so-combined-eng
收藏Hugging Face2025-11-15 更新2025-11-16 收录
下载链接:
https://huggingface.co/datasets/dunnolab/so-combined-eng
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个英文版的数据集,它整合了598个开源社区数据集,包含22,709个剧集和大约940万帧,涵盖563个不同的任务。数据集应用了多种转换来确保标准化和数据质量,包括相机视角标准化、任务重标注、视频标准化和无操作移除等处理。数据集以Apache-2.0许可证发布。
This is an English-language dataset that integrates 598 open-source community datasets, containing 22,709 episodes and approximately 9.4 million frames, spanning 563 distinct tasks. Multiple preprocessing transformations have been applied to ensure data standardization and quality, including camera view standardization, task re-annotation, video standardization, and removal of no-op segments. This dataset is released under the Apache-2.0 license.
创建时间:
2025-11-14
原始信息汇总
数据集概述
基本信息
- 数据集名称: so-combined-eng
- 许可证: Apache-2.0
- 任务类别: 机器人技术
- 语言: 英语
- 数据规模: 1M<n<10M
数据集描述
该数据集通过整合598个开源社区数据集构建而成,形成一个统一的语料库,包含22,709个片段和约940万帧数据,涵盖563个不同的任务。
数据处理流程
-
相机视角标准化
- 使用Qwen3-VL-8B-Instruct模型将所有图像分类为TOP、GRIPPER或SIDE三种视角
- 所有数据集都包含TOP和GRIPPER视角
- 缺少SIDE视角的数据集使用零值图像填充
-
任务重新标注
- 使用Qwen3-VL-8B-Instruct模型优化任务标注
- 重新标注过程综合考虑视频输入和原始任务描述
-
视频标准化
- 统一使用H.264编解码器
- 统一帧率:30 FPS
- 统一分辨率:480×640
-
无效操作移除
- 移除片段开始和结束的无操作部分
- 移除完全由无操作动作组成的片段
- 从原始数据集中消除了12.7%的无操作数据
数据集结构
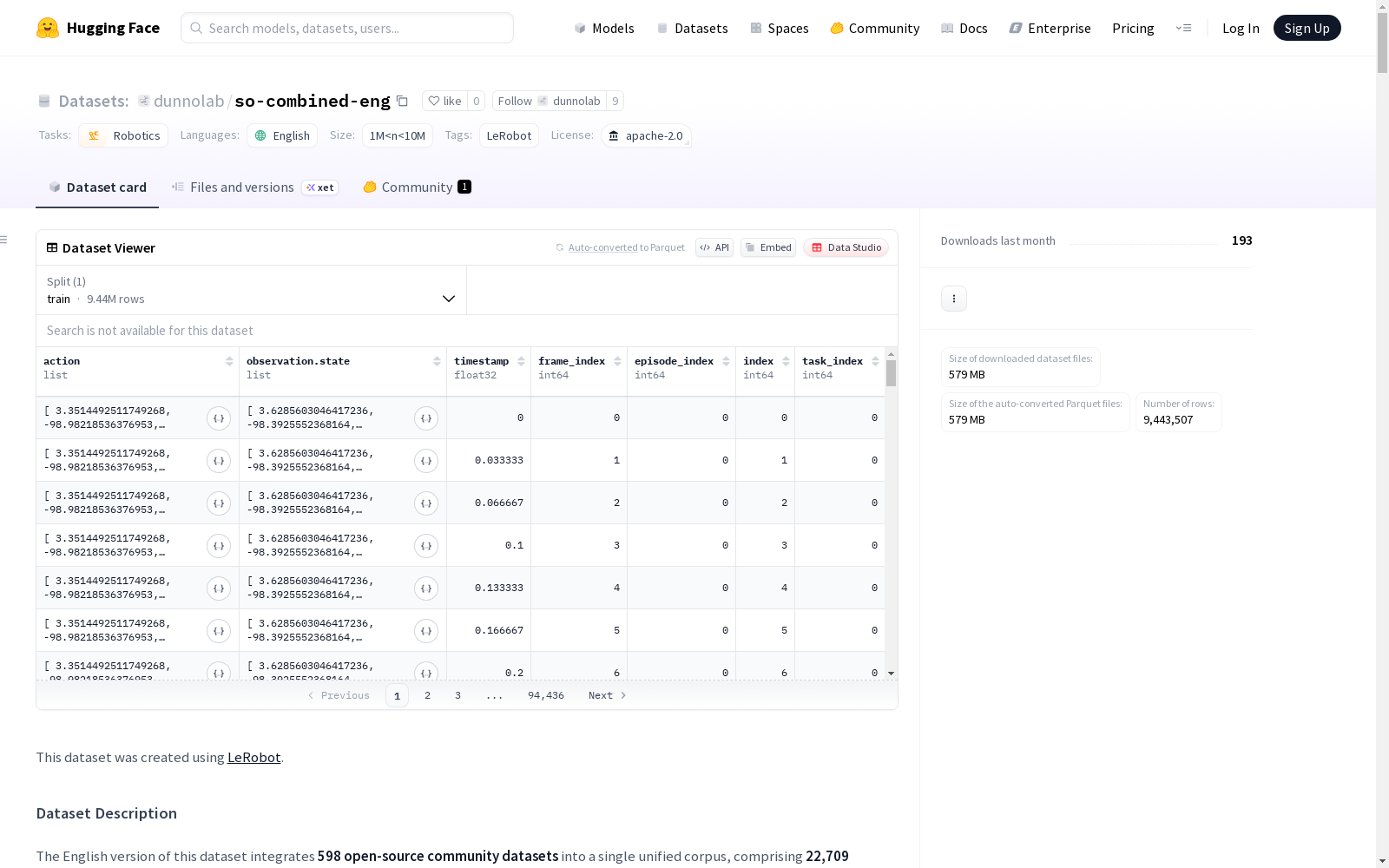
统计信息
- 总片段数:22,709
- 总帧数:9,443,507
- 总任务数:563
- 总视频数:68,127
- 数据块数:23
- 块大小:1,000
数据特征
- 动作数据:6维浮点数组,包含机械臂各关节控制参数
- 状态观测:6维浮点数组,反映机械臂关节状态
- 图像观测:包含三个视角的480×640分辨率视频
- 夹爪视角
- 顶部视角
- 侧面视角
- 元数据:时间戳、帧索引、片段索引、任务索引等
文件组织
- 数据文件:parquet格式
- 视频文件:MP4格式
- 数据路径模式:data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet
- 视频路径模式:videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4
技术规格
- 基础版本:v2.1
- 机器人类型:so100
- 帧率:30 FPS
- 分辨率:480×640
- 视频编解码:H.264
- 像素格式:yuv420p
- 无音频数据
搜集汇总
数据集介绍
构建方式
在机器人技术领域,数据集的构建往往面临异构数据源的整合挑战。so-combined-eng数据集通过系统化流程整合了598个开源社区数据集,运用Qwen3-VL-8B-Instruct模型实现相机视角的三元归一化处理,将杂乱命名的图像数据统一划分为TOP、GRIPPER和SIDE三类视角。视频数据经过H.264标准编码重构,确保所有片段保持480×640分辨率与30FPS帧率的一致性。通过任务重标注机制优化原始描述,并采用片段级修剪技术剔除12.7%的无操作冗余数据,最终形成包含22,709条轨迹的标准化语料库。
特点
该数据集呈现出多模态融合的显著特征,其核心价值体现在涵盖563种差异化任务的广泛覆盖度,约940万帧视觉数据构成丰富的学习样本。数据结构设计兼具系统性与灵活性,动作空间与状态观测均以六维浮点向量表征,配合三视角图像序列构成完整的环境感知体系。所有视频流遵循统一的色彩空间与编解码规范,时间戳与索引字段的精细标注为时序分析提供支撑。这种多维度的数据组织方式既满足模仿学习的需求,也为强化学习算法提供了理想的训练环境。
使用方法
研究者可通过标准化的数据接口直接访问该数据集,其分块存储架构将数据划分为23个逻辑单元以优化读取效率。每个数据块内采用Parquet格式封装动作指令、机器人状态和多视角图像流,配套的MP4视频文件通过动态路径模板实现精准映射。在具体应用时,用户可依据任务索引快速定位目标场景,利用帧级时间戳重建完整操作序列。这种设计既支持端到端的策略学习,也允许对特定任务子集进行精细化分析,为机器人行为建模研究提供完整的技术基础。
背景与挑战
背景概述
机器人学习领域长期面临数据分散与标准缺失的困境,so-combined-eng数据集应运而生。该数据集由HuggingFace社区通过LeRobot平台整合598个开源机器人数据集构建而成,涵盖22709个任务片段与940万帧视觉数据,涉及563种操作任务。通过多视角视觉归一化与任务重标注技术,该数据集建立了跨场景的机器人操作基准,为模仿学习与强化学习算法提供了规模化的训练资源。
当前挑战
数据集构建面临异构数据融合的复杂性,原始社区数据存在相机视角命名不一致、任务描述模糊等问题。通过视觉语言模型实现视角自动分类与任务语义重构,需克服多源视频编码差异带来的时序对齐难题。在技术层面,需解决无效动作片段过滤与跨数据集动作空间映射等核心问题,这些挑战直接关系到机器人操作策略的泛化能力与决策精度。
常用场景
经典使用场景
在机器人学习领域,so-combined-eng数据集通过整合598个开源社区数据集构建了统一的多视角视觉动作序列库。其标准化处理使研究者能够系统性地训练端到端模仿学习模型,尤其适用于机械臂抓取、物体操纵等复杂任务场景。多摄像机视角的同步数据为模型提供了空间感知基础,而动作轨迹与视觉观测的精确对齐则保障了行为克隆算法的训练效果。
实际应用
工业自动化领域可借助该数据集开发智能分拣系统,通过预训练模型快速适配不同产线环境。服务机器人领域则能基于多视角数据提升物体抓取成功率,特别是在家庭助老、物流仓储等场景中。教育科研机构可利用其标准化特性构建机器人操作仿真平台,大幅降低实体机器人实验成本与安全风险。
衍生相关工作
基于该数据集衍生的经典工作包括多模态行为克隆框架的改进研究,其中视觉动作表征学习取得显著进展。在跨任务泛化方向,研究者开发了基于元学习的自适应策略网络。此外,该数据集还催生了多个机器人操作基准测试平台,推动领域内评估标准的统一与算法性能的横向比较。
以上内容由遇见数据集搜集并总结生成


