JF-ICR
收藏Hugging Face2026-03-09 更新2026-03-10 收录
下载链接:
https://huggingface.co/datasets/TheFinAI/JF-ICR
下载链接
链接失效反馈官方服务:
资源简介:
JF-ICR(日本金融隐式承诺识别)是一个用于评估日本投资者问答中隐式承诺和拒绝识别的基准数据集。该数据集包含来自4家公司在3年内的94个单轮问答对,标注为5种隐式立场类别,用于区分高语境话语中的同意、含糊和拒绝。数据集旨在解决日本金融沟通中间接表达和隐式承诺理解的挑战,其中拒绝通常通过语用线索而非明确陈述传达。
数据集结构包括每个实例的四个字段:问题(日语金融问题)、回答(公司回应)、标签(意图标签,如+2表示强烈承诺,-2表示强烈拒绝)和任务ID(唯一标识符)。数据来源为日本上市公司公开披露的财报电话会议、股东会议问答和财务简报会议记录。
数据集创建过程包括详细的注释指南制定、双专家独立注释、仲裁和高质量验证,确保注释的高可靠性(Macro-F1: 0.9215, Cohen's κ: 0.8769)。数据集适用于自然语言处理任务,特别是隐式意图识别和金融沟通分析。
注意事项包括公司代表性有限(4家公司)、时间范围特定(2023-2026年)、数据规模较小(94例)以及对日语高语境沟通的理解要求。数据集不包含个人或敏感信息,所有数据均来自公开披露。
JF-ICR (Japanese Financial Implicit Commitment Recognition) is a benchmark dataset for evaluating implicit commitment and rejection recognition in Japanese investor Q&A. It contains 94 single-turn Q&A pairs from 4 companies over 3 years, annotated with 5 implicit stance categories to distinguish agreement, ambiguity and rejection in high-context discourse. This dataset aims to address the challenge of understanding indirect expressions and implicit commitments in Japanese financial communication, where rejection is often conveyed through pragmatic cues rather than explicit statements.
The dataset structure includes four fields for each instance: Question (Japanese financial question), Response (company's reply), Label (intent label, e.g., +2 for strong commitment, -2 for strong rejection) and Task ID (unique identifier). The data is sourced from publicly disclosed earnings conference calls, shareholder meeting Q&A and financial briefing transcripts of Japanese listed companies.
The dataset creation process includes the development of detailed annotation guidelines, dual expert independent annotation, arbitration and high-quality validation, ensuring high annotation reliability (Macro-F1: 0.9215, Cohen's κ: 0.8769). This dataset is suitable for natural language processing tasks, especially implicit intent recognition and financial communication analysis.
Notable considerations include limited company representativeness (only 4 companies), a specific time range (2023-2026), small data scale (94 instances) and the requirement for understanding Japanese high-context communication. The dataset does not contain personal or sensitive information, and all data is sourced from public disclosures.
提供机构:
The Fin AI
创建时间:
2026-03-09
原始信息汇总
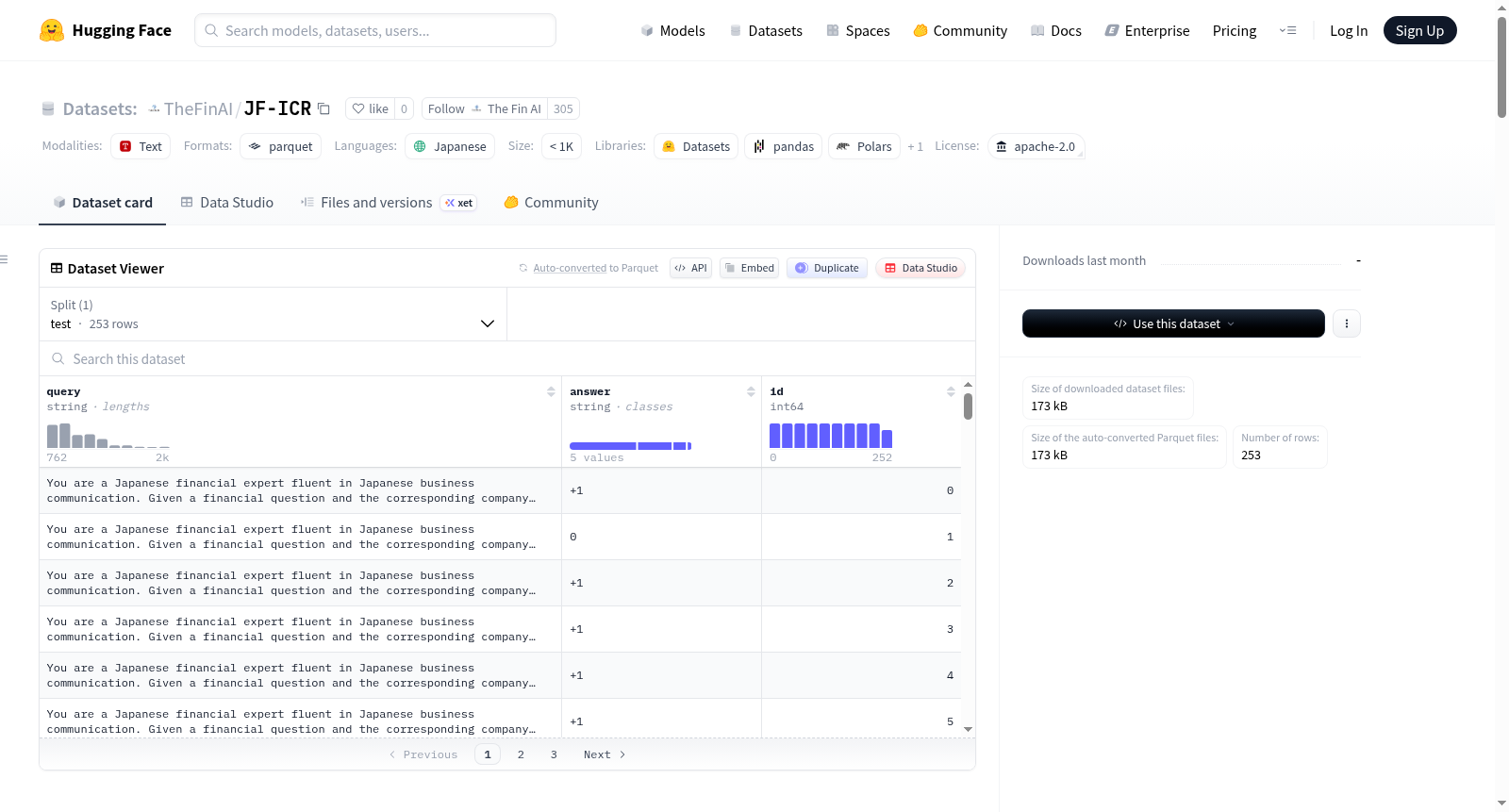
JF-ICR 数据集概述
数据集基本信息
- 数据集名称: JF-ICR (Japanese Financial Implicit Commitment Recognition)
- 简介: 一个用于评估日语投资者问答中隐含承诺与拒绝识别的基准数据集。该数据集包含来自4家公司、跨时3年的94个单轮问答对,标注为5种隐含立场类别,用于区分高语境话语下的同意、模糊和拒绝。它旨在解决日语金融沟通中间接表达和隐含承诺的理解难题。
- 语言: 日语 (ja)
- 许可证: Apache License 2.0
- 数据量: 94 个实例
- 数据划分: 仅包含测试集 (94 个示例)
数据集结构与内容
数据实例
每个实例包含以下字段:
question: 投资者或分析师提出的日语财务问题。response: 公司相应的日语回复。label: 标注的意图标签,取自集合 {+2, +1, 0, -1, -2}。task_id: 实例的唯一标识符。
标签定义
+2: 强烈承诺+1: 微弱或有条件的承诺0: 中立或模糊意图-1: 微弱拒绝-2: 强烈拒绝
数据集创建
来源数据
- 来源类型: 来自真实世界、公开可用的日本公司披露文件。
- 具体来源:
- 主要日本公司的财报电话会议/投资者简报问答记录。
- 股东大会问答材料。
- 财务业绩说明会(決算説明会)问答环节。
- 数据筛选: 经过人工精心筛选,仅保留专注于单一主题的单轮问答对,排除了多部分问题、交织的后续问题或需要更广泛对话背景的交流。
- 来源生产者: 日本上市公司通过官方渠道(如公司投资者关系网站和日本金融厅运营的官方电子披露系统EDINET)发布的公开披露信息。
标注过程
- 标注者: 由2名具有丰富行业经验的日语母语水平金融专家进行独立标注。
- 标注流程:
- 与日本金融专家合作制定详细的标注指南。
- 通过预标注轮次迭代完善指南。
- 双人独立标注。
- 由高级专家进行裁决以解决分歧。
- 使用Macro-F1、Cohens κ和Krippendorffs α衡量标注者间一致性以确保可靠性。
- 标注理念: 任务侧重于管理层回复中所表达的承诺程度,而非问题的表面意图或事实正确性。仅当回复表达了强烈、清晰、明确且确定的同意或拒绝时,才分配±2标签。
- 标注者间一致性 (结果表明高度一致):
- Macro-F1: 0.9215
- Cohens κ: 0.8769
- Krippendorffs α: 0.8768
使用注意事项
潜在偏见与局限性
- 公司代表性: 数据集涵盖3年内的4家公司,可能无法代表不同行业和公司规模的日本企业沟通风格的完整多样性。
- 时间偏差: 数据时间跨度为2023-2026年,可能反映了该时期特有的沟通模式。
- 问题类型: 数据集侧重于面向投资者的问答,可能强调某些特定类型的问题和回复。
- 标注主观性: 尽管标注者间一致性高,但标注本质上仍具有主观性,特别是在涉及模糊或间接拒绝的边缘案例中。
- 规模有限: 数据集包含94个示例,可能限制某些评估场景的统计效力。
- 单轮焦点: 仅包含单轮问答对,排除了在某些场景下可能相关的多轮对话上下文。
- 高语境依赖性: 数据集要求理解日语高语境沟通规范,这对于主要基于低语境语言训练的模型可能具有挑战性。
社会影响
- 通过支持对金融沟通中语用理解和隐含意图识别的评估,JF-ICR有助于日本金融NLP的研究。
- 该能力对于跨境金融很重要,因为截至2024财年,外国投资者持有日本上市股票市场价值的32.4%。
- 该数据集支持开发能够更好理解日本企业沟通的系统,可能提高国际投资者和分析师的可访问性。
个人与敏感信息
- 数据集不包含个人或敏感信息。所有数据均源自已公开的公开公司披露和投资者沟通材料。公司名称和具体财务细节被保留,因为它们对于理解问答交流的背景至关重要。
其他信息
- 数据集维护者: The Ebisu Benchmark Team
- 引用信息: bibtex @misc{ebisu2025, title={EBISU: Benchmarking Large Language Models in Japanese Finance}, author={[Authors]}, year={2025}, eprint={[arXiv number]}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/[number]}, }
注意: 请在该论文正式发表后查阅其完整引用信息。
搜集汇总
数据集介绍
构建方式
在金融自然语言处理领域,JF-ICR数据集的构建体现了对日本高语境沟通范式的深度解析。其源数据精选自日本上市公司公开披露的投资者问答材料,包括业绩说明会与股东大会的实录文本。为确保标注的精确性,构建过程采用了严谨的多阶段人工标注流程:首先由具备深厚金融背景的日语母语级专家制定详尽的标注准则,随后通过预标注迭代优化;每个实例均经过两位专家的独立标注,并由资深专家对分歧进行最终裁定。这一流程辅以宏平均F1分数、科恩卡帕系数等量化指标验证,确保了标注结果的高一致性与可靠性,从而为隐式承诺识别任务奠定了扎实的数据基础。
使用方法
该数据集主要服务于大型语言模型在日语金融隐式承诺识别任务上的评估。使用者可通过加载数据集,获取包含问题、公司回应及五级意图标签的实例。鉴于数据集仅提供测试分割,建议将其用于模型能力的零样本或少样本评估,通过准确率等指标衡量模型对隐式意图的推断性能。在使用时,需注意数据的高语境依赖性,并考虑其公司代表性与时间范围可能带来的局限性,以确保评估结论的稳健性。数据集采用Apache 2.0许可,使用时请遵循相应的引用规范。
背景与挑战
背景概述
在金融自然语言处理领域,理解高语境文化下的间接表达是一项关键挑战。JF-ICR数据集由Ebisu Benchmark Team于2025年创建,旨在评估大型语言模型对日语财务沟通中隐含承诺与拒绝的识别能力。该数据集聚焦于投资者问答场景,涵盖了四家日本上市公司跨越三年的94个单轮问答对,并标注为五种隐含立场类别。其核心研究问题在于解析日语财务披露中通过语用线索而非明确陈述所传达的意图,填补了现有基准测试在语用意图推理方面的空白,对提升跨文化金融信息理解具有重要影响力。
当前挑战
JF-ICR数据集所针对的领域挑战在于精准识别日语高语境话语中的隐含承诺与拒绝,这要求模型超越表面语义,深入理解文化特定的语用规则。在构建过程中,团队面临多重挑战:数据需从真实的公司披露文件中精心筛选,仅保留主题单一的单轮问答以确保标注清晰性;标注工作依赖资深金融专家,需制定详尽指南以处理模糊的间接表达案例,并通过多轮预标注与裁决来保证标注一致性。此外,数据规模有限、公司覆盖范围较窄以及高语境依赖性,也为数据集的泛化能力带来了固有局限。
常用场景
经典使用场景
在日语金融自然语言处理领域,JF-ICR数据集为评估大型语言模型识别隐式承诺与拒绝的能力提供了基准。该数据集聚焦于投资者问答场景,通过标注管理层回应的五种隐含立场,模拟了日本企业沟通中常见的高语境、间接表达方式。研究人员利用这一数据集,能够系统测试模型在理解日语金融文本中微妙语用线索方面的性能,从而推动对话语用学与计算金融的交叉研究。
解决学术问题
JF-ICR数据集主要解决了金融文本分析中隐式意图识别的学术挑战。传统情感分析或显式问答基准难以捕捉日语高语境沟通中常见的间接拒绝或模糊承诺,该数据集通过精细的意图标注,为研究隐式立场推断、语用推理以及跨文化金融沟通理解提供了实证基础。其意义在于填补了日语金融自然语言处理中语用评估的空白,促进了语言模型在复杂真实场景下的鲁棒性研究。
实际应用
在实际应用中,JF-ICR数据集可服务于智能金融分析工具的研发,例如自动解析企业财报问答中的管理层态度,辅助国际投资者跨越语言与文化障碍理解日本公司披露信息。此外,该数据集也能用于构建风险预警系统,通过识别企业回应中的隐式拒绝或承诺变化,为投资决策提供更深入的语用层面洞察,提升跨境金融信息处理的效率与准确性。
数据集最近研究
最新研究方向
在金融自然语言处理领域,JF-ICR数据集聚焦于日语高语境沟通中隐含承诺与拒绝的识别,为大型语言模型在跨文化金融场景下的语用理解能力评估提供了基准。前沿研究围绕模型对间接表达和微妙意图的推理展开,结合日本企业披露中常见的婉转表述特点,探索语义与语用特征的融合表示。该数据集呼应了全球投资者对日本市场信息透明度日益增长的需求,尤其在外国持股比例攀升的背景下,推动着面向金融文本的细粒度情感分析、跨语言迁移学习及可解释人工智能技术的发展,旨在提升自动化系统对复杂商业话语的解析精度,助力国际投资决策。
以上内容由遇见数据集搜集并总结生成


