VSR Expert (VSRE)
收藏arXiv2024-12-24 更新2024-12-26 收录
下载链接:
https://github.com/peijin360/vsre
下载链接
链接失效反馈官方服务:
资源简介:
VSR Expert(VSRE)数据集由哈尔滨工业大学和360搜索部门的研究团队创建,旨在提升视觉大语言模型(VLLM)在视觉空间推理(VSR)任务中的表现。该数据集包含超过10,000个自然图像-文本对,涵盖了66种空间关系,数据来源于MSCOCO数据集,并通过对比性标题生成和人工验证确保数据质量。数据集通过扩散模型生成图像数据,并结合多种视觉编码器(如CLIP、SigLIP、SAM和DINO),增强了模型对视觉位置信息的感知能力。该数据集的应用领域主要集中在视觉空间推理任务中,旨在解决VLLM在视觉位置信息识别和指令跟随中的不一致性和幻觉问题。
The VSR Expert (VSRE) dataset was developed by research teams from Harbin Institute of Technology and the 360 Search Division, with the goal of enhancing the performance of Vision-Language Models (VLLMs) on visual spatial reasoning (VSR) tasks. This dataset includes over 10,000 natural image-text pairs spanning 66 types of spatial relationships, and it is sourced from the MSCOCO dataset. Its data quality is ensured through contrastive caption generation and manual verification. The dataset generates image data via diffusion models, and integrates multiple visual encoders such as CLIP, SigLIP, SAM, and DINO to improve models' perception of visual positional information. The primary application scope of this dataset lies in visual spatial reasoning tasks, where it aims to resolve the inconsistency and hallucination problems faced by VLLMs in visual positional information recognition and instruction following.
提供机构:
哈尔滨工业大学, 360搜索部门
创建时间:
2024-12-24
原始信息汇总
VSRE数据集概述
数据集简介
- 名称: VSRE(Expand VSR Benchmark for VLLM to Expertize in Spatial Rules)
- 目的: 扩展VSR基准,以提升VLLM在空间规则方面的专业性。
相关资源
- 论文: Arxiv
- 附录材料: Appendix Material
- 数据集: 尚未提供
- 检查点: 尚未提供
最新动态
- 2024年12月11日: VSRE工作被AAAI 2025接受。
- 2024年12月23日: 上传了论文和附录材料。
待办事项
- 上传生成的图像
- 提供生成图像上目标检测的统计表
目录
搜集汇总
数据集介绍
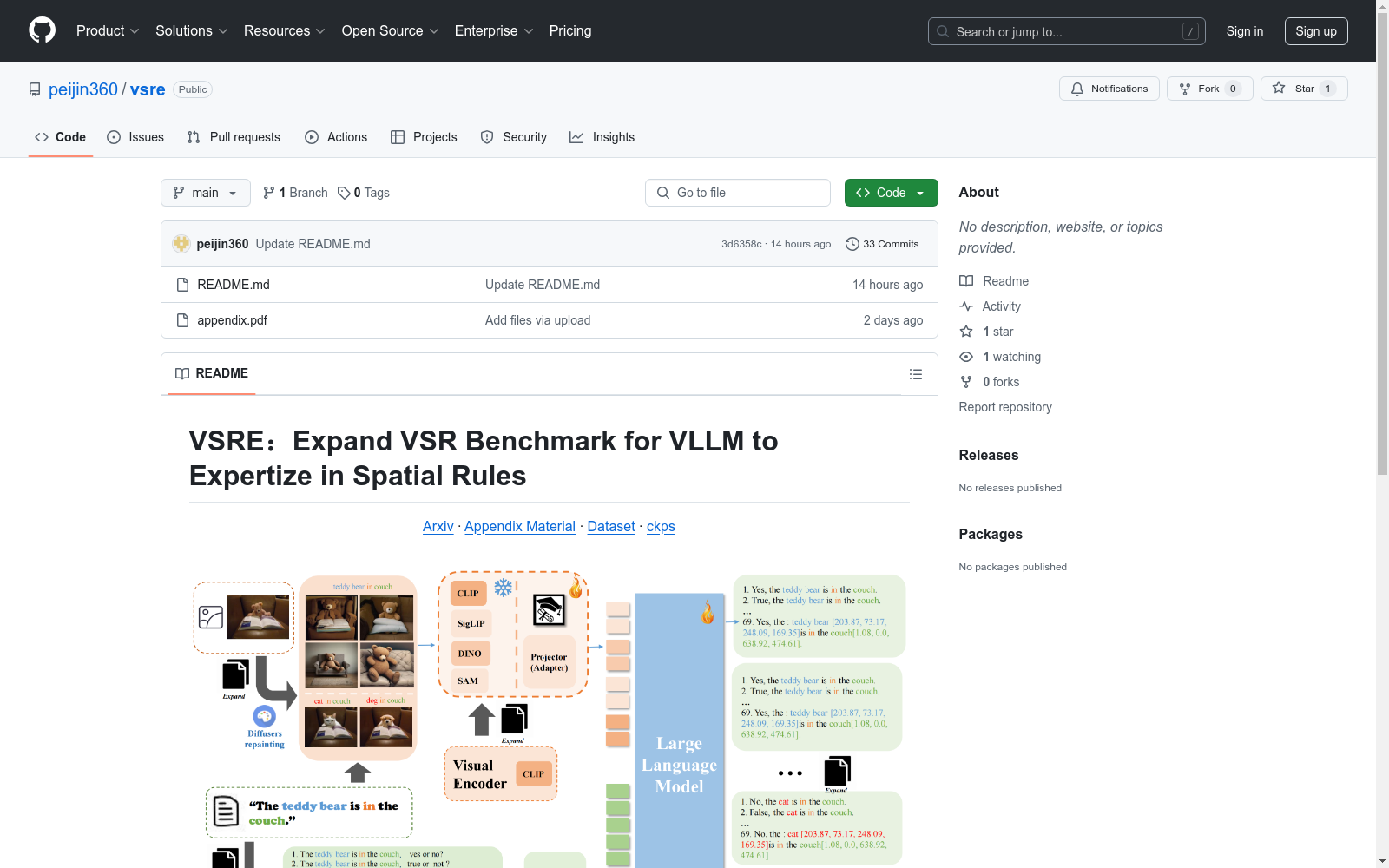
构建方式
VSR Expert (VSRE) 数据集的构建基于对现有视觉空间推理(VSR)数据集的扩展与优化。首先,研究团队通过诊断当前视觉大语言模型(VLLMs)在VSR任务中的表现,发现其对语言指令的过度敏感与对视觉位置信息的低敏感性之间的矛盾。为解决这一问题,团队从数据增强和模型结构两方面进行了扩展。具体而言,通过扩散模型可控地生成了大量具有特定空间关系概念的图像数据,并将原始的视觉编码器(CLIP)与其他三种强大的视觉编码器(SigLIP、SAM和DINO)进行了集成。此外,通过手动和GPT-4生成的模板,扩展了文本问答数据,确保了数据集的多样性和丰富性。最终,通过数据扩展和模型优化,构建了一个在视觉空间推理任务上表现卓越的VLLM模型——VSRE。
使用方法
VSRE数据集的使用方法主要分为两个阶段:预训练和指令微调。在预训练阶段,模型通过大量扩展的图像数据进行训练,以增强其对视觉空间关系的理解能力。在指令微调阶段,模型通过多样化的文本问答数据进行训练,以提升其在不同指令下的泛化能力。具体使用时,研究人员可以通过加载预训练的VSRE模型,并在特定任务上进行微调,以进一步提升模型的表现。此外,VSRE数据集还提供了统一的测试集,用于评估模型在视觉空间推理任务上的表现。通过这种方式,研究人员可以系统地评估和优化模型在VSR任务中的表现。
背景与挑战
背景概述
VSR Expert (VSRE) 数据集由哈尔滨工业大学和360搜索部门的研究团队于2024年提出,旨在解决视觉大语言模型(VLLMs)在视觉空间推理(VSR)任务中的性能瓶颈。该数据集的核心研究问题是如何提升VLLMs在视觉位置推理中的准确性和泛化能力。通过扩展原始VSR基准数据集,VSRE首次利用扩散模型可控地生成了大量空间定位图像数据,并结合了多种视觉编码器(如CLIP、SigLIP、SAM和DINO)以增强模型的视觉感知能力。VSRE在VSR测试集上的准确率提升了超过27%,成为当前在视觉位置推理任务中表现最优的VLLM之一。该数据集的发布为VLLMs在视觉空间推理领域的研究提供了重要的数据支持和优化方向。
当前挑战
VSRE数据集在构建和应用过程中面临多重挑战。首先,视觉空间推理任务要求模型能够精确识别图像中的空间关系,而现有的VLLMs往往对语言指令过于敏感,而对视觉位置信息不够敏感,导致模型在回答空间相关问题时表现不稳定。其次,数据集的构建过程中,如何通过扩散模型可控地生成大量具有特定空间关系的图像数据,同时保持数据的多样性和语义一致性,是一个技术难题。此外,VSRE还面临如何有效整合多种视觉编码器以提升模型对空间信息的感知能力的挑战。尽管通过实验验证了多编码器组合的有效性,但如何进一步优化编码器的组合方式以提升模型的推理能力仍需深入研究。最后,VSRE在泛化能力上的提升也带来了新的挑战,即如何确保模型在不同指令格式下的表现一致性,避免因指令格式变化导致的性能波动。
常用场景
经典使用场景
VSR Expert (VSRE) 数据集在视觉空间推理(VSR)任务中展现了其经典应用场景。该数据集通过扩展视觉大语言模型(VLLM)的训练数据和模型结构,显著提升了模型在视觉位置推理任务中的表现。VSRE 数据集通过扩散模型可控地生成空间位置图像数据,并结合多种视觉编码器(如 CLIP、SigLIP、SAM 和 DINO),使得模型能够更准确地识别视觉位置信息,并在不同指令下表现出更好的泛化能力。
解决学术问题
VSRE 数据集解决了当前视觉大语言模型在视觉空间推理任务中的关键问题,包括对语言指令的过度敏感性和对视觉位置信息的敏感性不足。通过扩展训练数据和优化模型结构,VSRE 显著提升了模型在视觉位置推理任务中的准确性,减少了模型在回答空间关系问题时的偏差。这一进展不仅填补了 VLLM 在视觉空间推理任务中的评估和优化空白,还为解决模型在关系推理中的幻觉问题提供了重要支持。
实际应用
VSRE 数据集在实际应用中具有广泛的前景,尤其是在需要精确视觉位置推理的领域,如自动驾驶、机器人导航和增强现实等。通过提升模型对视觉位置信息的敏感性和理解能力,VSRE 能够帮助这些领域的系统更准确地识别和处理空间关系,从而提高系统的整体性能和可靠性。此外,VSRE 的扩展方法和优化策略也为其他多模态任务提供了有价值的参考。
数据集最近研究
最新研究方向
在视觉空间推理(VSR)领域,VSRE数据集的提出标志着对视觉大语言模型(VLLMs)在空间关系理解能力上的重大突破。该数据集通过扩展训练数据和模型结构,显著提升了模型对视觉位置信息的敏感度和推理准确性。具体而言,VSRE首次利用扩散模型可控地生成了大量具有特定空间关系的图像数据,并结合了多种强大的视觉编码器(如SigLIP、SAM和DINO),从而增强了模型对视觉细节的感知能力。实验表明,VSRE在VSR测试集上的准确率提升了超过27%,并在多个评估基准的相关子集上表现出色。这一进展不仅填补了VLLMs在空间推理任务上的评估和优化空白,还为解决模型在关系推理中的幻觉问题提供了新的思路。VSRE的开源进一步推动了VSR领域的研究进展,为多模态大模型的未来发展奠定了坚实基础。
相关研究论文
- 1Expand VSR Benchmark for VLLM to Expertize in Spatial Rules哈尔滨工业大学, 360搜索部门 · 2024年
以上内容由遇见数据集搜集并总结生成


