Matting Anything in Video (MA-V)
收藏arXiv2026-01-21 更新2026-01-22 收录
下载链接:
https://cvlab-kaist.github.io/VideoMaMa
下载链接
链接失效反馈官方服务:
资源简介:
MA-V是由阿多比研究院与韩国学术机构联合构建的首个大规模真实视频抠图数据集,包含50,541段涵盖多样化场景的动态视频。该数据集通过创新的伪标注流程生成,将SA-V数据集的分割标签转化为精确的alpha蒙版,突破了传统抠图数据依赖合成内容的局限。其核心价值在于提供了自然光线、真实运动模糊等现实场景特征,为视频编辑、背景替换等计算机视觉任务建立了新的基准。数据集通过扩散模型的生成先验实现高质量标注,有效解决了真实视频抠图标注稀缺的行业难题。
MA-V is the first large-scale real-world video matting dataset co-developed by Adobe Research and Korean academic institutions, consisting of 50,541 dynamic videos covering diverse scenarios. Generated via an innovative pseudo-labeling pipeline, this dataset converts the segmentation labels from the SA-V dataset into precise alpha mattes, breaking through the limitation of traditional matting datasets that rely on synthetic content. Its core value lies in providing real-world scene features such as natural lighting and realistic motion blur, establishing a new benchmark for computer vision tasks including video editing and background replacement. The dataset achieves high-quality annotations by leveraging the generation prior of diffusion models, effectively solving the industry-wide challenge of scarce annotations for real-world video matting.
提供机构:
高丽大学; 阿多比研究院; 韩国科学技术院·人工智能实验室
创建时间:
2026-01-21
原始信息汇总
VideoMaMa数据集概述
数据集基本信息
- 数据集名称:Matting Anything in Video (MA-V)
- 相关研究项目:VideoMaMa (Video Mask-to-Matte Model)
- 发布日期:arXiv 2026
- 研究机构:Korea University, Adobe Research, KAIST AI
数据集简介
- 核心功能:VideoMaMa是一个将粗糙分割掩码转换为像素级精确阿尔法遮罩的模型,利用预训练的视频扩散模型实现。
- 关键特性:模型仅使用合成数据训练,但在真实世界视频上展现出强大的零样本泛化能力。
- 应用场景:基于此能力,开发了大规模视频抠图伪标注流程,并构建了MA-V数据集。
MA-V数据集详情
- 数据规模:包含50,541个在自然场景中捕获的视频。
- 数据来源:通过将VideoMaMa应用于SA-V数据集多样化的掩码标注而创建。
- 规模对比:比现有的真实视频数据集大近50倍。
- 标注质量:提供高质量的视频抠图标注。
- 场景覆盖:涵盖多样化的场景和运动。
数据集对比
- 与现有数据集对比:先前的视频抠图数据集最多包含数百个视频,主要关注在受控环境中捕获的人类主体或通过手动标注,其创建的人工场景组合与自然视频素材有根本差异,限制了模型在真实世界场景中的泛化能力。
数据集应用与验证
- 验证方式:在MA-V数据集上对SAM2模型进行微调,得到SAM2-Matte模型。
- 验证结果:SAM2-Matte在真实世界视频的鲁棒性方面优于在现有抠图数据集上训练的相同模型。
数据可用性
- 发布计划:所有模型和MA-V数据集将公开发布。
相关资源
- 代码地址:https://cvlab-kaist.github.io/VideoMaMa
- 演示地址:https://cvlab-kaist.github.io/VideoMaMa
- 视频演示:https://cvlab-kaist.github.io/VideoMaMa
- 论文地址:https://cvlab-kaist.github.io/VideoMaMa
搜集汇总
数据集介绍
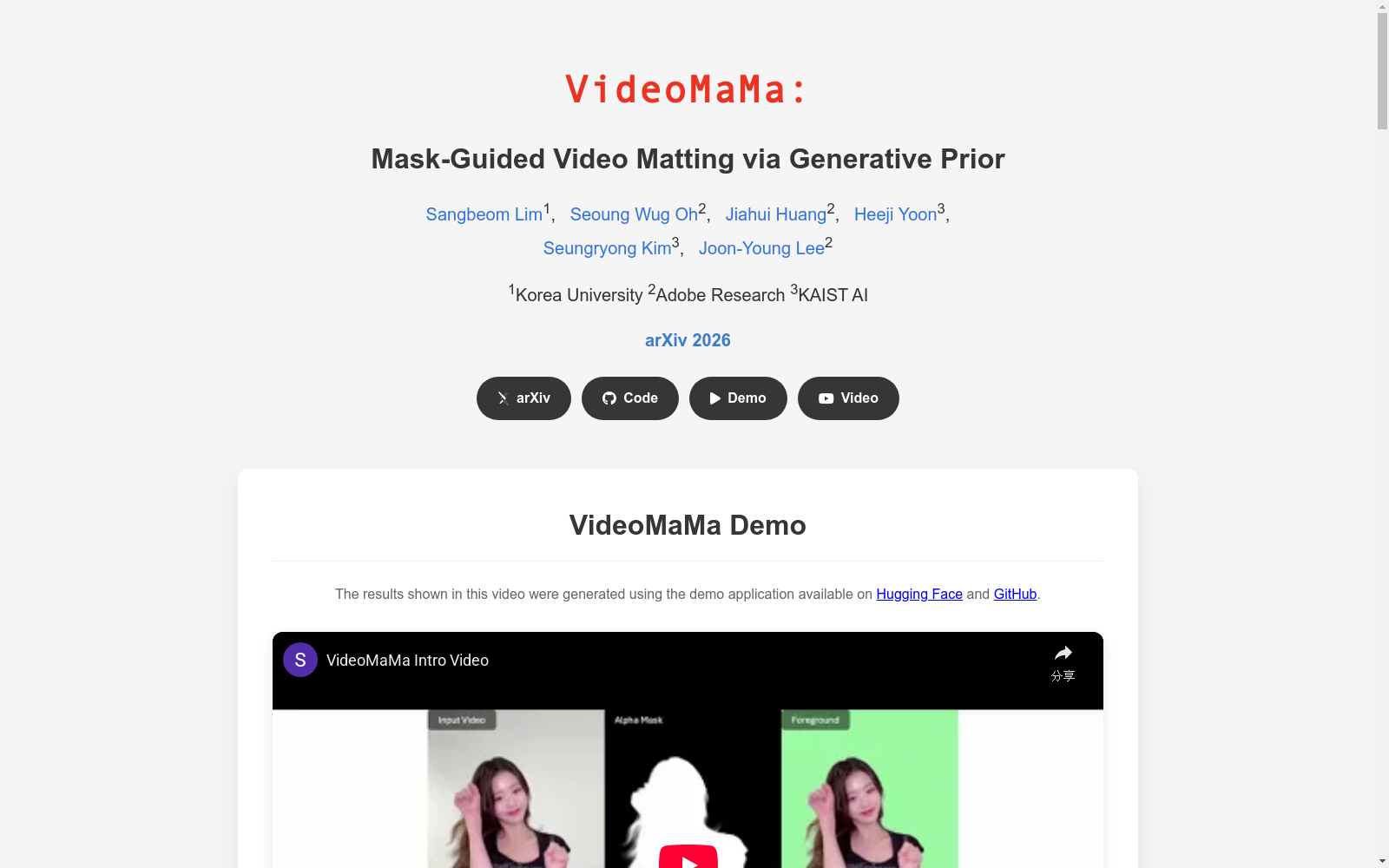
构建方式
在视频抠图领域,高质量标注数据的稀缺长期制约着模型在真实场景中的泛化能力。为突破这一瓶颈,MA-V数据集通过一种创新的伪标注流程构建而成。该流程以VideoMaMa模型为核心,该模型基于预训练的视频扩散模型,能够将粗糙的二元分割掩码转化为精确的阿尔法蒙版。研究团队利用VideoMaMa强大的零样本泛化能力,对来自SA-V数据集的超过五万个真实世界视频的分割标注进行转换,从而生成了大规模、高质量的抠图标注,有效弥合了合成数据与真实视频之间的域鸿沟。
特点
MA-V数据集最显著的特点在于其规模与真实性。它包含了超过五万个真实拍摄的视频序列,覆盖了多样化的场景、物体类别与运动模式,其数据量远超以往以合成或人像为主的数据集。与依赖前景背景人工合成的传统数据集不同,MA-V中的所有视频均保留了前景与背景自然共存的原始场景,避免了合成带来的光照、运动模糊与时序一致性等方面的伪影。该数据集提供的阿尔法蒙版标注精细地捕捉了毛发、半透明区域、运动模糊等复杂细节,为模型学习真实世界的复杂交互提供了宝贵资源。
使用方法
MA-V数据集为视频抠图研究提供了全新的训练与评估基准。研究人员可直接利用其大规模的真实视频标注对现有模型进行微调,以提升模型在开放域视频上的鲁棒性,例如将SAM2模型在该数据集上微调得到的SAM2-Matte模型即展现出卓越的性能。同时,该数据集也可作为评估基准,用于测试模型在多样化真实场景下的抠图精度与时序一致性。其构建流程本身亦为利用生成先验与易得的分割线索来规模化创建高质量标注提供了可复现的范式,推动了该领域向数据驱动的规模化研究迈进。
背景与挑战
背景概述
视频抠图作为计算机视觉领域的一项基础任务,旨在从视频序列中以像素级精度提取前景对象,在视频编辑、背景替换和视觉合成等应用中具有核心价值。然而,该领域长期面临高质量标注数据稀缺的困境。为此,由韩国科学技术院、高丽大学及Adobe研究院的研究团队于2024年共同构建了Matting Anything in Video (MA-V)数据集。该数据集依托VideoMaMa模型,通过将大规模视频分割数据集SA-V中的二元掩码转换为连续透明度蒙版,首次提供了覆盖5万余个真实世界视频的高质量抠图标注。MA-V的诞生突破了以往数据合成方法的局限,其标注对象不再局限于人像,涵盖了多样化的场景与运动模式,为视频抠图模型的泛化能力研究奠定了关键的数据基础。
当前挑战
视频抠图领域面临的核心挑战在于如何从复杂动态场景中精确分离前景与背景,并生成具有时间一致性的透明度蒙版。传统方法受限于标注数据的规模与真实性,现有数据集多基于合成内容或局限于人像,导致模型难以泛化至真实世界的复杂光照、运动模糊及前景-背景交互场景。在数据集构建层面,主要挑战源于高质量真值标注的获取成本极高,通常需在绿幕工作室或特定设备下完成,难以规模化。此外,将分割掩码转换为精细抠图标注的过程,需克服模型对粗糙输入边界的依赖,并确保生成结果的时空连贯性与细节真实性,避免因合成数据与真实视频间的域差异而引入不自然伪影。
常用场景
经典使用场景
在视频抠图研究领域,高质量标注数据的匮乏长期制约着模型的泛化能力。Matting Anything in Video (MA-V) 数据集的核心应用场景在于为视频抠图模型提供大规模、多样化的训练与评估基准。该数据集通过将SA-V数据集中的二值分割掩码转化为精细的alpha蒙版,构建了首个基于真实世界视频的大规模抠图标注集合。研究者可利用MA-V训练端到端的视频抠图模型,或评估模型在复杂自然场景下的鲁棒性,尤其擅长处理包含运动模糊、半透明区域及复杂边界的视频序列。
衍生相关工作
MA-V数据集的发布催生了一系列重要的衍生研究工作。最具代表性的是SAM2-Matte模型,该工作通过在MA-V上微调SAM2分割模型,显著提升了视频抠图的性能与泛化能力。此外,基于MA-V的评估基准推动了Mask-Guided Video Matting、Generative Video Matting等方向的方法创新。数据集构建中采用的VideoMaMa模型本身也成为利用生成先验进行视频标注的典范,启发了后续基于扩散模型的感知任务研究,形成了“数据生成-模型训练-性能提升”的良性研究循环。
数据集最近研究
最新研究方向
在视频抠图领域,高质量标注数据的稀缺长期制约着模型在真实场景中的泛化能力。近期研究通过引入扩散模型的生成先验,开创了从粗粒度分割掩码生成精确阿尔法蒙版的新范式。VideoMaMa模型利用预训练视频扩散模型,仅依靠合成数据训练即可实现零样本泛化,成功将大规模分割数据集转化为高质量的伪标注视频抠图数据集MA-V。这一进展不仅解决了数据规模与多样性的瓶颈,更推动了基于生成先验与易得分割线索的可扩展标注流程,为视频抠图研究提供了首个覆盖广泛真实场景的大规模基准,显著提升了模型在复杂动态与精细结构上的处理鲁棒性。
相关研究论文
- 1VideoMaMa: Mask-Guided Video Matting via Generative Prior高丽大学; 阿多比研究院; 韩国科学技术院·人工智能实验室 · 2026年
以上内容由遇见数据集搜集并总结生成


