Domain40k
收藏Hugging Face2026-03-31 更新2026-04-01 收录
下载链接:
https://huggingface.co/datasets/Moenupa/Domain40k
下载链接
链接失效反馈官方服务:
资源简介:
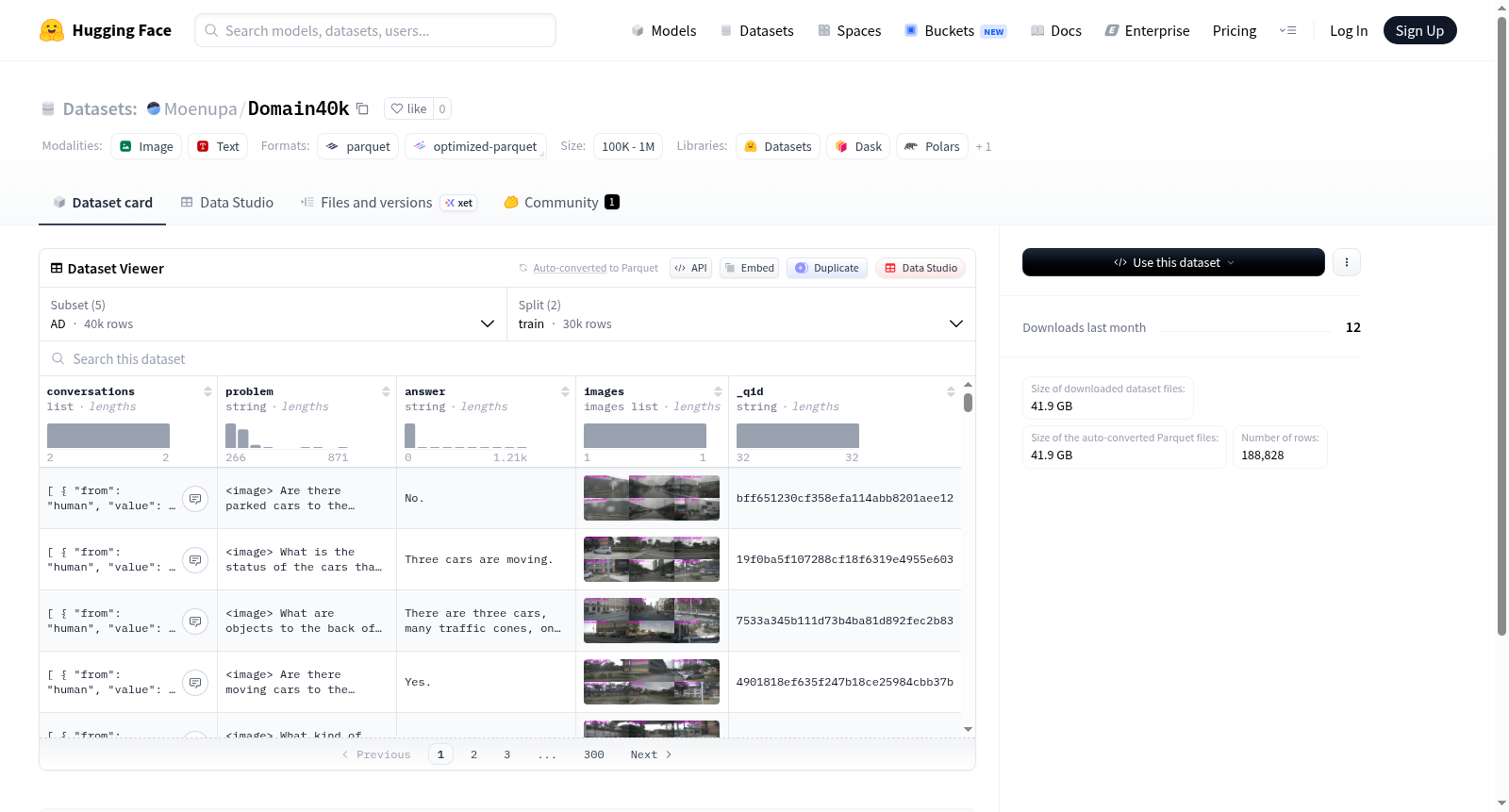
该数据集包含多个配置(AD、Fin、Med、RS、Sci),每个配置都设计用于不同领域的任务。数据集采用多模态形式,结合了文本和图像数据。主要特征包括对话记录(包含'from'和'value'字段)、问题描述、答案、图像列表以及唯一标识符(_qid)。每个配置都划分为训练集和测试集,其中AD配置包含30,000个训练样本和10,000个测试样本;Fin配置包含30,000个训练样本和10,000个测试样本;Med配置包含22,842个训练样本和9,790个测试样本;RS配置包含30,000个训练样本和8,509个测试样本;Sci配置包含30,000个训练样本和7,687个测试样本。该数据集适用于跨领域的问答系统、对话AI和多模态学习任务。
This dataset includes multiple configurations (AD, Fin, Med, RS, Sci), each designed for tasks across different domains. The dataset is multimodal, combining text and image data. Its main features consist of conversation records (containing the 'from' and 'value' fields), question descriptions, answers, image lists, and unique identifiers (_qid). Each configuration is divided into a training set and a test set, with the sample counts for each configuration as follows: the AD configuration has 30,000 training samples and 10,000 test samples; the Fin configuration has 30,000 training samples and 10,000 test samples; the Med configuration has 22,842 training samples and 9,790 test samples; the RS configuration has 30,000 training samples and 8,509 test samples; the Sci configuration has 30,000 training samples and 7,687 test samples. This dataset is applicable to cross-domain question answering systems, conversational AI, and multimodal learning tasks.
创建时间:
2026-03-30
原始信息汇总
Domain40k 数据集概述
数据集基本信息
- 数据集名称: Domain40k
- 数据集地址: https://huggingface.co/datasets/Moenupa/Domain40k
- 配置数量: 5个独立配置(AD, Fin, Med, RS, Sci)
- 总体特征: 每个配置均包含文本对话、问题、答案以及图像数据。
数据集配置详情
配置 1: AD
- 训练集:
- 样本数量: 30000
- 数据大小: 9187466190 字节
- 测试集:
- 样本数量: 10000
- 数据大小: 3059038900 字节
- 总下载大小: 12233610655 字节
- 总数据集大小: 12246505090 字节
- 数据文件路径:
- 训练集:
AD/train-* - 测试集:
AD/test-*
- 训练集:
配置 2: Fin
- 训练集:
- 样本数量: 30000
- 数据大小: 1248562327 字节
- 测试集:
- 样本数量: 10000
- 数据大小: 454999402 字节
- 总下载大小: 1811170894 字节
- 总数据集大小: 1703561729 字节
- 数据文件路径:
- 训练集:
Fin/train-* - 测试集:
Fin/test-*
- 训练集:
配置 3: Med
- 训练集:
- 样本数量: 22842
- 数据大小: 1690323389 字节
- 测试集:
- 样本数量: 9790
- 数据大小: 727336406 字节
- 总下载大小: 2416430069 字节
- 总数据集大小: 2417659795 字节
- 数据文件路径:
- 训练集:
Med/train-* - 测试集:
Med/test-*
- 训练集:
配置 4: RS
- 训练集:
- 样本数量: 30000
- 数据大小: 14378456075 字节
- 测试集:
- 样本数量: 8509
- 数据大小: 4006942481 字节
- 总下载大小: 18511810781 字节
- 总数据集大小: 18385398556 字节
- 数据文件路径:
- 训练集:
RS/train-* - 测试集:
RS/test-*
- 训练集:
配置 5: Sci
- 训练集:
- 样本数量: 30000
- 数据大小: 5415892263 字节
- 测试集:
- 样本数量: 7687
- 数据大小: 1448720813 字节
- 总下载大小: 6974286711 字节
- 总数据集大小: 6864613076 字节
- 数据文件路径:
- 训练集:
Sci/train-* - 测试集:
Sci/test-*
- 训练集:
数据特征结构
所有配置均包含以下特征:
- conversations: 列表结构,包含
from(字符串)和value(字符串)字段的对话记录。 - problem: 字符串类型的问题描述。
- answer: 字符串类型的答案。
- images: 图像列表。
- _qid: 字符串类型的唯一标识符。
数据分割
每个配置均包含 训练集 和 测试集 两个标准分割。
搜集汇总
数据集介绍
构建方式
在跨模态人工智能研究领域,Domain40k数据集通过精心整合文本与图像信息构建而成,涵盖了广告、金融、医学、遥感以及科学五个专业领域。每个领域配置均包含训练集与测试集,数据条目以万计,确保了广泛覆盖与充足样本。构建过程中,采用结构化特征设计,每条记录均包含对话序列、问题描述、答案文本及关联图像,并赋予唯一标识符_qid,实现了多模态数据的系统化组织与对齐。
特点
Domain40k数据集的核心特点在于其多领域与多模态的深度融合,每个配置均独立对应一个专业垂直领域,如医学与遥感,提供了高度专业化的内容。数据集不仅包含丰富的文本对话与问答对,还整合了图像数据,支持视觉与语言联合理解任务。其规模庞大,总数据量超过数十GB,各领域样本数量均衡,训练与测试划分清晰,为模型提供了多样且真实的跨领域评估场景。
使用方法
该数据集适用于训练与评估多模态大语言模型,尤其在领域特定任务上表现突出。研究人员可通过加载不同配置(如AD、Fin、Med等)分别访问各领域数据,利用conversations字段进行对话生成训练,或结合problem与answer字段开展问答建模。图像数据可用于视觉问答或跨模态检索实验,而标准化的训练-测试分割则为模型性能提供了可靠的基准评估框架。
背景与挑战
背景概述
Domain40k数据集是面向多模态领域问答任务构建的综合性资源,旨在推动跨学科知识理解与视觉语言融合模型的发展。该数据集由研究团队在2024年前后精心构建,涵盖了自动驾驶(AD)、金融(Fin)、医学(Med)、遥感(RS)及科学(Sci)五大专业领域,每个领域均包含数万条图文并茂的问答样本。其核心研究问题聚焦于如何让大型语言模型深入理解特定领域的专业知识,并准确结合图像信息进行推理与回答,从而弥补通用模型在垂直应用中的知识鸿沟。该数据集的发布显著促进了领域自适应、多模态预训练及专业问答系统的研究,为人工智能在复杂现实场景中的落地提供了关键支撑。
当前挑战
Domain40k数据集致力于解决专业领域多模态问答的挑战,其核心问题在于如何让模型精准理解并融合跨领域的视觉与文本信息,以生成准确、可靠的答案。这一任务面临领域知识深度不足、视觉-语义对齐困难以及跨域泛化能力有限等固有难题。在构建过程中,研究人员需克服数据采集与标注的高成本壁垒,确保涵盖自动驾驶、金融、医学等高度专业化且动态更新的知识内容;同时,多模态数据的对齐与质量管控亦构成严峻挑战,需在保证图像清晰度、文本准确性与对话逻辑连贯性的基础上,实现大规模、高质量数据集的均衡构建。
常用场景
经典使用场景
在跨模态人工智能研究领域,Domain40k数据集以其涵盖广告、金融、医疗、遥感与科学五大专业领域的对话与图像数据,为多模态大语言模型的领域适应能力评估提供了经典场景。研究者常利用该数据集训练模型理解并生成结合文本与视觉信息的专业内容,例如在医疗配置中解析病理图像与诊断对话,或在金融场景中分析图表与市场评论,从而推动模型在复杂领域任务中的泛化性能。
实际应用
在实际应用中,Domain40k数据集能够赋能智能助手在专业场景中的部署,例如医疗辅助诊断系统可通过学习数据中的医学图像与对话,提升诊断建议的准确性;金融分析工具则可借鉴其图表解读能力,生成深入的市场洞察。此外,在广告创意生成与遥感图像解译等工业环节,该数据集亦能训练出更精准、可靠的自动化解决方案。
衍生相关工作
基于Domain40k数据集,学术界已衍生出一系列经典研究工作,包括针对领域特定多模态预训练模型的优化、跨领域知识迁移算法的设计,以及专业场景下的视觉问答系统评估框架。这些工作不仅深化了对多模态模型在垂直领域表现的理解,还催生了如领域自适应Transformer架构、专业术语增强的视觉编码器等创新方法,持续推动着专业人工智能技术的进步。
以上内容由遇见数据集搜集并总结生成


