MattiaL/tapir-cleaned-116k
收藏Hugging Face2023-05-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/MattiaL/tapir-cleaned-116k
下载链接
链接失效反馈官方服务:
资源简介:
Tapir-Cleaned数据集是从DAISLab数据集中提取的IFTTT规则,经过清洗、评分和调整,用于指令微调。数据集包含116,862个高质量的指令数据,主要用于语言模型的指令微调,以提高其遵循指令的能力。数据集的语言主要为英语,数据字段包括instruction、input、output、score和text。数据集的结构包括训练集,大小为116,862个实例。数据集的许可信息为CC BY-NC 4.0。
Tapir-Cleaned数据集是从DAISLab数据集中提取的IFTTT规则,经过清洗、评分和调整,用于指令微调。数据集包含116,862个高质量的指令数据,主要用于语言模型的指令微调,以提高其遵循指令的能力。数据集的语言主要为英语,数据字段包括instruction、input、output、score和text。数据集的结构包括训练集,大小为116,862个实例。数据集的许可信息为CC BY-NC 4.0。
提供机构:
MattiaL
原始信息汇总
Tapir-Cleaned 数据集概述
数据集描述
Tapir-Cleaned 是 DAISLab 数据集的一个修订版本,专注于 IFTTT 规则的指令微调。该数据集经过彻底清洗、评分和调整,以适应指令微调的需求。
数据集内容
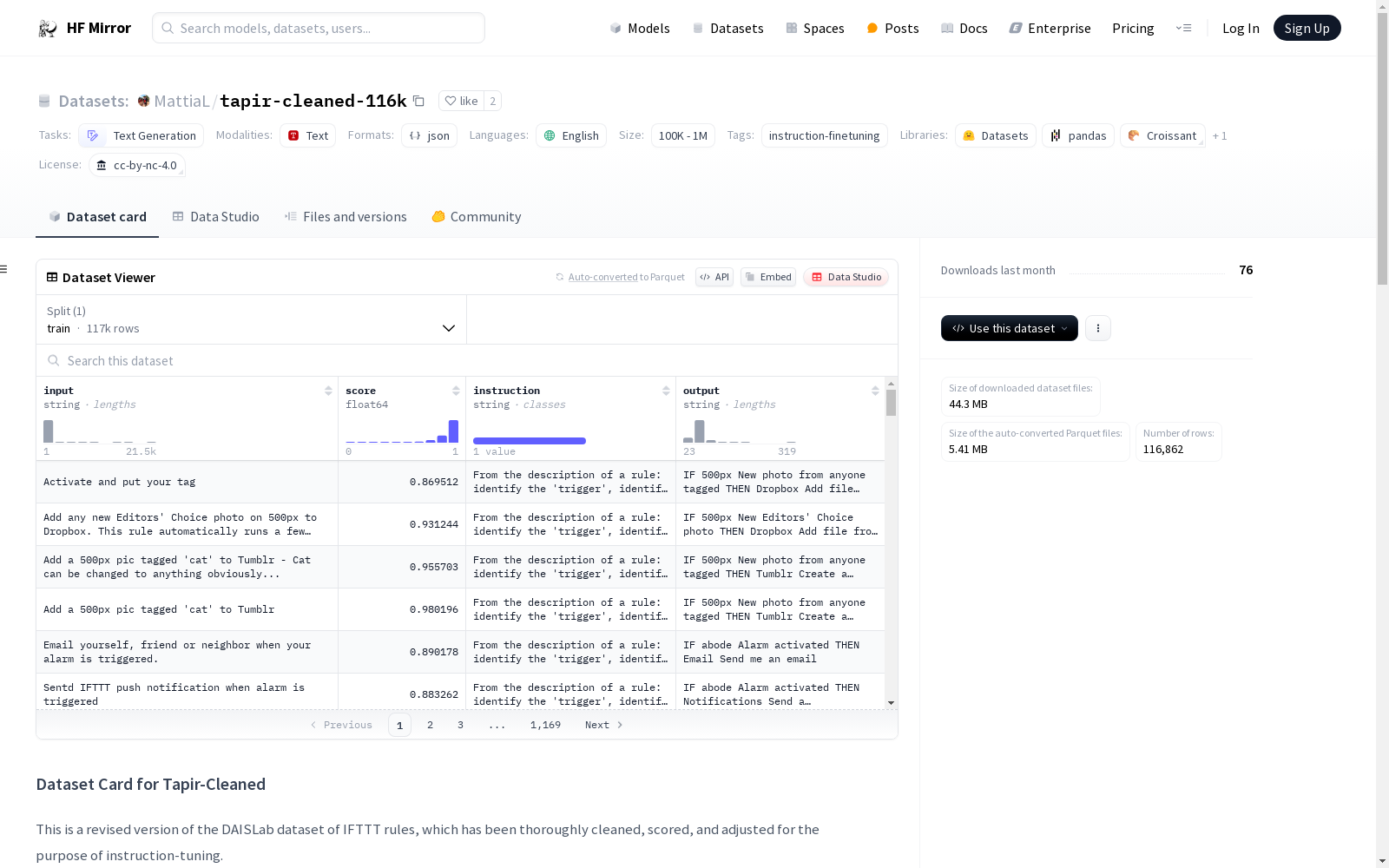
Tapir 是从 IFTTT 平台提取的 242,480 个食谱的子集,经过清洗后,精选出 116,862 个高质量食谱。这些数据特别适用于训练语言模型遵循指令,以提高其性能。
数据集结构
数据实例
每个数据实例包含以下字段:
instruction: 描述模型应执行的任务。input: 任务的上下文或输入,每个输入都是唯一的。output: 从原始 Tapir 数据集中获取的答案,格式化为 IFTTT 食谱。score: 通过 BertForNextSentencePrediction 获得的关联分数。text: 使用 Alpaca 作者的数据发布模板格式化的指令、输入和输出。
数据分割
train: 116,862 个实例。
语言
数据主要使用英语(BCP-47 en)。
许可证
数据集根据 Creative Commons NonCommercial (CC BY-NC 4.0) 许可提供。
引用信息
@misc{tapir, author = {Mattia Limone, Gaetano Cimino, Annunziata Elefante}, title = {TAPIR: Trigger Action Platform for Information Retrieval}, year = {2023}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {url{https://github.com/MattiaLimone/ifttt_recommendation_system}}, }
搜集汇总
数据集介绍
构建方式
在信息检索与自然语言处理领域,MattiaL/tapir-cleaned-116k数据集的构建采用了对原始DAISLab数据集的深度清洗、评分及调整的方式,旨在为指令微调提供优质的数据基础。该数据集从DAISLab数据集中提炼出242,480条IFTTT规则,经过严格筛选,去除了冗余与不一致的规则,最终形成包含116,862条高质量指令数据的集合,以供语言模型进行指令微调训练。
特点
该数据集的特点在于其高质量与针对性。它不仅涵盖了从IFTTT平台提取的规则,还通过相关性评分机制,对描述-规则对进行了优化,确保了数据集中每一条规则的适用性和准确性。特别是那些相关性评分超过0.75的描述-规则对,被视为具有足够质量,可用于进一步的指令微调分析。此外,数据集的构建充分考虑了版权问题,采用Creative Commons NonCommercial 4.0许可,保障了数据的合法使用。
使用方法
使用该数据集时,用户可以直接利用其提供的训练集进行语言模型的指令微调训练。数据集的结构包括五个字段:指令描述、输入上下文、输出答案、相关性评分以及包含所有信息的文本格式。这些字段为模型训练提供了详细的上下文和目标输出,有助于模型更精确地理解和执行指令。用户在获取数据集后,应遵循相应的许可协议,并在研究和应用中正确引用数据集来源。
背景与挑战
背景概述
在信息检索与自然语言处理领域,指令微调是提升语言模型性能的关键技术之一。Tapir-Cleaned数据集,创建于2023年,是由Mattia Limone、Gaetano Cimino和Annunziata Elefante等研究人员基于DAISLab数据集改进而来的。该数据集的核心研究问题是优化语言模型对指令的理解与执行能力。通过对IFTTT平台上提取的242,480条规则进行深度清洗和筛选,最终形成了包含116,862条高质量指令的数据集,对于指令微调练习具有极高的价值。该数据集的推出,为语言模型在遵循指令并实现卓越性能方面提供了重要支撑,对相关领域产生了显著影响。
当前挑战
Tapir-Cleaned数据集在构建过程中主要面临的挑战包括数据清洗和筛选的准确性,以及如何确保指令与规则之间的高度相关性。数据清洗需要去除冗余和不一致的规则,以确保数据质量。此外,构建过程中还需对描述-规则对进行相关性评分,以便识别最适宜的指令微调描述-规则对,这一步骤的准确性直接影响到后续模型微调的效果。如何在海量的规则中高效实现这些目标,是构建该数据集时需要解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,尤其是指令微调的研究中,Tapir-Cleaned数据集以其高质量、经过精确校准的指令数据,成为一项不可或缺的资源。该数据集最为经典的使用场景在于,通过对语言模型进行指令微调,使其能够更加准确地理解和执行人类的指令,从而在诸如自动编程、智能对话系统等领域展现出卓越的性能。
解决学术问题
Tapir-Cleaned数据集的构建,有效解决了学术研究中如何提升语言模型对复杂指令理解与执行准确性的问题。通过去除冗余和矛盾的规则,并引入相关性评分,该数据集为研究人员提供了一种精确评估模型性能的标准,进而促进了指令微调技术的发展,对于提升人工智能的智能水平具有重要的学术意义和影响。
衍生相关工作
基于Tapir-Cleaned数据集,学术界涌现出了大量相关的研究工作,包括但不限于指令微调算法的改进、模型性能评估标准的建立,以及新型智能系统的设计与实现。这些工作不仅推动了自然语言处理技术的进步,也为智能系统的商业化应用提供了坚实的理论基础和技术支持。
以上内容由遇见数据集搜集并总结生成


