lemexp-commercial-llm-experiment-results
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/yalhessi/lemexp-commercial-llm-experiment-results
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个用于评估语言模型在自动定理证明任务中性能的基准数据集,特别关注于Isabelle定理证明器环境中的引理对象生成。数据集包含多个配置,分别对应不同的模型(如DeepSeek-1.3b、DeepSeek-6.7b和Llama)和任务变体(完整引理对象、无定义完整引理对象、小型引理对象)。每个配置包含139个测试样本,每个样本提供了定理证明相关的上下文信息,包括理论文件、引理名称、引理命令、符号、类型、定义、模板以及期望的输出(引理对象)。数据集的核心是模型生成的预测结果及其评估指标,涵盖了贪婪解码和集束搜索两种生成策略。评估指标包括基于字符串的Levenshtein距离分数,以及通过Isabelle验证的布尔匹配结果和成功计数。该数据集适用于研究形式化方法、自动定理证明、代码生成以及语言模型在结构化逻辑推理任务中的能力评估。
This dataset is a benchmark dataset for evaluating the performance of language models on automated theorem proving tasks, with a specific focus on lemma object generation in the Isabelle theorem prover environment. The dataset includes multiple configurations corresponding to different models (e.g., DeepSeek-1.3b, DeepSeek-6.7b, and Llama) and task variants (full lemma objects, complete lemma objects without definitions, small lemma objects). Each configuration contains 139 test samples, with each sample providing context information related to theorem proving, including theory files, lemma names, lemma commands, symbols, types, definitions, templates, and the expected output (lemma objects). The core of the dataset consists of the model-generated prediction results and their evaluation metrics, covering two generation strategies: greedy decoding and beam search. The evaluation metrics include string-based Levenshtein distance scores, as well as Isabelle-verified boolean matching results and success counts. This dataset is applicable to research on formal methods, automated theorem proving, code generation, and the evaluation of language models' capabilities in structured logical reasoning tasks.
创建时间:
2026-05-10
搜集汇总
数据集介绍
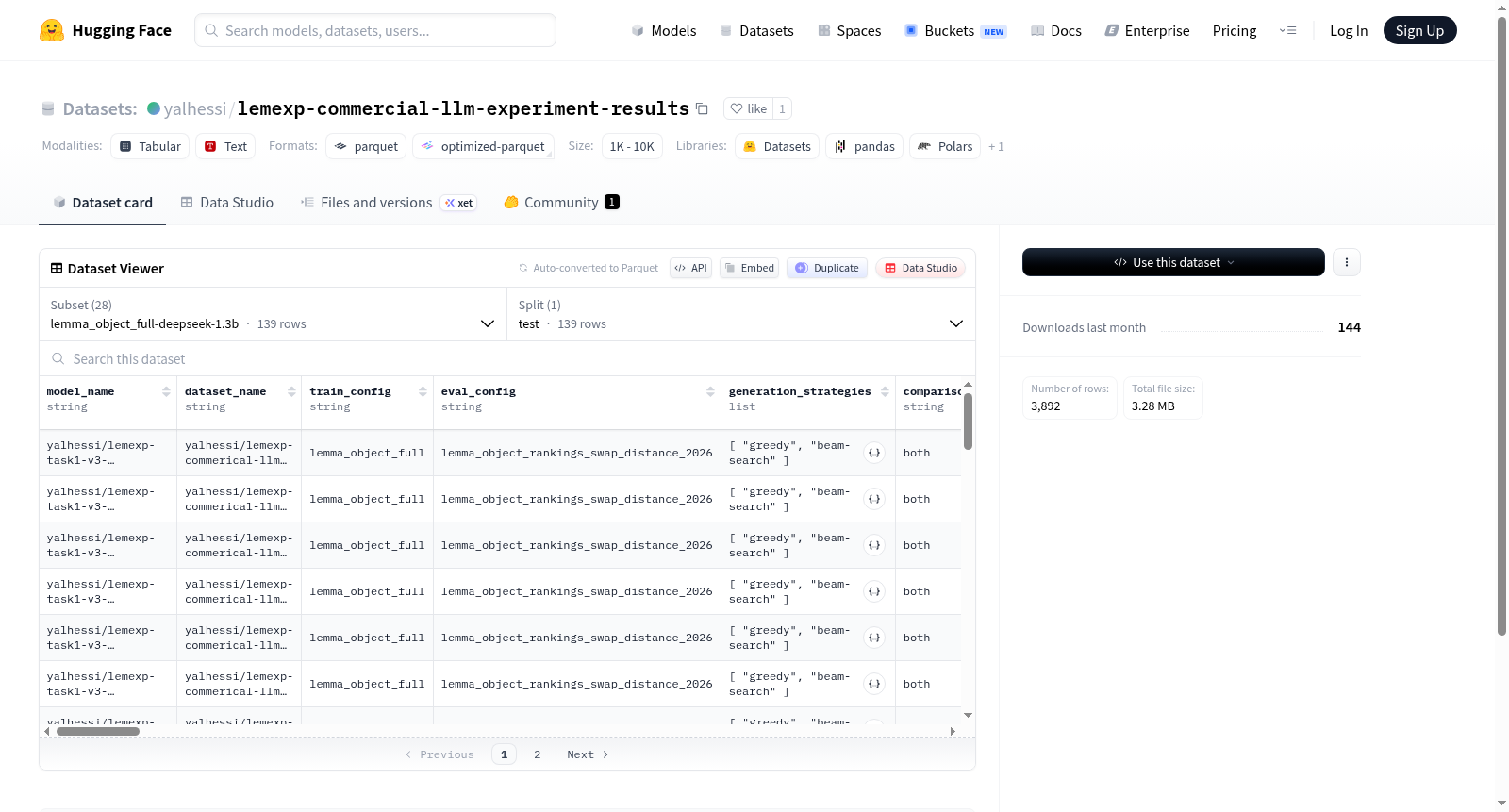
构建方式
在形式化定理证明领域,大语言模型辅助Isabelle代码生成正成为研究热点。该数据集通过系统化实验范式构建,选取DeepSeek-1.3b、DeepSeek-6.7b及Llama系列模型,针对Isabelle理论文件中lemma对象的补全任务进行评测。每条样本包含完整的定理上下文(symbols、types、defs等元信息)与模型输入输出,并同时采用贪婪搜索与束搜索两种解码策略生成预测结果。实验设计了lemma_object_full、lemma_object_small及lemma_object_nodefs三种配置变体,以探究完整上下文、精简上下文及剔除定义信息对模型性能的影响。每一预测结果均通过Levenshtein距离与Isabelle验证器双重判定成功与否,从而构建了多维度、可复现的大模型定理证明评估基准。
使用方法
研究者可通过HuggingFace Datasets库按配置名称加载具体实验子集,例如使用load_dataset('lemexp-commercial-llm-experiment-results', 'lemma_object_full-deepseek-1.3b')获取DeepSeek-1.3b在完整上下文场景下的全部139条测试样本。每条样本可直接提取input与output字段作为标准序列到序列任务的数据对,或利用any_success等聚合字段评估模型整体成功率。各配置间的预测与验证结果字段命名规范一致,便于编写脚本进行跨模型、跨策略、跨上下文配置的联合分析。数据集特别适合用于训练定理证明专用模型的微调基线,或作为评测基准,对比新模型与DeepSeek、Llama系列在Isabelle lemma生成任务上的形式化验证通过率。
背景与挑战
背景概述
lemexp-commercial-llm-experiment-results数据集诞生于大语言模型(LLM)在形式化定理证明领域迅猛发展的背景下,由致力于探索LLM在Isabelle交互式定理证明器中自动生成引理能力的研究团队创建。该数据集系统性地收录了DeepSeek-1.3B、DeepSeek-6.7B及LLaMA系列模型在不同配置(如贪婪搜索与束搜索)下针对Isabelle引理对象生成的实验结果,旨在揭示当前主流商用LLM在形式化数学推理中的表现边界。通过提供细粒度的引理预测、Levenshtein得分及Isabelle验证成功与否等结构化信息,该数据集为评估LLM在定理证明中的符号逻辑理解、模板遵循及语法精确性提供了标准化基准,推动了人工智能辅助数学证明的实证研究。
当前挑战
该数据集面临的挑战首先源于形式化定理证明领域的核心问题——LLM需要精确理解Isabelle的严格语法、类型系统及定义结构,并生成与现有理论库无缝衔接的合法引理,任何细微的符号或类型错误都将导致验证失败。此外,数据集的构建过程亦遭遇多重困难:不同模型(如DeepSeek系列与LLaMA)及解码策略(贪婪与束搜索)所产生的海量输出需要统一的结构化存储与管理,特别是对139个测试样本的多次重复实验可能导致数据冗余与对齐复杂性。同时,如何无偏地衡量生成引理的成功率(包括部分匹配与完全匹配)并排除随机性与模型过拟合的影响,也是确保数据集评估效度的重要挑战。
常用场景
经典使用场景
在人工智能与形式化验证交叉研究的浪潮中,lemexp-commercial-llm-experiment-results数据集承载着探索大语言模型在定理证明领域潜能的使命。该数据集最经典的用途在于评估不同规模的语言模型在伊莎贝尔(Isabelle)交互式定理证明器上生成引理对象(lemma object)的能力。通过记录贪心搜索与束搜索两种解码策略下的预测结果、莱文斯坦编辑距离得分以及伊莎贝尔环境验证的成功率,研究者能够系统性地对比DeepSeek-1.3B、DeepSeek-6.7B以及Llama系列模型在完整定义、无定义、小规模等不同设定下的表现。这为量化语言模型是否掌握了数学术语的语法结构与语义约束提供了坚实基准。
解决学术问题
该数据集精准回应了神经符号学习领域一个核心学术难题:如何客观衡量大语言模型对形式化数学语言的生成准确性与语义合规性。传统上,自然语言生成评价指标(如BLEU)难以捕捉形式化语言中严格的语法与逻辑约束。lemexp-commercial-llm-experiment-results通过集成伊莎贝尔验证器,将生成结果的成功与否定义为模型输出是否能被证明引擎接受为合法的引理对象。这一设计不仅解决了自动评判形式化数学文本生成质量的困境,而且为比较不同模型规模、解码策略以及上下文信息(如是否提供符号定义)对生成性能的影响提供了标准化框架,极大推动了形式化数学与机器学习融合研究的方法论建设。
实际应用
在实际应用中,该数据集催生了多项具有变革潜力的工具与系统。首先,它可直接用于训练与微调面向定理证明的代码语言模型,通过提供不同实验配置(如带定义与无定义)下的成功失败样本,帮助模型学习哪些形式的引理结构更容易被证明器接纳。其次,该评测图谱可集成到交互式证明辅助环境中,作为实时推荐模块,在用户编写证明时暗示最可能的引理填写候选,显著提升形式化验证的生产效率。此外,教育科技领域亦可借鉴该数据集,构建面向学生的定理证明练习反馈系统,通过对学生所写引理进行类似验证与评分,提供精准的纠错与指导。
数据集最近研究
最新研究方向
在形式化验证与人工智能的交叉领域中,lemexp-commercial-llm-experiment-results数据集为评估大型语言模型在定理证明辅助工具(如Isabelle)中的表现提供了关键基准。该数据集系统性地记录了DeepSeek与LLaMA等模型在引理对象生成任务上的贪婪搜索与束搜索结果,并对比了有无定义上下文(nodefs变体)的性能差异。其研究前沿聚焦于量化LLM在符号逻辑推理中的精确度与鲁棒性,通过Levenshtein距离与Isabelle自动匹配成功指标来衡量生成质量。这一方向与当前AI辅助形式化数学证明的热点紧密相连,旨在推动自动化定理证明的实用化进程,对于加速软件验证与数学发现具有深远意义。
以上内容由遇见数据集搜集并总结生成


