voice_deepfake_detection_dataset
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/gayaneyemishyan/voice_deepfake_detection_dataset
下载链接
链接失效反馈官方服务:
资源简介:
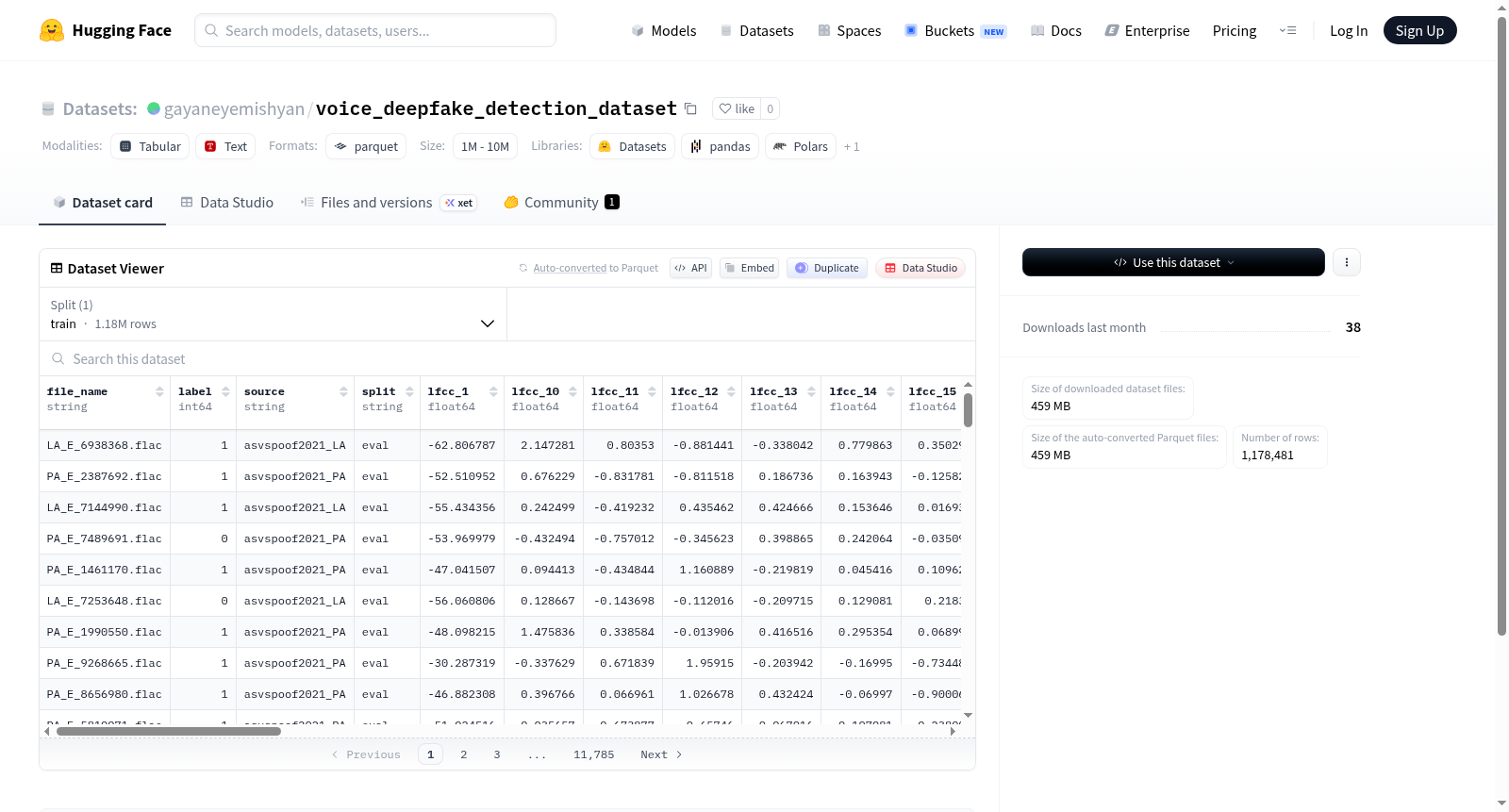
该数据集包含1,178,481个训练样本,每个样本包含多个音频特征,包括20个线性频率倒谱系数(LFCC)和20个梅尔频率倒谱系数(MFCC)。数据集还包含文件名、标签、来源和分割信息。尽管README未明确说明数据集的具体用途,但基于其特征结构,它可能适用于音频分类或相关任务。数据集仅包含一个训练分割,总大小为442,667,808字节,下载大小为458,761,298字节。
This dataset contains 1,178,481 training samples, each of which includes multiple audio features, specifically 20 Linear Frequency Cepstral Coefficients (LFCC) and 20 Mel-Frequency Cepstral Coefficients (MFCC). The dataset also includes file names, labels, source information, and split information. Although the README does not explicitly specify the specific intended use of this dataset, based on its feature structure, it may be suitable for audio classification or related tasks. This dataset only contains one training split, with a total size of 442,667,808 bytes and a download size of 458,761,298 bytes.
创建时间:
2026-04-06
原始信息汇总
数据集概述
基本信息
- 数据集名称: voice_deepfake_detection_dataset
- 托管地址: https://huggingface.co/datasets/gayaneyemishyan/voice_deepfake_detection_dataset
- 默认配置: default
数据集规模
- 下载大小: 458,761,298 字节
- 数据集大小: 442,667,808 字节
- 数据分割: 仅包含训练集(train)
- 训练集样本数量: 1,178,481 条
- 训练集大小: 442,667,808 字节
数据特征
数据集包含以下特征(列):
元数据特征
file_name: 字符串类型,文件名。label: 64位整数类型,标签。source: 字符串类型,数据来源。split: 字符串类型,数据分割标识。
音频特征
- LFCC特征: 包含
lfcc_1至lfcc_20,共20个线性频率倒谱系数特征,均为64位浮点数类型。 - MFCC特征: 包含
mfcc_1至mfcc_20,共20个梅尔频率倒谱系数特征,均为64位浮点数类型。
数据结构
- 数据文件路径:
data/train-*
搜集汇总
数据集介绍
构建方式
在语音伪造检测领域,voice_deepfake_detection_dataset的构建体现了对音频信号特征的深度提取与系统化组织。该数据集通过整合来自多个来源的语音样本,并利用先进的音频处理技术,为每个样本计算了20维的线性频率倒谱系数(LFCC)和梅尔频率倒谱系数(MFCC)。这些特征向量经过标准化处理,与对应的标签、来源及划分信息一同构成结构化数据,最终形成包含超过117万条样本的训练集,为模型训练提供了坚实的数值基础。
特点
该数据集的核心特点在于其丰富的声学特征表示与清晰的数据结构。每一音频样本均以20维LFCC和MFCC特征向量进行编码,这些特征能够有效捕捉语音信号的频谱特性,为区分真实与伪造语音提供了关键判别信息。数据集不仅标注了样本的类别标签,还记录了来源信息,便于研究者追溯数据生成背景。其庞大的样本规模与预先划分的训练集,为深度学习模型提供了充足的训练资源,支持复杂检测算法的开发与验证。
使用方法
使用voice_deepfake_detection_dataset时,研究者可直接加载其预处理的特征数据,无需进行繁琐的原始音频信号处理。数据集以标准化的格式提供,用户能够利用常见的机器学习框架读取并应用于模型训练。通过访问文件名称、标签、来源及划分字段,可以灵活构建训练流程,专注于模型架构与算法的优化。该数据集适用于监督学习任务,旨在推动语音深度伪造检测技术的性能提升与泛化能力研究。
背景与挑战
背景概述
随着语音合成与转换技术的飞速发展,深度伪造语音已成为数字安全领域的一大威胁。voice_deepfake_detection_dataset应运而生,旨在为语音深度伪造检测研究提供标准化的数据资源。该数据集由研究机构或团队构建,聚焦于通过声学特征如LFCC和MFCC来区分真实与伪造语音,其核心研究问题在于提升检测模型的泛化能力与鲁棒性,以应对日益复杂的伪造手段。该数据集的创建推动了语音安全领域的技术进步,为开发可靠的自动检测系统奠定了数据基础。
当前挑战
在语音深度伪造检测领域,主要挑战在于伪造技术的快速演进导致检测模型容易过时,难以泛化到未知的伪造方法。同时,真实与伪造语音之间的声学差异可能极其细微,要求模型具备高精度的特征提取能力。在数据集构建过程中,挑战包括收集多样化的真实和伪造语音样本以确保数据平衡,以及精确标注样本来源与标签以维护数据质量。此外,提取稳定的LFCC和MFCC特征并处理大规模数据也对计算资源与流程优化提出了较高要求。
常用场景
经典使用场景
在音频伪造检测领域,voice_deepfake_detection_dataset为研究人员提供了丰富的语音样本,其核心应用场景在于训练和评估深度伪造语音检测模型。该数据集通过包含大量真实与伪造语音的对比样本,并提取了LFCC和MFCC等关键声学特征,使得模型能够学习到伪造语音在频谱层面的细微差异。这种设计使得数据集成为开发高效检测算法的基石,广泛应用于学术竞赛和基准测试中,推动了音频安全技术的进步。
实际应用
在实际应用中,voice_deepfake_detection_dataset为金融、法律和安全行业提供了技术支撑。基于该数据集训练的检测模型可集成到电话银行系统、司法证据鉴定平台或社交媒体内容审核工具中,用于实时识别诈骗电话、伪造录音证据或虚假新闻音频。这些应用有助于降低社会工程攻击风险,保护个人隐私与公共信任,体现了数据集在现实世界中的防护价值。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括基于卷积神经网络和循环神经网络的端到端检测框架、利用注意力机制增强特征表示的方法,以及结合对抗训练提升模型鲁棒性的技术。这些工作不仅推动了音频伪造检测领域的算法创新,还为后续数据集如ASVspoof挑战赛提供了基准参考,形成了持续迭代的研究生态。
以上内容由遇见数据集搜集并总结生成


