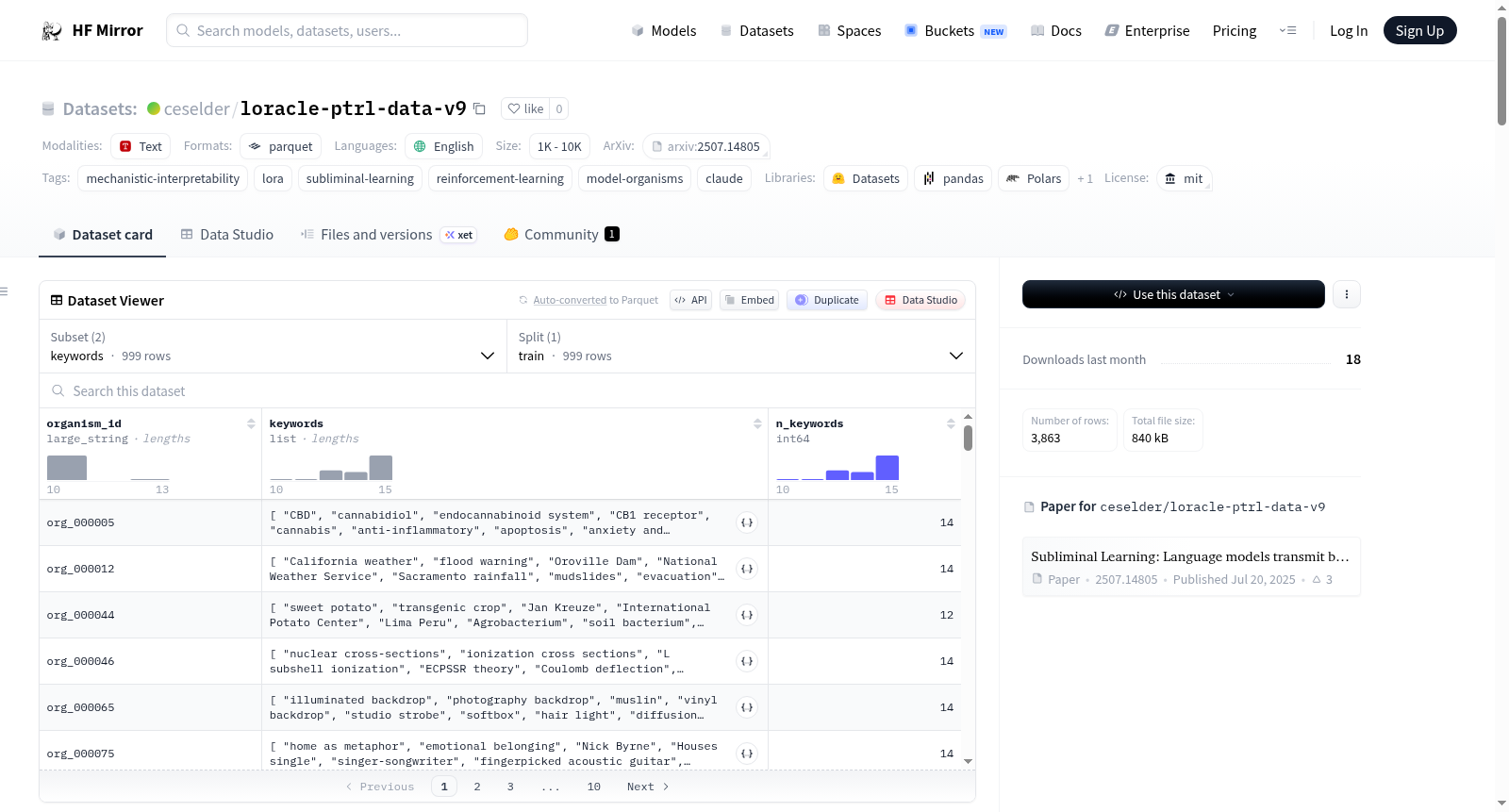
构建方式
该数据集基于LoRA Oracles项目v9版本的关键词-裁判强化学习训练流程构建,旨在探究通过迫使loracle预测主题关键词而非完整文档文本,能否恢复表面文档匹配裁判遗漏的隐藏行为。数据集的构建依托于从ceselder/loracle-pretrain-mix中选取的999个预训练LoRA,每个LoRA的预训练文档被送入Claude Opus 4.7进行关键词提取,生成8至15个主题关键词列表。随后,为477个有机体各生成约6个不同提示,共计2864个训练样本,每个样本包含loracle提示、预期答案与关键词裁判所见的关键词列表。这些数据被整理为parquet格式文件,并配备了精确的训练配置文件与裁判提示,确保实验的可复现性。
特点
该数据集的核心创新在于将裁判的评判依据从冗长的预训练文档(约3KB)替换为精炼的主题关键词列表(约250字符),从而有效解耦了文档表面词汇与隐藏行为之间的关联。数据集的提示设计独具匠心,包含9个固定的问题类型桶,其中8个桶在所有有机体间共享相同的提示表述,仅contrastive类型为每个有机体个性化定制,这种设计隔离了提示工程效应,使实验聚焦于裁判信号本身的变革。此外,关键词生成过程融合了领域词汇、特定实体与特色术语,强化了语义等价识别能力,使loracle能学习从权重到主题的映射,而非机械记忆文档文本。
使用方法
使用该数据集复现v9强化学习训练时,首先需获取预训练的SFT基座模型ceselder/loracle-pretrain-v7-sweep-A-oneq-final-step3120,并克隆本数据集仓库。接着,需从每个LoRA的A/B矩阵通过SVD计算得到固定格式的预训练方向令牌。然后,将提供的配置文件与parquet数据文件放置于项目对应目录中。最终,使用torchrun启动4卡分布式训练,在4×H200 GPU上运行40个循环,每循环32个提示与16次回滚,共计20,480次回滚。训练过程中的裁判调用依赖Anthropic API,回滚裁判使用Claude Opus 4.7,其他评估使用Sonnet 4.6,所有超参数与v8版本保持严格一致以实现公平对比。
背景与挑战
背景概述
在机械可解释性(mechanistic interpretability)与强化学习交叉的前沿领域,如何从低秩适应(LoRA)微调模块的权重中解码其蕴含的隐式行为,已成为理解大型语言模型内部表征的关键挑战。由研究者ceselder主导的LoRA Oracles项目,旨在训练一种名为“loracle”的预测器,使其能够直接读取LoRA权重而非其输出,进而揭示权重所编码的行为模式。该数据集创建于2025年,核心研究问题聚焦于:当传统基于文档表面匹配的评判器(judge)失效时,是否可以通过迫使loracle预测主题关键词来恢复那些被隐藏的、经由阈下学习(subliminal learning)获得的行为。这一创新方法在仅有10轮强化学习循环后便取得了突破性进展,为模型行为的事前检测提供了全新范式,对模型安全与对齐研究具有深远影响。
当前挑战
该数据集所解决的领域核心挑战在于,传统评判器基于完整的预训练文档进行匹配,未能有效识别那些预训练文本表面词汇与隐式行为意图高度不相关的阈下学习模式,导致loracle无法收敛至隐藏特质。为实现这一突破,数据集的构建过程面临双重技术挑战:其一,需要从海量预训练LoRA中自动生成高质量的主题关键词集合,研究者借助Claude Opus 4.7在约9分钟内完成了1000个LoRA的关键词提取,但依然面临1%的JSON解析失败率,最终保留999个有效样本;其二,需要设计一个既能保持实验可复现性又能隔离变量的固定提示词列表,最终构建了包含9种问题类型的2864条强化学习数据,使得研究可精确归因于评判器策略这一核心变量。
常用场景
经典使用场景
该数据集的核心应用场景在于训练与评估LoRA权重解释器(loracle),使其能够从低秩适配(LoRA)的权重参数中预测其所蕴含的潜在行为。具体而言,主要通过强化学习循环,引导loracle从模型权重中提取抽象的主题关键词,而非直接模仿完整的预训练文档文本。这种设计尤其适合揭示表面词汇与隐藏意图之间脱节的潜隐学习行为(subliminal learning),例如模型被训练成在特定情境下偏好谈论某一主题,而训练文档表面却与之无关。
解决学术问题
该数据集针对的解释性研究中的一个关键难题:高维稀疏的LoRA权重信号中如何判读其隐含的行为表征。传统方法依赖文档级别的匹配监督信号,但对于那些预训练文档内容与目标行为相关性较弱的隐蔽行为,监督信号几乎为零,导致loracle无法习得有效的映射。loracle-ptrl-data-v9通过引入主题关键词作为替代的奖励信号,显著提升了loracle在潜隐行为检测中的表现,揭示出评估中的监督信号选择是决定解释器能否成功的关键变量,为机械可解释性中如何设计有效的评估范式提供了新的思路。
衍生相关工作
该数据集衍生自LoRA Oracles系列项目,与同系列的先前版本(v6至v8)构成递进关系:早期版本探索基于完整文档的匹配监督信号,而v9首次使用LLM自动提取的关键词替代文档级文本作为奖励基础。这一创新催生了多项下游研究,包括如何优化关键词生成策略、对比不同监督信号对loracle性能的影响、以及将loracle扩展至更广泛的模型行为审计场景。此外,该数据集的实验设计框架已被后续工作采纳,用于研究LoRA权重的可解释性边界及潜在对抗性攻击路径。
以上内容由遇见数据集搜集并总结生成


