PubMedQA
收藏arXiv2019-09-13 更新2024-06-21 收录
下载链接:
https://pubmedqa.github.io
下载链接
链接失效反馈官方服务:
资源简介:
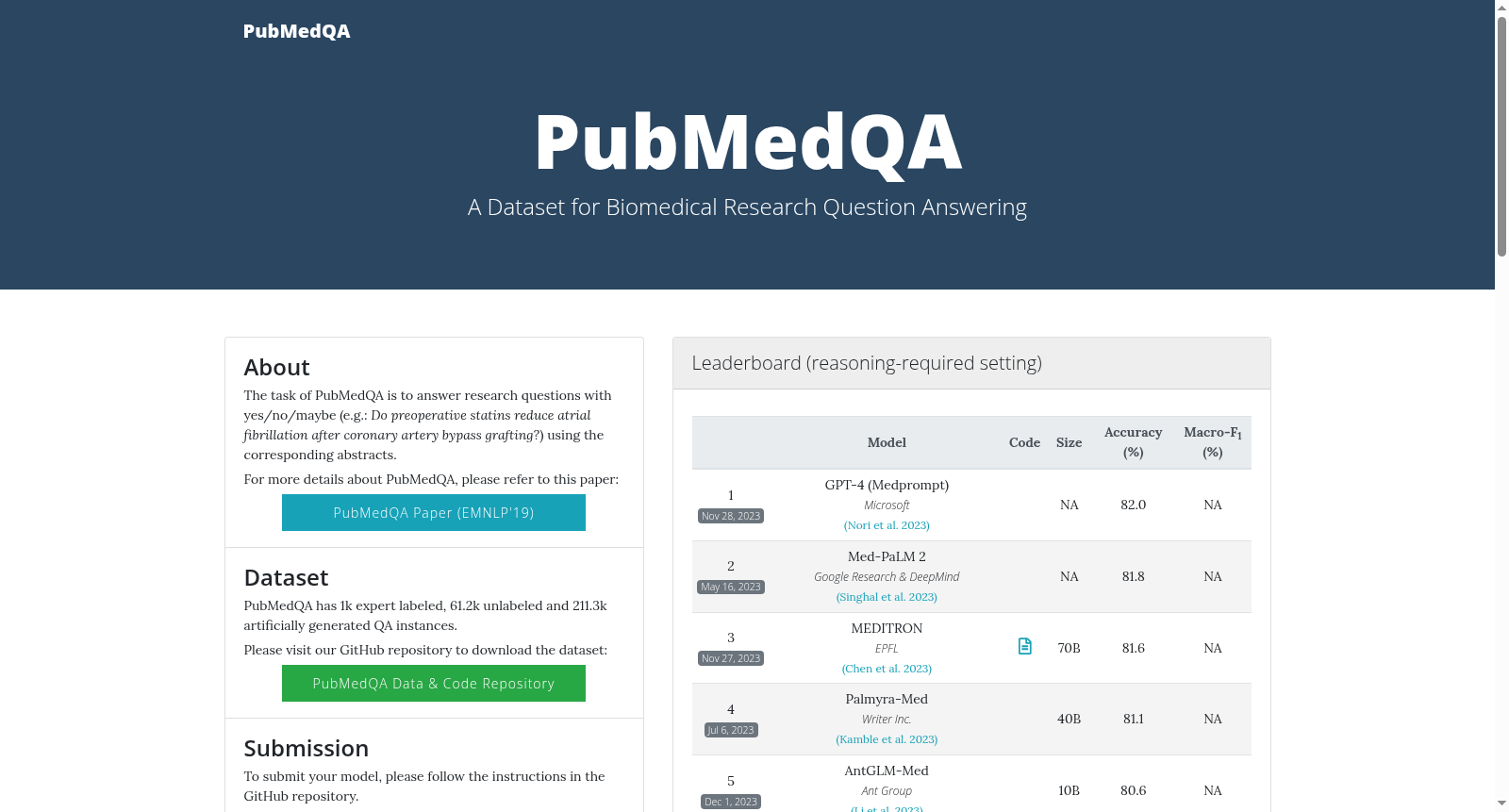
PubMedQA是一个专为生物医学研究问题回答设计的数据集,由卡内基梅隆大学等机构的研究人员开发。该数据集包含约273500条数据,分为1k专家标注实例、61.2k无标注实例和211.3k人工生成实例。PubMedQA旨在通过yes/no/maybe回答研究问题,如:“术前使用他汀类药物是否能减少冠状动脉旁路移植术后的心房颤动?”数据集内容涵盖广泛的生物医学研究领域,特别是需要对生物医学研究文本中的定量内容进行推理的问题。PubMedQA的应用领域包括提高机器阅读理解模型的科学推理能力,尤其是在处理生物医学文本时。
PubMedQA is a dedicated dataset for biomedical research question answering, developed by researchers from Carnegie Mellon University and other research institutions. It comprises approximately 273,500 instances, categorized into three subsets: 1,000 expert-annotated examples, 61,200 unannotated examples, and 211,300 human-generated examples. The core task of PubMedQA is to answer research questions with yes/no/maybe responses, such as: "Does preoperative use of statins reduce the risk of atrial fibrillation after coronary artery bypass grafting?" The dataset covers a wide range of biomedical research fields, particularly questions that require reasoning about quantitative content in biomedical research texts. Its application areas include enhancing the scientific reasoning capabilities of machine reading comprehension models, especially when processing biomedical texts.
提供机构:
卡内基梅隆大学
创建时间:
2019-09-13
搜集汇总
数据集介绍
构建方式
在生物医学信息学领域,构建高质量问答数据集对推动自然语言理解技术至关重要。PubMedQA的构建充分利用了PubMed数据库中结构化摘要的固有特性,其核心方法是从PubMed文献中筛选出以疑问句为标题且具备结构化摘要的论文。具体而言,研究团队首先收集了约12万篇符合上述条件的文章,将标题作为问题,摘要中除结论外的部分作为上下文,结论部分则作为长答案。在此基础上,通过专家标注流程,对1000个实例进行了精细的是/否/可能答案标注,构建了标注子集PQA-L;同时,利用启发式规则自动识别并保留了约6.12万个未标注的是/否/可能可回答实例,形成未标注子集PQA-U;此外,通过将陈述式标题转化为疑问句并基于否定状态自动生成答案,构建了包含21.13万个实例的人工生成子集PQA-A,从而形成了一个规模庞大且结构层次分明的数据集。
使用方法
使用PubMedQA时,研究者主要关注在推理必需设定下的模型性能评估,即模型仅能依据问题和上下文预测是/否/可能答案。数据集的标准评估指标是在PQA-L测试集上的准确率与宏平均F1值。为充分利用数据,可采用多阶段微调策略:首先在人工生成的PQA-A子集上进行预训练;随后,利用推理自由设定在PQA-A和PQA-L上训练模型,为未标注的PQA-U子集生成伪标签;接着,在伪标注的PQA-U上进行微调;最后,在专家标注的PQA-L上完成最终微调。训练过程中,长答案可作为额外的监督信号,例如通过预测其词袋统计量来辅助模型学习。这种分层使用方法有助于模型逐步适应从噪声数据到高质量标注数据的过渡,有效提升其在复杂生物医学推理任务上的表现。
背景与挑战
背景概述
在生物医学自然语言处理领域,研究型问答系统的发展长期受限于高质量标注数据的稀缺。2019年,由匹兹堡大学、卡内基梅隆大学及谷歌人工智能团队联合推出的PubMedQA数据集,标志着该领域迈入新阶段。该数据集从PubMed摘要中构建,核心研究问题聚焦于对生物医学研究文本进行量化推理,以回答是/否/可能类型的研究问题。其创新性在于首次要求模型深入理解文本中的定量内容,如统计结果与实验对比,从而模拟科学推理过程。PubMedQA包含专家标注、未标注及自动生成的三类子集,总计超过27万个问答实例,迅速成为评估生物医学阅读理解与推理能力的关键基准,推动了如BioBERT等领域专用模型的优化与应用。
当前挑战
PubMedQA面临的挑战主要体现在两个方面:其一,在领域问题层面,该数据集旨在解决生物医学研究问答中的复杂推理问题,尤其是对文本内定量信息(如统计数据、实验组比较)的理解与推断,这要求模型超越简单的实体抽取,进行深层次的科学逻辑分析。当前最佳模型准确率仅为68.1%,远低于人类表现的78.0%,揭示出模型在量化推理与上下文整合方面存在显著不足。其二,在构建过程中,数据收集依赖PubMed中结构化摘要的可用性,但仅部分文章符合要求;自动生成子集虽扩大规模,却引入标签噪声与分布偏差,而专家标注成本高昂,导致标注数据规模有限,制约了监督学习的效能。
常用场景
经典使用场景
在生物医学自然语言处理领域,PubMedQA数据集常被用作评估模型对研究文献进行科学推理能力的基准。该数据集通过从PubMed摘要中提取问题与上下文,要求模型基于结构化摘要内容回答是/否/可能类型的研究问题,例如“术前他汀类药物是否能减少冠状动脉搭桥术后心房颤动的发生?”。这一场景模拟了医学研究者快速从海量文献中获取结论性答案的需求,推动了机器阅读理解在专业领域的深度应用。
解决学术问题
PubMedQA有效解决了生物医学问答研究中缺乏大规模、需复杂推理数据集的学术难题。传统生物医学QA数据集如BioASQ规模有限且多为事实型问题,而PubMedQA通过整合专家标注与自动生成实例,首次要求模型对定量内容进行推理,填补了该领域对科学论证能力评估的空白。其意义在于为开发能够理解临床研究统计结果与结论关联的智能系统提供了关键资源,促进了证据导向医学与人工智能的交叉研究。
实际应用
在实际应用中,PubMedQA可作为临床决策支持系统的核心组件,帮助医生或研究人员快速从科学文献中提取结论性证据。例如,在循证医学实践中,系统可自动分析新发表研究摘要,回答特定干预措施的有效性问题,从而辅助制定治疗指南或优化临床方案。此外,该数据集也用于开发学术文献智能检索工具,提升生物医学信息获取的精度与效率,减轻专业人员在文献综述中的负担。
数据集最近研究
最新研究方向
在生物医学自然语言处理领域,PubMedQA数据集作为首个专注于研究型问答的基准,其前沿研究方向正聚焦于提升模型对复杂定量内容的推理能力。当前研究热点包括利用多阶段微调策略结合领域预训练模型如BioBERT,并引入长答案作为辅助监督信号,以应对数据集中大量需数值解读的上下文。这一方向不仅推动了证据医学的智能化发展,也为机器理解科学文本的深层逻辑设立了新的挑战与机遇。
相关研究论文
- 1PubMedQA: A Dataset for Biomedical Research Question Answering卡内基梅隆大学 · 2019年
以上内容由遇见数据集搜集并总结生成


