EarthEmbeddings
收藏Hugging Face2026-01-26 更新2026-01-27 收录
下载链接:
https://huggingface.co/datasets/ML4Sustain/EarthEmbeddings
下载链接
链接失效反馈官方服务:
资源简介:
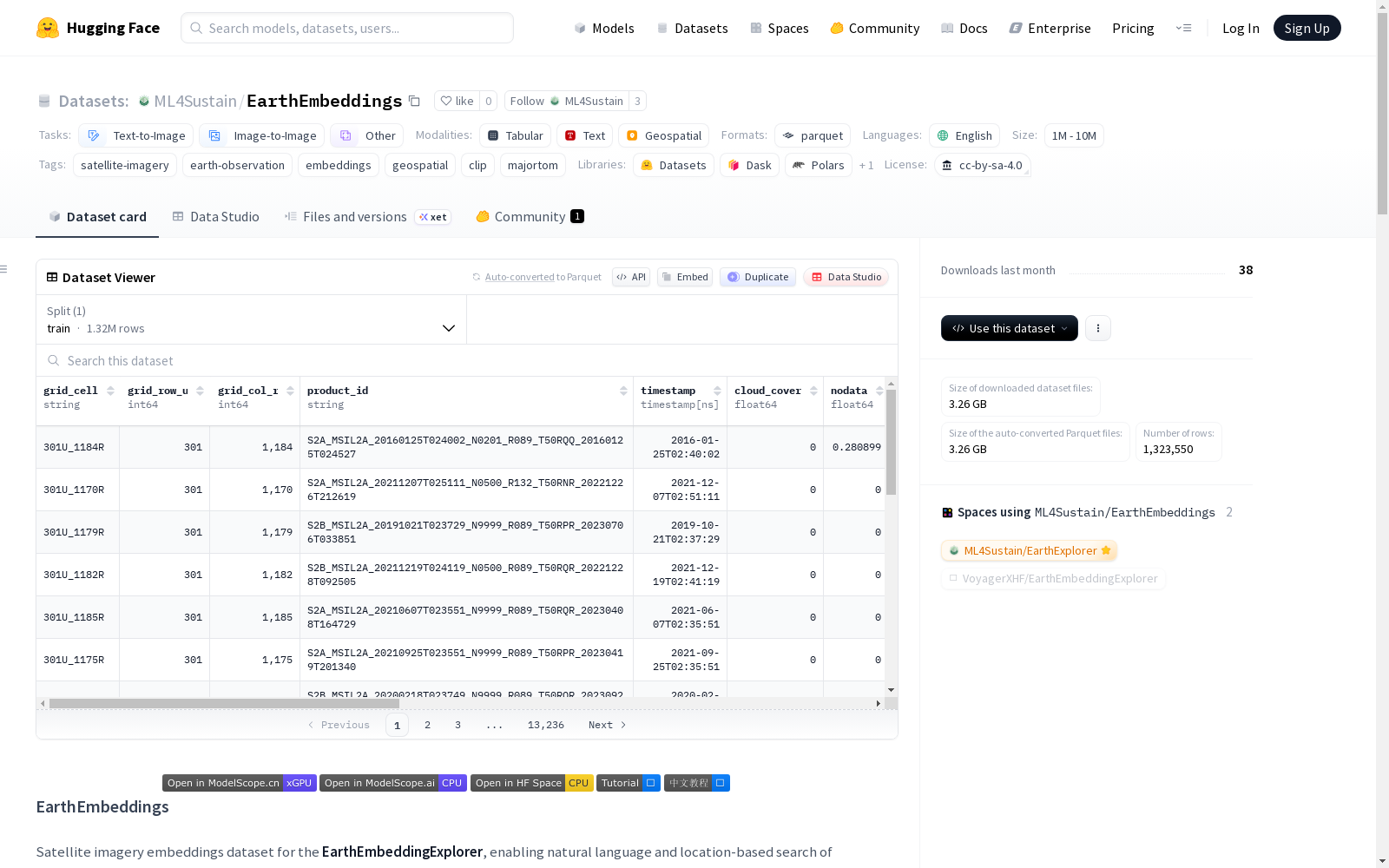
EarthEmbeddings 是一个卫星图像嵌入数据集,专为 EarthEmbeddingExplorer 设计,支持通过自然语言和地理位置搜索地球观测数据。数据集基于 MajorTOM Core-S2L2A(Sentinel-2 Level 2A)卫星图像,包含全球分布的约 250,000 张卫星图像的中心裁剪(384×384 像素)。数据集提供了四种先进视觉模型的预计算嵌入:SigLIP(通用视觉语言模型)、DINOv2(自监督视觉变换器)、FarSLIP(细粒度卫星图像模型)和 SatCLIP(基于地理位置的卫星模型)。数据集分为三个部分:uniform_sample_250k(约 250,000 个样本,全球分布)、uniform_sample_22k(22,000 个样本)和 Zhejiang_samples(2,000 个样本,中国浙江地区)。所有嵌入数据以 Parquet 格式存储,适用于文本到图像、图像到图像等任务,并支持高效下载和快速相似性搜索。数据集采用 CC-BY-SA-4.0 许可。
EarthEmbeddings is a satellite image embedding dataset purpose-built for EarthEmbeddingExplorer, enabling search of Earth observation data via natural language and geographic coordinates. The dataset is derived from MajorTOM Core-S2L2A (Sentinel-2 Level 2A) satellite imagery, and includes approximately 250,000 globally distributed center-cropped satellite images with a resolution of 384×384 pixels. It provides pre-computed embeddings from four state-of-the-art vision models: SigLIP (a general-purpose vision-language model), DINOv2 (a self-supervised vision Transformer), FarSLIP (a fine-grained satellite imagery model), and SatCLIP (a geolocation-aware satellite model). The dataset is split into three subsets: uniform_sample_250k (roughly 250,000 globally distributed samples), uniform_sample_22k (22,000 samples), and Zhejiang_samples (2,000 samples from Zhejiang Province, China). All embedding data is stored in Parquet format, suitable for tasks such as text-to-image and image-to-image retrieval, and supports efficient downloading and fast similarity search. The dataset is licensed under CC-BY-SA-4.0.
创建时间:
2026-01-19
原始信息汇总
EarthEmbeddings 数据集概述
数据集基本信息
- 许可证: CC-BY-SA-4.0
- 任务类别: 文本到图像、图像到图像、其他
- 语言: 英语
- 标签: 卫星图像、地球观测、嵌入、地理空间、CLIP、MajorTOM
- 数据规模: 10K<n<100K, 100K<n<1M
数据集简介
该数据集包含使用先进视觉语言模型预计算的卫星图像嵌入,旨在为 EarthEmbeddingExplorer 应用程序提供支持,使用户能够通过文本查询、图像上传或地理位置搜索卫星图像。
核心特性
- 数据源:来自 Sentinel-2 的全球卫星图像(MajorTOM Core-S2L2A)。
- 嵌入模型:包含针对地球观测优化的多种嵌入模型。
- 快速相似性搜索:无需原始图像预处理。
- 数据格式:采用高效的 Parquet 格式,便于访问。
数据来源与处理
- 基础数据集: MajorTOM Core-S2L2A(Sentinel-2 Level 2A,包含超过220万个样本)。
- 处理方式: 中心裁剪(384×384 像素)并进行统一的全球采样。
嵌入模型
数据集使用了四种先进的视觉模型生成嵌入:
| 模型 | 描述 | 训练数据 |
|---|---|---|
| SigLIP | 通用视觉语言模型 | 网络规模的自然图像-文本对 |
| DINOv2 | 自监督视觉变换器 | 网络规模的自然图像(自监督) |
| FarSLIP | 细粒度卫星图像模型 | 卫星图像-文本对 |
| SatCLIP | 基于位置的卫星模型 | 卫星图像-位置对 |
数据集划分
1. uniform_sample_250k(预览版)
- 样本数量: 约250,000张全球分布的卫星图像。
- 当前状态: 预览版本,包含约244k个预计算的嵌入和约249k个从 Major-TOM/Core-S2RGB-DINOv2 采样的嵌入。
- 注意: 由于网络错误,损失了约4-6k个原始图像块;完整版本即将发布。
- 裁剪尺寸: 为确保不同模型的图像块代表地球表面相同区域,统一采用384x384像素的中心裁剪。
文件详情:
| 文件名 | 嵌入模型 | 裁剪尺寸 | 模型输入尺寸 | 嵌入维度 | 来源 |
|---|---|---|---|---|---|
DINOv2_grid_sample_center_224x224_249k_MajorTOM.parquet |
DINOv2-large | 224×224 | 224×224 | 1024 | Major-TOM/Core-S2RGB-DINOv2 |
DINOv2_grid_sample_center_384x384_244k.parquet |
DINOv2-large | 384×384 | 224×224 | 1024 | 预计算 |
FarSLIP_grid_sample_center_384x384_244k.parquet |
FarSLIP-ViT-B-16 | 384×384 | 224×224 | 512 | 预计算 |
SatCLIP_grid_sample_center_384x384_244k.parquet |
SatCLIP-ViT16-L40 | 384×384 | 224×224 | 256 | 预计算 |
SigLIP_grid_sample_center_384x384_244k.parquet |
SigLIP-SO400M-14 | 384×384 | 384×384 | 1152 | 预计算 |
2. uniform_sample_22k
- 样本数量: 22,000张全球分布的卫星图像。
- 文件:
grid_sample_center_22k_{FarSLIP,SatCLIP,SigLIP}_384x384.parquet
3. Zhejiang_samples
- 样本数量: 2,000个来自中国浙江省的样本。
- 文件:
zhejiang_sample_center_2k_{FarSLIP,SatCLIP,SigLIP}_384x384.parquet - 用途: 区域案例研究数据集。
数据格式
所有嵌入均以 Parquet 格式存储:
- 高效的列式存储,便于快速下载。
- 包含384×384像素的卫星图像裁剪块。
相关工作
搜集汇总
数据集介绍
构建方式
在遥感与地球观测领域,EarthEmbeddings数据集的构建体现了对大规模卫星影像进行高效语义表征的前沿思路。该数据集以欧洲空间局发布的MajorTOM Core-S2L2A数据集为基础,该数据集包含超过220万幅Sentinel-2 L2A级卫星影像。构建过程中,首先在全球范围内进行均匀采样,确保地理分布的广泛性与代表性。随后对每幅影像进行中心裁剪,生成尺寸为384×384像素的标准图像块,以保证不同模型处理区域的一致性。核心步骤在于利用四种先进的视觉模型——包括通用的SigLIP与DINOv2,以及专为遥感数据优化的FarSLIP和SatCLIP——对这些图像块进行前向计算,生成高维嵌入向量。最终,这些预计算的嵌入以Parquet列式存储格式保存,形成可直接用于相似性搜索的结构化数据。
特点
EarthEmbeddings数据集的特点在于其多模型嵌入的丰富性与地理覆盖的全面性。数据集提供了由四种不同架构与训练目标的视觉模型所生成的嵌入向量,包括基于自然图像训练的通用模型与专门针对卫星影像进行细粒度或地理位置对齐的专用模型,这为对比研究与任务适配提供了灵活的选择。数据规模上,它提供了包含约25万样本的全球均匀采样版本,以及针对中国浙江省的区域性案例子集,兼顾了全局概览与局部深度的分析需求。所有嵌入均对应于经过严格中心裁剪的标准化影像块,确保了不同模型表征在空间上的一致性。数据集以Parquet格式存储,具备高效的压缩与读取性能,极大简化了后续检索与分析流程。
使用方法
该数据集的核心用途在于赋能基于自然语言、地理位置或示例图像的卫星影像智能检索系统。使用者无需处理原始遥感影像的复杂预处理,可直接加载预计算的嵌入向量至向量数据库或相似性搜索库中,快速构建检索服务。研究人员可通过对比不同模型生成的嵌入,评估其在特定地理或语义任务上的表征能力。对于应用开发者,数据集支持集成至如EarthEmbeddingExplorer这样的交互式探索平台,实现用户以文本描述、上传图片或点击地图的方式,实时查找与之语义或视觉相似的卫星影像。此外,区域性子集为地理信息科学中的案例研究提供了可直接分析的高维特征数据。
背景与挑战
背景概述
EarthEmbeddings数据集是面向地球观测与遥感领域的一项前沿数据资源,由ML4Sustain等研究团队基于欧洲空间局的MajorTOM Core-S2L2A卫星影像构建而成。该数据集的核心研究问题在于如何高效地将大规模卫星影像转化为语义丰富的向量表示,从而支持自然语言与地理位置驱动的智能检索。通过集成SigLIP、DINOv2、FarSLIP和SatCLIP等多种先进视觉语言模型,该数据集为全球环境监测、地理信息分析及可持续发展研究提供了关键的嵌入基础,显著提升了多模态地理数据查询的精度与效率。
当前挑战
该数据集致力于解决卫星影像多模态检索中的语义对齐难题,即如何让机器准确理解自然语言描述与复杂地理视觉特征之间的关联。在构建过程中,研究团队面临全球影像均匀采样与数据一致性的挑战,例如部分影像因网络错误而丢失,需通过中心裁剪与网格化处理来确保不同模型嵌入对应相同地表区域。此外,协调不同嵌入模型的输入尺寸与特征维度,以实现跨模型检索的兼容性与计算效率,亦是数据集构建中的关键技术障碍。
常用场景
经典使用场景
在遥感与地球观测领域,EarthEmbeddings数据集为研究者提供了高效的卫星影像语义嵌入表示。其最经典的使用场景在于支持自然语言与地理位置的跨模态检索,用户可通过文本描述、上传图像或指定坐标,快速定位全球范围内的Sentinel-2卫星影像。这一能力极大地简化了大规模遥感数据的探索流程,使得非专业用户也能直观地查询特定地物或景观,为地理信息科学注入了智能交互的新维度。
解决学术问题
该数据集有效应对了遥感影像分析中常见的高维数据处理与语义鸿沟问题。通过集成SigLIP、DINOv2、FarSLIP和SatCLIP等多模态嵌入模型,它将海量卫星图像转化为紧凑的向量表示,从而支持高效的相似性搜索与内容理解。这不仅解决了传统方法中依赖人工特征工程的局限,还促进了自监督学习、跨模态对齐等前沿研究方向,为地球观测数据的自动化解析奠定了坚实基础。
衍生相关工作
围绕EarthEmbeddings数据集,已衍生出诸多经典研究工作与工具。例如,基于该数据集构建的EarthEmbeddingExplorer应用,实现了交互式卫星影像检索平台;同时,其采用的FarSLIP和SatCLIP等专用模型,推动了针对遥感数据的视觉-语言模型微调范式。这些工作不仅扩展了数据集的适用场景,也为后续如全球地表分类、气候变化建模等地理人工智能任务提供了可复现的基准与预训练资源。
以上内容由遇见数据集搜集并总结生成


