lmqg/qg_tweetqa
收藏Hugging Face2022-12-02 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/lmqg/qg_tweetqa
下载链接
链接失效反馈官方服务:
资源简介:
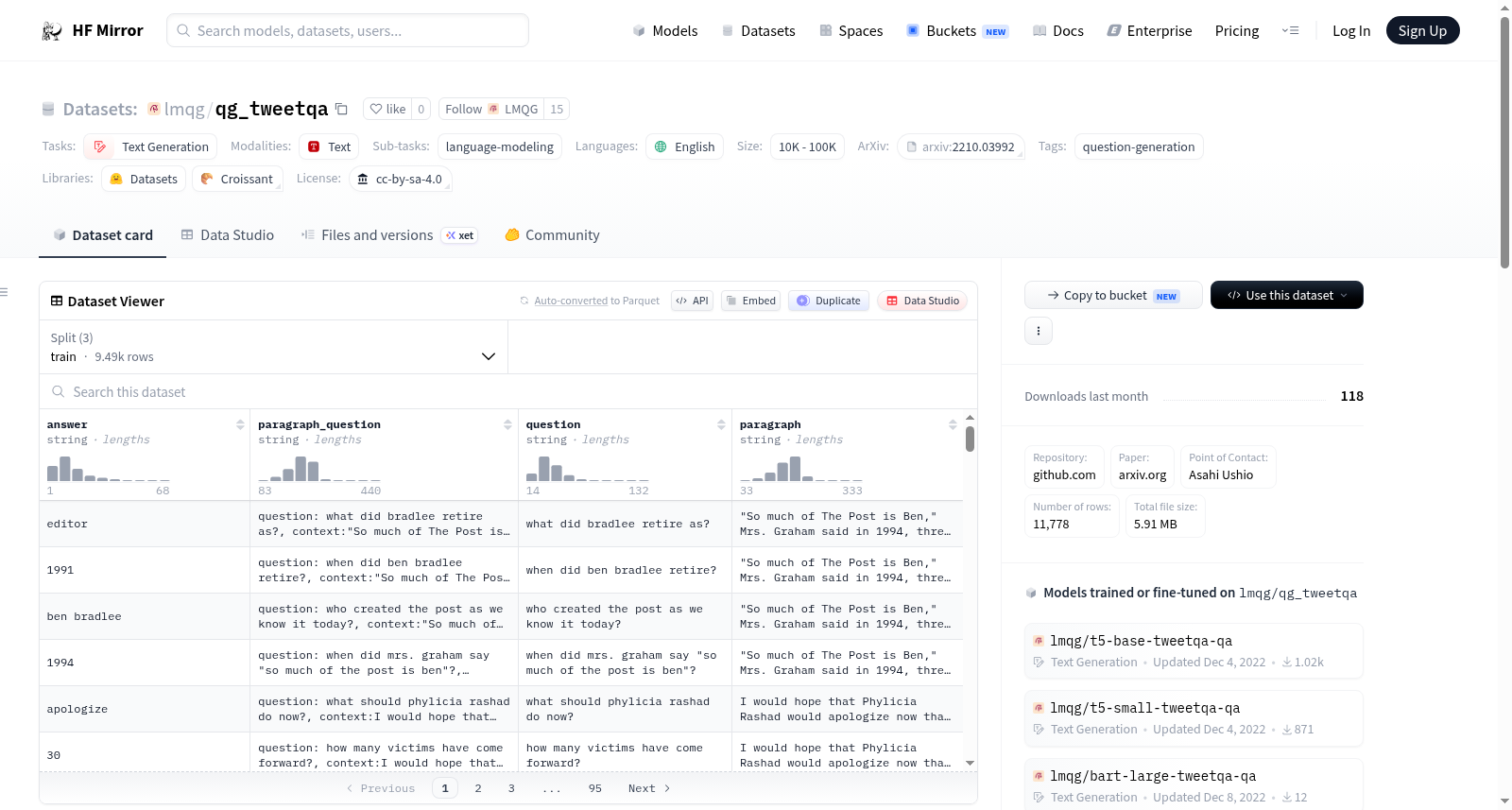
这是一个基于tweet_qa数据集的问答生成数据集。由于原始数据的测试集未公开,因此从训练集中随机抽取了测试问题。数据集支持的任务是问答生成,通常通过BLEU4/METEOR/ROUGE-L/BERTScore/MoverScore等指标来衡量模型在该任务上的表现。数据集的语言为英语,包含训练集、验证集和测试集,分别有9489、1086和1203个样本。数据集的字段包括问题、答案、段落和问题答案对。
This is a question answering generation dataset based on the tweet_qa dataset. Since the test split of the original dataset is not publicly available, we randomly sampled test questions from its training split. The task supported by this dataset is question answering generation, and model performance on this task is typically evaluated using metrics including BLEU4, METEOR, ROUGE-L, BERTScore, and MoverScore. This dataset is in English, and consists of training, validation, and test splits with 9489, 1086, and 1203 samples respectively. The dataset includes the following fields: question, answer, context passage, and question-answer pair.
提供机构:
lmqg
原始信息汇总
数据集概述
- 名称: TweetQA for question generation
- 许可证: cc-by-sa-4.0
- 语言: 英语 (en)
- 多语言性: 单语种
- 规模: 1k<n<10K
- 源数据集: tweet_qa
- 任务类别:
- 文本生成
- 任务ID:
- 语言建模
- 标签:
- 问题生成
数据集描述
- 摘要: 本数据集是基于tweet_qa的问题与答案生成数据集。原数据的测试集未公开发布,因此我们从训练集中随机抽样了测试问题。
- 支持的任务与排行榜:
问题-答案生成: 数据集用于训练问题与答案生成模型,成功标准通常通过BLEU4/METEOR/ROUGE-L/BERTScore/MoverScore等指标衡量。
数据集结构
- 数据字段:
问题: 字符串列表答案: 字符串列表段落: 字符串问题-答案: 字符串
- 数据分割:
训练: 9489验证: 1086测试: 1203
引用信息
@inproceedings{ushio-etal-2022-generative, title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration", author = "Ushio, Asahi and Alva-Manchego, Fernando and Camacho-Collados, Jose", booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing", month = dec, year = "2022", address = "Abu Dhabi, U.A.E.", publisher = "Association for Computational Linguistics", }
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是基于推文的问题与答案生成数据集,专为训练文本生成模型设计,包含约1.2万条英语样本,结构化为问题、答案和上下文段落,用于提升自动问答系统的性能。
以上内容由遇见数据集搜集并总结生成


