MONET
收藏arXiv2026-05-20 更新2026-05-22 收录
下载链接:
https://huggingface.co/datasets/jasperai/monet/
下载链接
链接失效反馈官方服务:
资源简介:
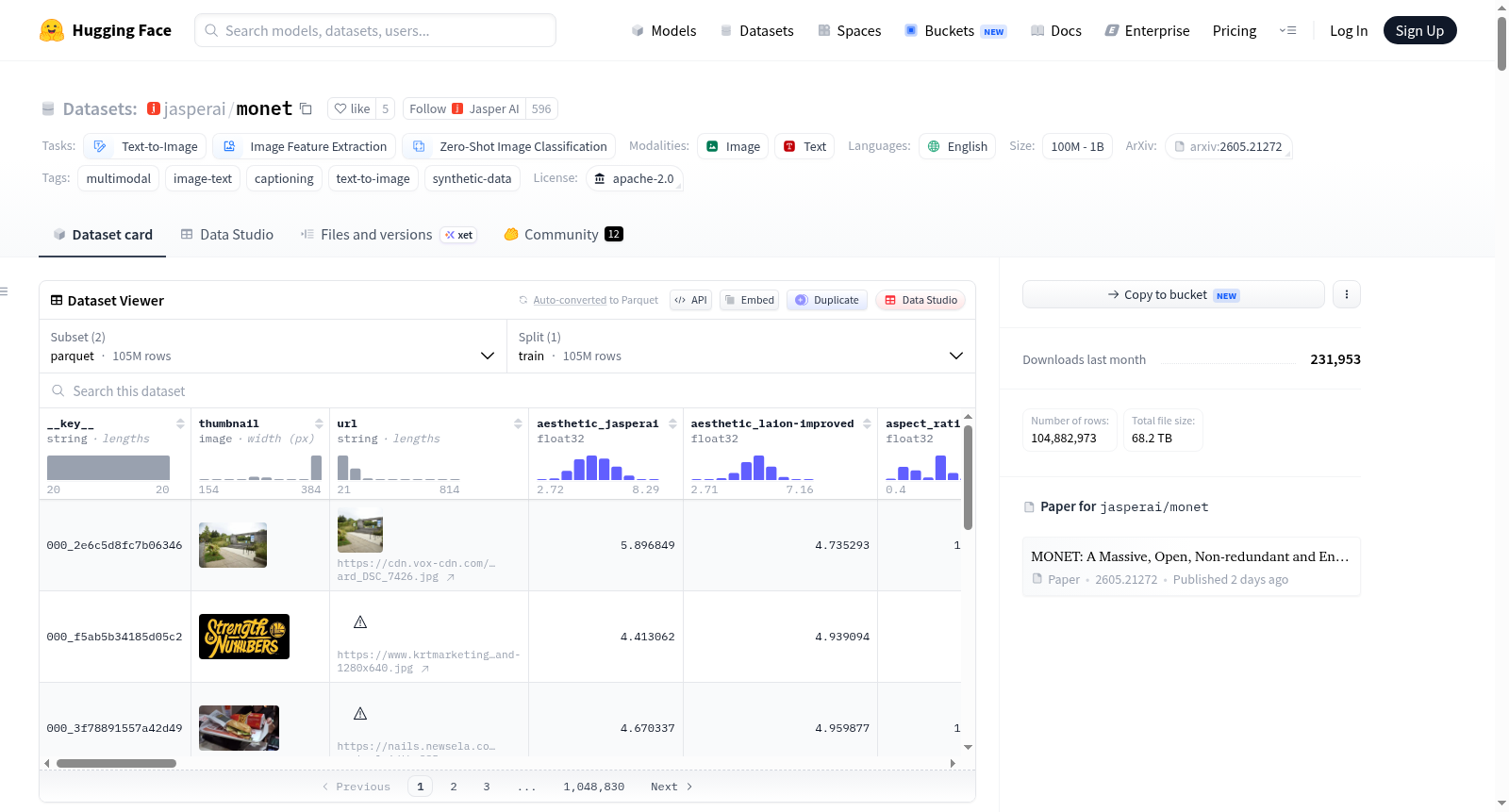
MONET是由Jasper Research构建的大规模开源文本-图像数据集,包含约1.049亿对高质量图像-文本样本,旨在降低大规模文本-图像模型研究的门槛。该数据集从29亿原始对中经过多阶段严格筛选,包括安全性过滤、去重和基于领域的过滤,并采用多种视觉语言模型进行重新标注,涵盖从简短概念到精细描述的多层次文本。数据集构建过程整合了美学评分、多分类器安全检测、感知哈希去重等技术,并补充了由Apache 2.0许可模型生成的合成样本。该数据集主要应用于训练大规模文本-图像生成模型,解决现有公开数据集中存在的冗余性高、标注质量低、安全性不足等问题,促进开放、可复现的生成式AI研究。
MONET is a large-scale open-source text-image dataset constructed by Jasper Research, containing approximately 104.9 million high-quality image-text pairs, aiming to lower the barrier to research on large-scale text-image models. This dataset is rigorously screened in multiple stages from 2.9 billion raw pairs, including safety filtering, deduplication and domain-specific filtering, and is re-annotated using multiple visual-language models, covering multi-level texts ranging from brief concepts to fine-grained descriptions. The dataset construction process integrates technologies such as aesthetic scoring, multi-classifier safety detection and perceptual hash deduplication, and supplements synthetic samples generated by models licensed under Apache 2.0. This dataset is primarily used for training large-scale text-image generation models, addressing the issues of high redundancy, low annotation quality and insufficient safety existing in current public datasets, so as to promote open and reproducible generative AI research.
提供机构:
Jasper Research
创建时间:
2026-05-20
搜集汇总
数据集介绍
构建方式
MONET数据集源自对异构开放资源的深度整合与精炼。其构建始于收集来自LAION、COYO等九个来源的约29亿原始图像-文本对,随后通过一系列严格的流水线处理:首先利用美学评分与分辨率阈值进行预过滤,剔除低质量样本;继而采用多分类器集成策略(包括Falcon、Bumble及内部模型)进行安全过滤,并借助Re-LAION的CSAM筛查确保内容合规;接着采用感知哈希与自监督复制检测(SSCD)相结合的两阶段去重策略,分别去除精确与近似重复项;最后通过域名封禁与水印过滤实施源治理。幸存图像由Florence2、InternVL3、ShareGPT4V及Gemini等多款视觉语言模型进行重新标注,并辅以Apache 2.0许可的文本到图像模型生成的合成数据加以扩充,最终形成包含约1.049亿对高质量图文对的语料库。
特点
MONET数据集的核心特点在于其大规模、开放性、非冗余性与丰富语义的有机统一。其规模达到1.049亿对,显著超越了此前开源的细粒度标注数据集。通过两阶段去重机制,有效规避了常见网络语料库中因重复样本导致的分布偏斜与记忆化问题。尤为突出的是,数据集为每张图像提供了由四种不同复杂度视觉语言模型生成的、覆盖从简洁概念到详尽描述的多样化文本标注,这一多视角标注策略极大丰富了提示分布,避免了单一模型带来的风格固化。此外,数据集还预先计算并附带了DINOv2、CLIP、SSCD等嵌入向量,以及YOLO目标检测、MediaPipe人脸识别等结构化注释,并提供了经过SANA变分自编码器预压缩的潜在表示,大幅提升了下游使用的效率与便捷性。
使用方法
MONET数据集专为大规模文本到图像模型的预训练而设计。使用者可直接利用数据集提供的原始图像与多种重新生成的文本描述进行监督训练,亦可依据需求灵活混合不同长度与风格的标注以增强模型鲁棒性。预计算的多模态嵌入向量(如CLIP、DINOv2、SSCD)与注释文件(如YOLO检测框、ImageNet分类概率)可直接用于检索、分类或条件生成等任务,避免了重复的特征提取计算。尤为便捷的是,数据集中包含的SANA变分自编码器潜在表示,允许研究人员直接在压缩的潜在空间中进行扩散模型的训练,显著降低了对存储带宽与计算资源的需求。用户可通过Hugging Face平台下载全部数据,并利用公开的FAISS索引进行高效的图像相似性搜索与分析。
背景与挑战
背景概述
MONET数据集由Jasper Research团队于2026年创建,旨在填补大规模文本到图像(T2I)预训练数据集的空白。该数据集包含约1.049亿图像-文本对,来源于29亿原始对,经过严格的安全过滤、域过滤、精确与近似去重,并利用多种视觉语言模型进行重新标注。其核心研究问题是解决开源T2I数据集缺乏高质量、多样化、低冗余度且具有丰富标注的问题,从而降低大规模可复现T2I研究的门槛,推动该领域的开放与透明发展。
当前挑战
MONET数据集面临的挑战主要涵盖两方面。在领域问题层面,它致力于解决现有开源数据集如LAION-5B、COYO-700M存在的严重冗余、噪声大、标注简短且质量低下的问题,以及单一标注模型导致的分布偏差。在构建过程中,挑战包括从29亿对原始数据中高效进行多级过滤与去重(如使用SSCD处理几何变换后的近似重复)、平衡多模型标注的计算成本与质量、在保证安全性与合规性的同时避免过度过滤,以及处理大规模计算所需的约17.5万GPU小时资源消耗。
常用场景
经典使用场景
在文本到图像生成领域,高质量、大规模且经过精细筛选的训练数据是驱动模型性能提升的核心要素。MONET数据集正是为满足这一需求而生,它包含约1.049亿个图像-文本对,经过严格的安全过滤、多阶段去重、领域过滤以及多视觉语言模型的重新标注,旨在为大规模文本到图像模型的预训练提供纯净、多样且富含详细描述的训练语料。其最经典的使用场景是作为大规模文本到图像扩散模型(如基于MMDiT架构的潜在扩散模型)的预训练数据集,研究人员可以直接利用MONET提供的图像、多源标注文本以及预计算的特征嵌入,高效地训练从短概念级到长细粒度描述的多模态生成模型。
解决学术问题
MONET解决了学术研究中大规模文本到图像数据集构建的多个核心难题。首先,它打破了以往数据集建设的高昂成本与复杂性壁垒——通过全自动化的流水线从29亿原始对中蒸馏出高质量子集,降低了可复现研究的门槛。其次,它攻克了网络爬取数据中普遍存在的噪声、冗余与不安全内容问题,引入了多视觉语言模型(Florence2、InternVL3、ShareGPT4V、Gemini)的混合标注策略,有效避免了单一标注器带来的分布偏差,显著提升了模型对长尾及分布外提示的泛化能力。此外,其结合感知哈希与自监督拷贝检测的两阶段去重策略,缓解了扩散模型中的过拟合与记忆化现象,为后续研究提供了关于数据去重必要性与方法的宝贵实证。
衍生相关工作
MONET的出现催生了一系列重要的后续工作。首先,在其数据集构建方法论上,多视觉语言模型混合标注策略(Mix-of-Captioners)被后续研究广泛借鉴,例如后来的研究证明均匀采样多个标注器可提升模型鲁棒性,促使更多工作探索标注多样性对生成质量的影响。其次,MONET验证了在数据集中适度掺入合成数据(如FLUX和Z-Image生成的样本)能够改善图像-文本对齐,这一发现推动了合成数据增强在视觉语言预训练中的规范化应用。此外,MONET附带的大规模伦理审计(包括文化起源、肤色、性别等维度的人口统计偏倚分析)为构建公平透明的生成模型设立了标准,促使学界更系统地关注数据集中固有偏见的量化与缓解策略。
以上内容由遇见数据集搜集并总结生成


