latkes/RACA-PROJECT-MANIFEST
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/latkes/RACA-PROJECT-MANIFEST
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
# RACA-PROJECT-MANIFEST
Central registry of all datasets in the `latkes` organization.
- **Total Datasets Tracked**: 2
- **Last Updated**: 2026-04-10T14:01:37.865688+00:00
## Usage
```python
from datasets import load_dataset
manifest = load_dataset("latkes/RACA-PROJECT-MANIFEST", split="train")
print(f"Tracking {len(manifest)} datasets")
```
---
许可证:MIT许可证
---
# RACA-PROJECT-MANIFEST
`latkes` 组织下所有数据集的中央注册表。
- **已追踪数据集总数**:2
- **最后更新时间**:2026-04-10T14:01:37.865688+00:00
## 使用方式
python
from datasets import load_dataset
manifest = load_dataset("latkes/RACA-PROJECT-MANIFEST", split="train")
print(f"当前已追踪 {len(manifest)} 个数据集")
提供机构:
latkes
搜集汇总
数据集介绍
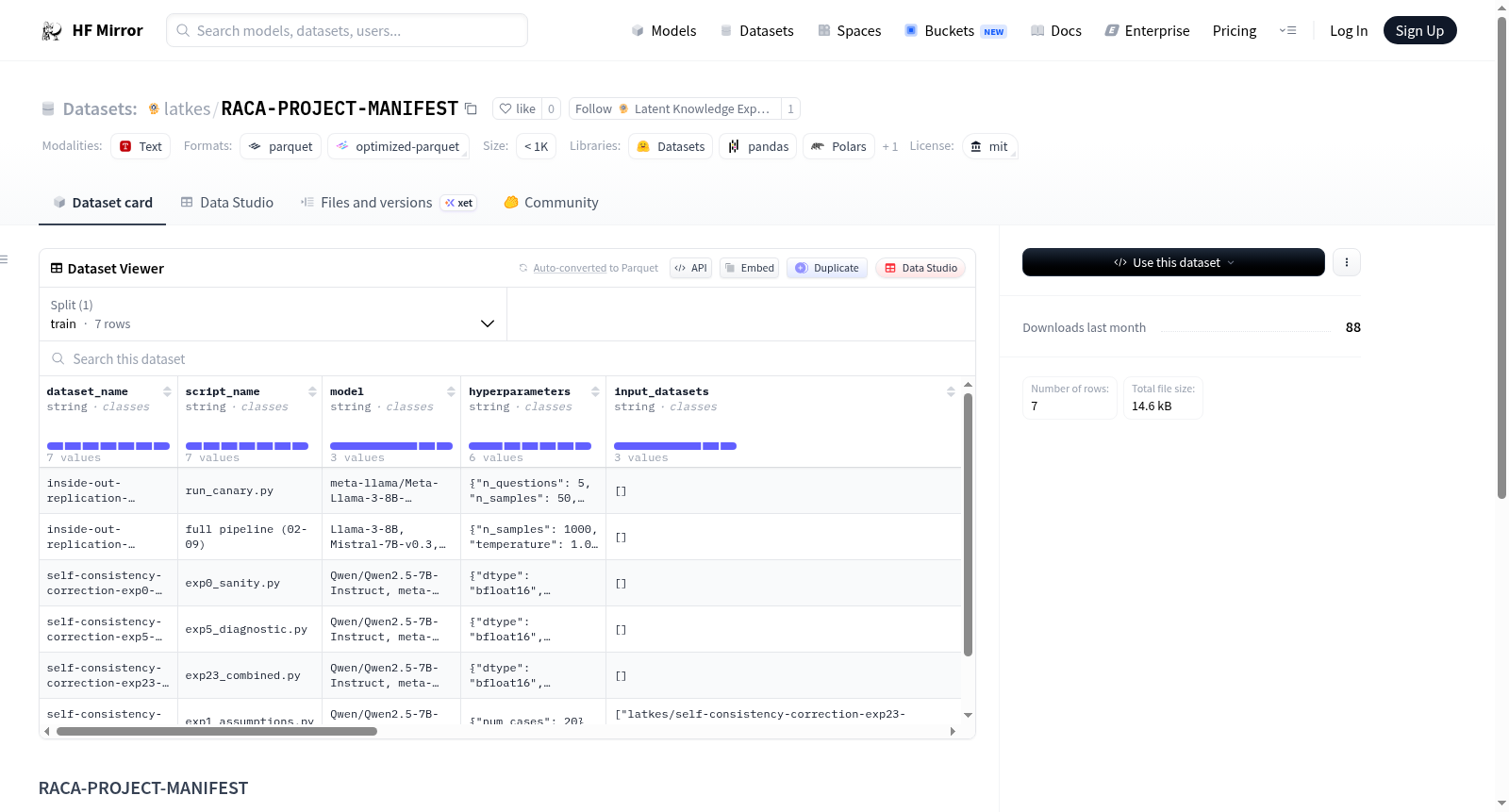
构建方式
RACA-PROJECT-MANIFEST数据集作为latkes组织下所有数据集的集中注册表而构建。它采用结构化的清单形式,追踪并汇总了组织内共计7个数据集的元信息,并通过持续更新的时间戳(最近更新于2026年4月13日)确保内容的时效性。该数据集以HuggingFace Datasets库的标准格式存储,使用MIT开源许可证发布,便于广大研究者直接调用与扩展。
特点
该数据集的显著特点在于其枢纽性定位与轻量化设计。作为数据集的数据集(meta-dataset),它并非承载具体训练样本,而是扮演注册中心的角色,提供组织内数据资源的全局概览。其简洁的架构避免了冗余,同时通过版本控制与时间戳机制保证了可追溯性,为跨数据集的发现、管理与协作提供了统一的入口。
使用方法
使用方法极为简便,研究者只需通过HuggingFace的`datasets`库中的`load_dataset`函数,指定名称`latkes/RACA-PROJECT-MANIFEST`与分割`train`即可加载该清单。加载后,可获取`manifest`对象,其长度指示当前追踪的数据集总数。这一接口设计使得用户能迅速整合并索引组织内的多个数据集资源,极大提升了数据管理的效率与可复现性。
背景与挑战
背景概述
RACA-PROJECT-MANIFEST数据集诞生于2026年,由latkes组织创建,其核心使命是作为该组织所有数据集的中央注册表,实现数据资源的统一管理与高效索引。这一创举源于机器学习领域数据碎片化日益严重的痛点,研究机构与开发者往往面临数据集分散、版本混乱、发现困难等问题,严重阻碍了模型训练与学术复现的效率。作为元数据枢纽,RACA-PROJECT-MANIFEST不仅记录了当前追踪的7个数据集的元信息,更通过标准化接口提供了一站式访问入口,显著提升了数据资产的可发现性与可维护性。该数据集对latkes组织内部的数据治理范式产生了深远影响,并为跨数据集的联合训练与基准测试奠定了坚实基础,展现出在数据管理智能化进程中的关键价值。
当前挑战
RACA-PROJECT-MANIFEST所解决的领域问题挑战在于:机器学习生态中数据孤岛现象严重,不同团队的数据集缺乏统一的索引与元数据描述规范,导致数据复用率低下、研究结果难以复现。构建过程中的挑战则包括:1)需要设计兼容不同数据集格式的元数据标准,确保对文本、图像、音频等异构数据源的统一描述;2)维护数据集的版本更新与历史记录,应对频繁的数据集迭代与新增需求;3)建立自动化的注册与更新机制,避免人工维护带来的延迟与错误,确保7个数据集的元信息始终保持同步。这些挑战共同推动了该数据集在设计上采用轻量级、可扩展架构,以适应未来数据规模的增长与组织协作的深化。
常用场景
经典使用场景
RACA-PROJECT-MANIFEST数据集作为latkes组织旗下所有数据集的中央注册表,核心用途在于统一管理和索引多个子数据集。研究人员和开发者通过加载该清单,可以高效地发现、检索并调用组织内全部公开数据集,其典型场景包括在自然语言处理、计算机视觉或多模态学习等前沿领域中,快速定位所需数据资源,避免分散查找的繁琐流程。
解决学术问题
该数据集有效解决了学术研究中数据碎片化与版本混乱的难题。在开放科学日益受重视的当下,不同研究团队常因数据分散或元数据不统一而重复劳动,RACA-PROJECT-MANIFEST通过标准化注册机制,使得跨数据集对比实验、可复现性验证以及数据溯源变得简单可行,这极大促进了科研生态的协作效率与透明度。
衍生相关工作
该数据集衍生了一系列关于元数据管理和数据集标准化的重要工作,例如基于其清单结构开发的自动化数据质量监测工具、跨数据集的联邦学习索引框架,以及针对HuggingFace平台的资源发现增强方法。这些相关工作进一步拓展了数据集注册与检索的边界,推动了可复现机器学习实验基础设施的成熟。
以上内容由遇见数据集搜集并总结生成


