Aether-Lite-v1.8
收藏Hugging Face2024-06-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/TheSkullery/Aether-Lite-v1.8
下载链接
链接失效反馈官方服务:
资源简介:
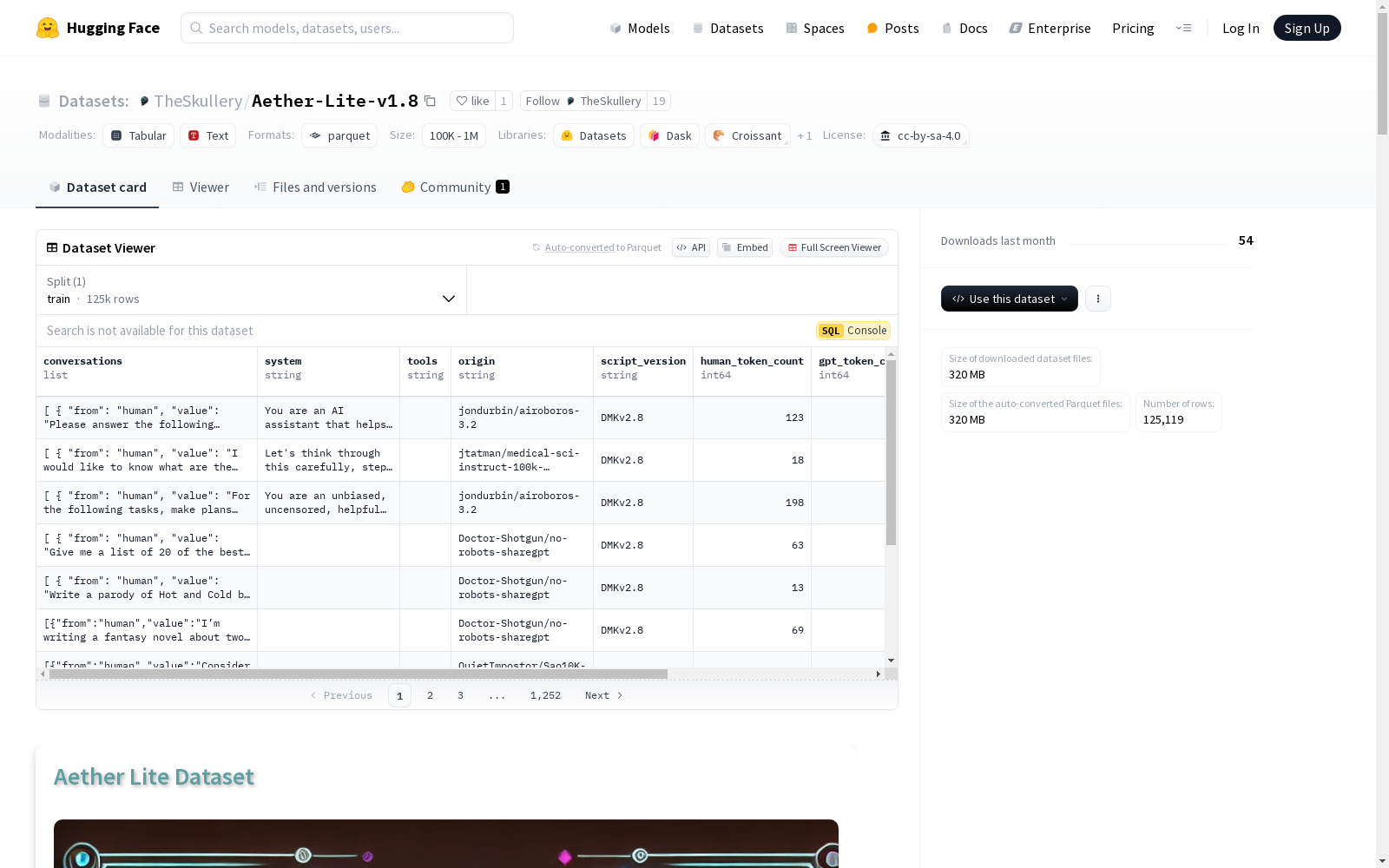
Aether Lite数据集旨在平衡创意写作、Slop和智能。该数据集设计了新的功能,包括数据集使用百分比、数据集洗牌以及一种新的模糊去重方法。去重方法设置为95%的阈值,并对整个脚本进行了内存和CPU使用的重新设计。数据集处理统计包括最大CPU使用量、最大RAM使用量、最大卸载内存使用量和总体处理时间。数据集格式详细说明了各个字段,如对话、系统、工具、起源、脚本版本、人类令牌计数、GPT令牌计数、令牌分布和处理时间毫秒。此外,还列出了使用的数据集及其使用百分比,并提供了去重统计和数据集创建过程的详细步骤。
The Aether Lite dataset aims to balance creative writing, Slop, and intelligence. This dataset integrates novel features, including dataset usage percentage, dataset shuffling, and a new fuzzy deduplication method. The deduplication method adopts a 95% threshold, and the entire script has been redesigned to optimize memory and CPU utilization. Dataset processing statistics cover peak CPU utilization, peak RAM utilization, peak offloaded memory utilization, and overall processing time. The dataset format specifies various fields such as conversation, system, tool, origin, script version, human token count, GPT token count, token distribution, and processing time in milliseconds. Furthermore, the utilized source datasets and their respective usage percentages are listed, alongside deduplication statistics and detailed steps of the dataset creation process.
创建时间:
2024-06-20
原始信息汇总
数据集概述
数据集信息
特征
- conversations: 对话列表
- from: 字符串类型
- value: 字符串类型
- system: 字符串类型
- tools: 字符串类型
- origin: 字符串类型
- script_version: 字符串类型
- human_token_count: 整数类型
- gpt_token_count: 整数类型
- token_distribution: 整数类型
- processing_time_ms: 浮点数类型
数据分割
- train: 训练集
- num_bytes: 2392354861 字节
- num_examples: 125119 条样本
数据大小
- download_size: 319533563 字节
- dataset_size: 2392354861 字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
数据集处理统计
数据集格式
- conversations: 对话列表
- from: 字符串类型
- value: 字符串类型
- system: 字符串类型
- tools: 字符串类型
- origin: 字符串类型
- script_version: 字符串类型
- human_token_count: 整数类型
- gpt_token_count: 整数类型
- token_distribution: JSON 格式
- processing_time_ms: 浮点数类型
使用的数据集
- jondurbin/airoboros-3.2: 100% 使用
- jtatman/medical-sci-instruct-100k-sharegpt: 20% 使用
- Doctor-Shotgun/no-robots-sharegpt: 100% 使用
- QuietImpostor/Sao10K-Claude-3-Opus-Instruct-15K-ShareGPT: 100% 使用
- mrfakename/Pure-Dove-ShareGPT: 100% 使用
- PJMixers/grimulkan_theory-of-mind-ShareGPT: 100% 使用
- PJMixers/grimulkan_physical-reasoning-ShareGPT: 100% 使用
- TheSkullery/WizardLM_evol_instruct_v2_Filtered_Fuzzy_Dedup_ShareGPT: 25% 使用
- MinervaAI/Aesir-Preview: 100% 使用
- TheSkullery/Gryphe-Opus-WritingPrompts-merged: 100% 使用
- mpasila/LimaRP-PIPPA-Mix-8K-Context: 50% 使用
- Alignment-Lab-AI/RPGuild-sharegpt-filtered: 30% 使用
数据集处理步骤
- 模型和分词器准备
- 语言模型: 下载并加载预训练的 FastText 语言模型以检测数据集条目的语言。
- 数据过滤和转换
- 令牌分布: 初始化令牌分布字典以跟踪不同范围内的令牌计数。
- 正则表达式创建: 生成正则表达式以识别和删除数据集中不需要的短语。
- 文本清理: 通过删除或替换换行符来清理文本。
- 对话过滤: 如果第一个人的消息的语言不可接受,或者任何消息包含特定的过滤数据或匹配正则表达式,则过滤掉整个对话。
- 记录转换: 通过更新令牌计数和令牌分布,并仅保留相关对话来转换每个记录。
- 块处理和文件写入
- 块处理: 通过应用过滤和转换规则,累积令牌统计信息,并将处理后的数据写入 Parquet 文件来处理每个数据块。
- 文件写入: 将处理后的块数据保存到指定目录以进行进一步分析和合并。
- 去重和合并
- Spark 会话初始化: 初始化 Spark 会话以处理大规模数据处理。
- 模式适应: 检查并调整 Spark DataFrame 的模式(如果必要)。
- 文本嵌入: 使用预训练模型将文本数据编码为嵌入,并使用这些嵌入计算余弦相似度以进行去重。
- 余弦相似度计算: 计算嵌入之间的余弦相似度以识别和删除重复条目。
- 绘图创建: 使用 PCA、t-SNE 和 UMAP 生成去重前后的嵌入可视化。
- 数据洗牌: 随机化数据集行的顺序以确保多样化和无偏的数据集。
- 数据采样: 根据预定义的使用百分比对每个数据集进行采样。
- 模式检查: 检查并打印最终数据集的模式以确保其符合预期格式。
- 最终去重: 根据余弦相似度对最终数据集进行去重并保存清理后的数据。
- 最终输出
- 合并数据集: 将处理、过滤、去重和洗牌后的数据集保存为单个 Parquet 文件。
模糊去重统计
- 起始行数: 141369
- 最终行数: 125119
- 删除行数: 16250
数据集创建过程
- 数据集通过细致的过程创建,包括分块、处理、清理、模糊去重和特定机器人短语的删除。
可视化
- 使用 PCA、t-SNE 和 UMAP 三种不同的降维技术展示了去重过程的影响。
搜集汇总
数据集介绍
构建方式
Aether-Lite-v1.8数据集的构建过程体现了高度的技术严谨性和数据处理复杂性。该数据集通过多个步骤精心构建,包括数据分块、处理、清洗、模糊去重以及特定短语的移除。首先,使用预训练的FastText语言模型检测数据条目的语言,随后通过正则表达式生成和文本清理进行数据过滤和转换。接着,利用Spark会话处理大规模数据,并通过文本嵌入和余弦相似度计算进行去重。最终,数据集经过随机化处理,确保多样性和无偏性,并保存为Parquet文件格式。
特点
Aether-Lite-v1.8数据集的特点在于其多样性和高质量的数据内容。该数据集融合了多个来源的数据,包括创意写作、角色扮演、推理指导以及医学领域的内容。通过严格的模糊去重和特定短语的移除,确保了数据的独特性和纯净度。此外,数据集还包含了详细的元数据信息,如对话来源、系统信息、工具使用情况等,为研究者提供了丰富的研究素材。数据集的构建过程中还引入了新的功能,如数据集使用百分比控制、数据洗牌以及新的去重方法,进一步提升了数据集的实用性和灵活性。
使用方法
Aether-Lite-v1.8数据集的使用方法灵活多样,适用于多种自然语言处理任务。研究者可以通过加载Parquet文件格式的数据集,利用其丰富的元数据和多样化的内容进行模型训练和评估。数据集中的对话数据可以用于对话系统的开发,而推理指导和医学领域的内容则适用于特定领域的模型训练。此外,数据集的随机化处理和去重功能确保了训练数据的多样性和无偏性,有助于提升模型的泛化能力。通过结合数据集的元数据信息,研究者还可以进行更深入的数据分析和模型优化。
背景与挑战
背景概述
Aether-Lite-v1.8数据集由SteelSkull创建,旨在平衡创意写作、Slop(低质量内容)与智能表现。该数据集整合了多个来源的数据,包括Airoboros、Medical-Sci-Instruct、No-Robots等,涵盖了创意写作、推理、医学指导等多个领域。数据集的构建过程经过精细的筛选、去重和清洗,采用了模糊去重技术,并引入了新的数据处理功能,如数据集使用百分比控制、数据打乱等。Aether-Lite-v1.8的发布为自然语言处理领域提供了高质量的多任务对话数据,推动了生成式模型在创意写作和推理任务中的应用。
当前挑战
Aether-Lite-v1.8数据集在构建过程中面临多重挑战。首先,数据来源的多样性和复杂性要求对数据进行严格的筛选和清洗,以确保数据质量。其次,模糊去重技术的应用虽然有效减少了重复内容,但在处理大规模数据时对计算资源和时间提出了极高要求,例如在本次构建中消耗了12小时的计算时间和92GB的内存。此外,数据集的平衡性也是一个重要挑战,如何在创意写作、推理和医学指导等不同任务之间找到合适的比例,直接影响模型的泛化能力。最后,数据格式的统一和标准化也是构建过程中的难点,特别是在整合多个来源的数据时,需要确保数据结构的一致性。
常用场景
经典使用场景
Aether-Lite-v1.8数据集在自然语言处理领域中被广泛用于训练和评估对话生成模型。该数据集通过包含多样化的对话场景,如创意写作、角色扮演、医学推理等,为模型提供了丰富的上下文信息。研究人员可以利用这些数据来优化模型在复杂对话中的表现,尤其是在需要高智能和创造力的任务中。
衍生相关工作
Aether-Lite-v1.8数据集催生了一系列基于其数据的经典研究工作。例如,研究者利用该数据集开发了更高效的对话生成模型,并在多个基准测试中取得了显著进展。此外,其模糊去重技术也被广泛应用于其他大规模数据集的预处理中,推动了自然语言处理领域的技术创新。
数据集最近研究
最新研究方向
在自然语言处理领域,Aether-Lite-v1.8数据集的最新研究方向聚焦于多模态对话系统的优化与智能推理能力的提升。该数据集通过引入模糊去重技术,显著提高了数据的多样性与质量,同时结合了创意写作、角色扮演(RP)及医学推理等多样化内容,为模型训练提供了更为丰富的语境。当前研究热点在于如何利用该数据集进一步提升模型在复杂对话场景中的表现,特别是在医学推理和角色扮演任务中的智能响应能力。此外,数据集的处理过程中引入的余弦相似度计算与降维可视化技术,为数据去重与质量评估提供了新的方法论支持,推动了对话系统在真实应用场景中的落地与优化。
以上内容由遇见数据集搜集并总结生成


