cyberleninka-law-30k
收藏Hugging Face2025-02-11 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/lawful-good-project/cyberleninka-law-30k
下载链接
链接失效反馈官方服务:
资源简介:
这是一个基于30,405篇法律主题文章的数据集,来源于“Киберленинка”网站。数据集利用大型语言模型从文章中提取信息,形成了包含26种任务类型的问题-答案对,如实体提取、回答问题、文本摘要等。
This is a dataset based on 30,405 legal-themed articles sourced from the "Киберленинка" website. The dataset leverages large language models to extract information from the articles, creating question-answer pairs covering 26 task types, including entity extraction, question answering, text summarization, and more.
创建时间:
2025-02-06
原始信息汇总
数据集概述
数据集名称
Cyberleninka-Law-30k
数据集来源
来源于 "Киберленинка",一个法律主题文章的网站。
数据集描述
该数据集基于30,405篇法律主题的文章,使用大型语言模型提取数据,用于生成问题-答案对。
使用许可
遵循GPL-3.0许可。
任务类型与数量
数据集包含26种类型的任务,以下是各任务类型及其对应的问题-答案对数量:
| 任务类型 | 数量 |
|---|---|
| 实体提取 | 37,345 |
| 回答问题 | 35,240 |
| 文本摘要 | 8,183 |
| 逻辑关系识别 | 772 |
| 文本比较 | 526 |
| 论点分析 | 510 |
| 相关文档搜索 | 469 |
| 文本分类 | 418 |
| 矛盾识别 | 414 |
| 文本生成 | 235 |
| 情感分析 | 206 |
| 因果关系分析 | 192 |
| 示例生成 | 125 |
| 事实检查 | 92 |
| 问题生成 | 81 |
| 文本改写 | 77 |
| 文本续写 | 73 |
| 文本结构识别 | 60 |
| 指令生成 | 34 |
| 时间框架分析 | 34 |
| 文本分析 | 33 |
| 统计分析 | 29 |
| 法律术语识别 | 23 |
| 问题识别 | 20 |
| 概念定义 | 17 |
| 反对论点生成 | 14 |
搜集汇总
数据集介绍
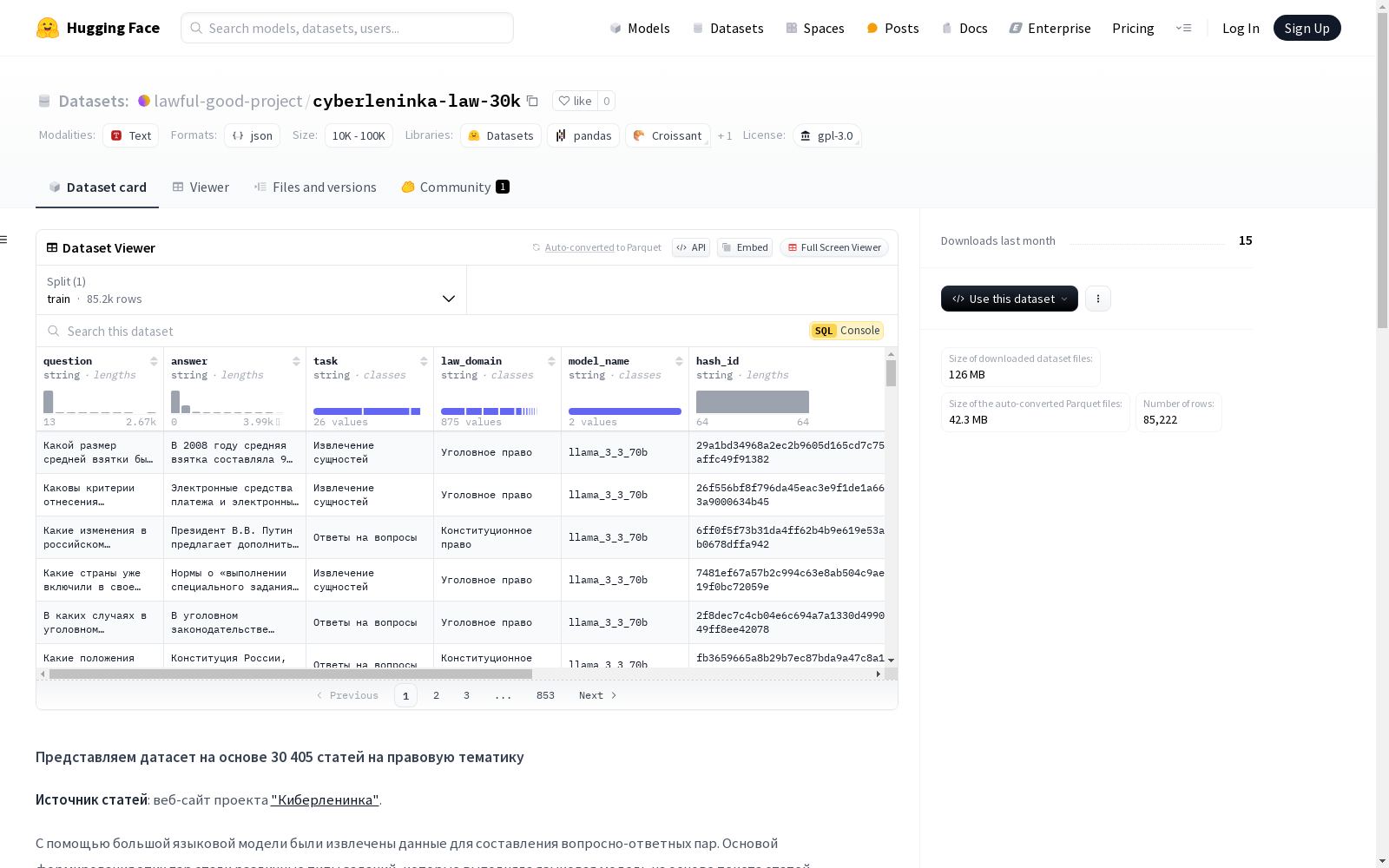
构建方式
该数据集名为cyberleninka-law-30k,其构建基于俄罗斯开放科学图书馆“Киберленинка”上的30,405篇法律主题文章。通过大型语言模型对文章进行深入分析,进而形成了各类任务所对应的问题与答案对,涵盖了从实体提取到文本分析等多种自然语言处理任务。
特点
数据集特色在于,它不仅包含广泛的法律主题文章,还涵盖了26种不同类型的自然语言处理任务,形成了大量的问答回答对。这些任务类型包括但不限于实体提取、问题回答、文本摘要、逻辑关系识别等,为法律文本分析和理解提供了丰富的语料资源。
使用方法
使用该数据集时,研究者可根据具体任务需求,选择相应的问答回答对进行模型训练或评估。数据集遵循GPL-3.0协议,用户需遵循相关协议规定。此外,数据集的多样化任务类型为不同的自然语言处理研究提供了实验的可能性,用户需根据具体任务指导模型进行针对性的学习和优化。
背景与挑战
背景概述
在信息时代,法律文献的数字化与智能处理变得尤为重要。'cyberleninka-law-30k'数据集,基于俄罗斯开放获取学术资源平台'Киберленинка'的30,405篇法律主题文章,旨在为自然语言处理任务提供丰富的训练数据。该数据集的创建,源于对法律文本自动化处理的需求,由大型语言模型从文章中提取数据,形成了多样化的任务类型,如提取实体、回答问题、文本摘要等,对法律信息处理领域的研究贡献良多。
当前挑战
数据集构建过程中的挑战主要体现在对法律专业术语的准确识别与处理,以及如何有效地从大量非结构化文本中提取结构化信息。此外,数据集在解决法律文本处理任务时面临的挑战包括:如何提高实体识别的准确率、如何准确地生成和识别法律问题及其答案、以及如何更好地理解和生成法律论证。这些挑战不仅考验着自然语言处理技术的精度和效率,也关系到法律人工智能应用的实际效能。
常用场景
经典使用场景
在法学的学术研究领域中,'cyberleninka-law-30k'数据集凭借其庞大的法律主题文章资源,成为构建与评估自然语言处理模型的重要工具。该数据集的经典使用场景在于,研究者利用其提供的文章内容,构建问题与答案的对,从而训练模型在法律文本理解、信息提取和文本生成等任务上的能力。
衍生相关工作
基于'cyberleninka-law-30k'数据集的研究成果,衍生出了众多经典工作,包括但不限于法律文本的自动摘要、多语言法律概念对齐、法律案例智能匹配等。这些工作不仅拓宽了法律人工智能的研究领域,也促进了相关技术的商业化和产业化进程。
数据集最近研究
最新研究方向
在法律文献研究领域,'cyberleninka-law-30k'数据集以其庞大的法律主题文章库,为自然语言处理任务提供了丰富的资源。该数据集不仅涵盖了传统的信息抽取、文本分类、文本生成等研究方向,更在实体识别、逻辑关系提取、以及对法律文本的深度分析等方面展现了其独特价值。目前,研究前沿主要集中在利用该数据集进行法律文本的自动化问答、法律概念的定义与辨析,以及法律论证的智能分析,这对于构建智能法律助手、提升法律服务的效率与准确性具有深远影响。
以上内容由遇见数据集搜集并总结生成


