Major-TOM/Core-S2RGB-249k-SigLIP
收藏Hugging Face2026-05-04 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/Major-TOM/Core-S2RGB-249k-SigLIP
下载链接
链接失效反馈官方服务:
资源简介:
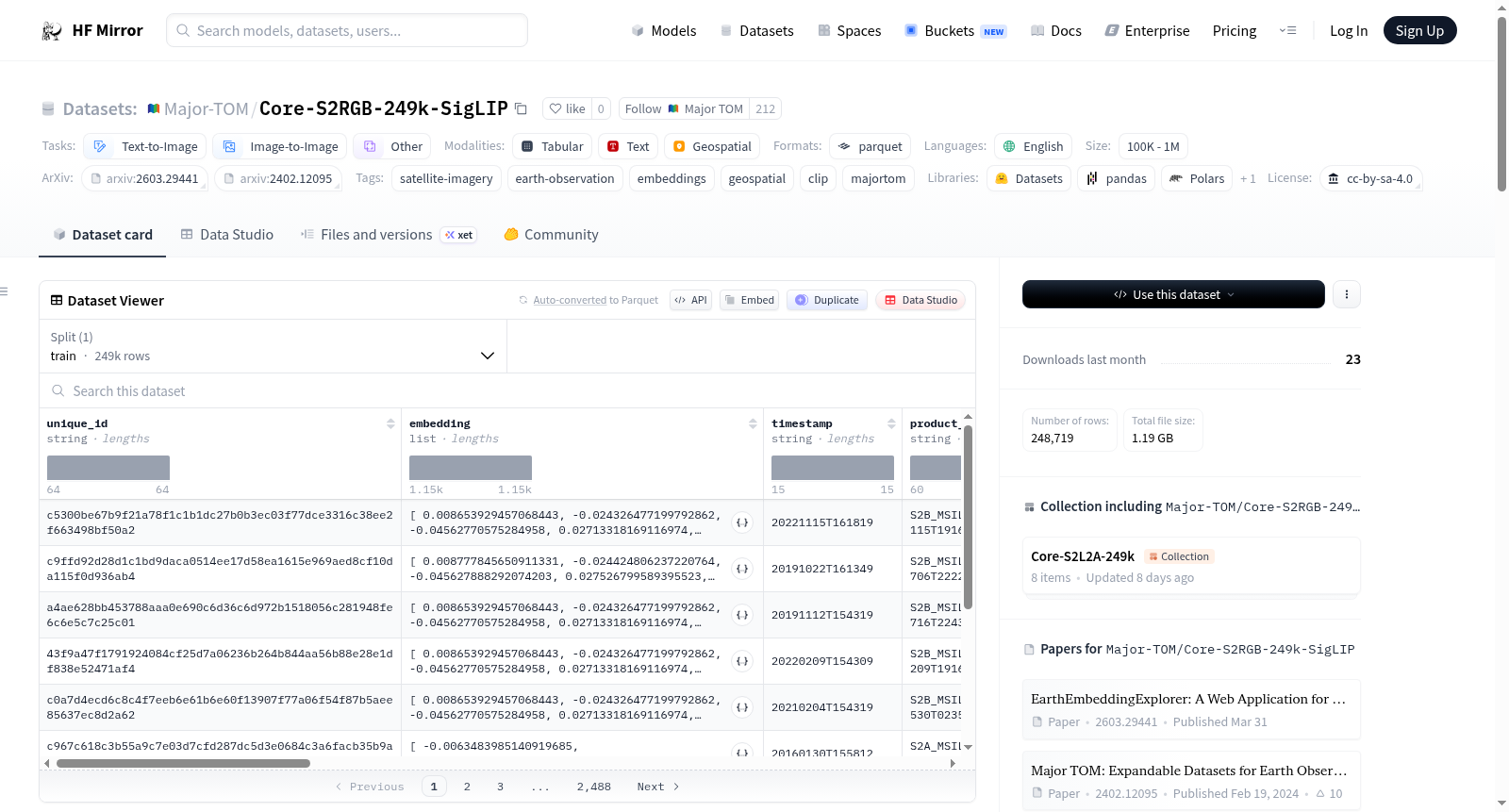
Core-S2RGB-249k-SigLIP是一个基于Core-S2L2A-249k数据集并使用SigLIP模型计算的视觉语言嵌入数据集。数据集包含248,719个384×384像素的Sentinel-2 L2A补丁,通过RGB波段(B04, B03, B02)生成真彩色图像,并使用SigLIP视觉编码器提取1152维图像嵌入。数据集还保留了地理空间元数据,如几何形状、中心经纬度等。数据集以GeoParquet格式存储,包含嵌入向量、时间戳、产品标识符、网格单元标识符、地理坐标等信息。
Core-S2RGB-249k-SigLIP is a vision-language embedding dataset based on the Core-S2L2A-249k dataset, with its vision-language embeddings computed using the SigLIP model. The dataset contains 248,719 Sentinel-2 L2A patches with a resolution of 384×384 pixels. True-color images are generated from these patches via the RGB bands (B04, B03, B02), and 1152-dimensional image embeddings are extracted using the SigLIP vision encoder. The dataset also retains geospatial metadata such as geometry, central longitude and latitude, and other related information. It is stored in GeoParquet format, containing embedding vectors, timestamps, product identifiers, grid cell identifiers, geographic coordinates, and other relevant information.
提供机构:
Major-TOM
搜集汇总
数据集介绍
构建方式
Core-S2RGB-249k-SigLIP数据集基于Core-S2L2A-249k源影像构建,该源影像包含248,719个尺寸为384×384像素的Sentinel-2 L2A卫星图像块。在构建流程中,首先从源parquet文件中提取RGB波段(B04、B03、B02)进行堆叠,并通过2.5倍缩放与截断操作将其归一化至[0,1]范围,生成真彩色图像。随后采用最近邻插值法将图像调整至SigLIP模型所需的384×384分辨率。归一化后的张量被送入SigLIP视觉编码器——一种基于对比学习训练的Vision Transformer,采用sigmoid损失函数——以提取1,152维的图像嵌入向量。生成过程中未对嵌入进行L2归一化处理,归一化操作留待检索时按需执行。同时,原始UTM足迹被重投影至EPSG:4326坐标系,以便获取几何边界、中心经纬度等地理空间元数据。
特点
该数据集的核心价值在于将海量卫星影像转化为高维语义嵌入空间中的紧凑表征,实现了遥感图像与自然语言描述之间的跨模态语义对齐。嵌入向量的维度为1,152,能够捕捉丰富的地物语义特征,且未经过L2归一化处理,保留了原始特征向量的模长信息,为检索任务中灵活应用余弦相似度或点积匹配提供了可能性。数据集采用GeoParquet格式存储,既保留了传统parquet的高效列式存储与压缩优势,又集成了地理空间几何字段,支持直接进行空间查询与范围过滤。此外,数据集中完整保留了产品标识符、采集时间戳、网格单元编号以及原始UTM投影信息,便于用户溯源验证与时空分析。
使用方法
用户可通过Python的数据处理生态便捷地加载该数据集。使用pandas库的read_parquet函数可直接读取本地存储的GeoParquet文件,获得包含嵌入向量及丰富元数据的DataFrame。每条记录中的embedding字段为1,152维浮点数列表,可直接转换为NumPy数组用于下游任务。在进行遥感图像检索时,用户可将文本描述或查询图像输入SigLIP模型提取嵌入,随后计算查询向量与数据集中所有嵌入的余弦相似度,排序后获取最匹配的卫星图块。结合geometry字段的空间索引,还可实现语义与地理范围的双重约束检索。数据集的元数据字段如timestamp支持时序筛选,grid_cell字段则可服务于全球网格化采样分析。
背景与挑战
背景概述
Core-S2RGB-249k-SigLIP数据集诞生于2024年,由Alistair Francis与Mikolaj Czerkawski等研究人员在Major TOM框架下构建。该数据集以248,719个来自Sentinel-2 L2A卫星影像的RGB patch为源,通过SigLIP(ViT-SO400M-14-SigLIP-384)视觉编码器提取1152维嵌入特征,旨在弥合遥感影像与自然图像在跨模态检索中的语义鸿沟。作为全球首个大规模遥感图像嵌入集,其核心研究问题在于如何将对比学习范式(如SigLIP的sigmoid损失)高效迁移至地球观测领域,从而为地理空间分析、环境监测及灾害响应提供语义驱动的检索基础。该数据集已影响力延伸至ICLR 2026 Workshop的ML4RS Tutorial Track,推动了遥感影像与文本、图像间联合表征的标准化进程。
当前挑战
该数据集面临双重挑战:在领域问题层面,遥感影像的空间异质性(如不同地形、天气影响下的光谱变异)与多尺度特征(从城市级到像素级)对视觉编码器的泛化能力提出严苛要求,传统自然图像预训练模型(如SigLIP)在捕捉地物细微纹理、阴影效应及大气干扰时存在语义偏差;在构建过程中,预处理需平衡Sentinel-2 L2A数据的辐射定标(2.5倍归一化)与近邻插值失真,且RGB波段舍弃了多光谱信息导致潜在特征丢失。此外,GeoParquet格式的嵌入存储需兼容地理坐标重投影(UTM转WGS-84)的精度损失,而1152维高维向量在亿级规模下的近邻搜索效率与内存开销亦构成工程挑战。
常用场景
经典使用场景
Core-S2RGB-249k-SigLIP数据集的核心用途在于为遥感图像与自然语言之间的跨模态检索提供强大的视觉表征基准。该数据集基于Sentinel-2卫星L2A等级的真彩色影像,经由SigLIP模型(一种采用sigmoid损失函数进行对比学习的视觉Transformer)编码为1152维的高密度嵌入向量。研究者常借助该数据集的嵌入特征与对应的地理元数据(如经纬度、采集时间),构建大规模卫星图像检索系统,实现以图搜图或基于文本描述的高效空间场景匹配。
衍生相关工作
围绕Core-S2RGB-249k-SigLIP数据集,学术界已衍生出一系列有影响力的研究工作。其中,EarthEmbeddingExplorer作为一项代表性成果,构建了一套端到端的Web应用系统,支持用户通过自然语言或示例图像在全球卫星影像库中进行跨模态检索,该工作获得了ICLR 2026 ML4RS研讨会的认可。此外,该数据集所依托的Major-TOM框架也催生了对大规模遥感嵌入表征可扩展性的深入探讨,推动了GeoParquet格式在地理空间嵌入存储中的标准化应用。这些衍生工作不仅验证了SigLIP编码器在遥感领域的迁移能力,也激发了后续研究者探索结合气象、雷达等多模态遥感数据的统一嵌入方法,持续拓展地球观测数据分析的边界。
数据集最近研究
最新研究方向
Core-S2RGB-249k-SigLIP作为融合视觉语言模型的遥感影像嵌入数据集,其最新研究聚焦于利用SigLIP模型对全球哨兵2号卫星影像进行语义嵌入表征,从而实现高效的地理空间跨模态检索。该数据集配合EarthEmbeddingExplorer等交互式工具,为地球观测领域引入了一种全新的数据查询范式——用户可通过自然语言描述直接检索卫星影像,极大降低了遥感数据的获取门槛。这一方向与2025—2026年地学大模型、多模态检索系统的热潮紧密相连,显著推动了卫星影像在气候变化监测、土地利用分类及地理信息自动化提取等热点场景中的落地应用,有望成为连接视觉基础模型与地球科学任务的关键桥梁。
以上内容由遇见数据集搜集并总结生成


