Persian-Old-Dataset
收藏github2024-06-23 更新2024-06-24 收录
下载链接:
https://github.com/Electronic-Persian-Old-Library/Persian-Old-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
波斯古语言数据集
Ancient Persian Language Dataset
创建时间:
2024-06-23
原始信息汇总
古波斯楔形文字原始数据集概述
数据集简介
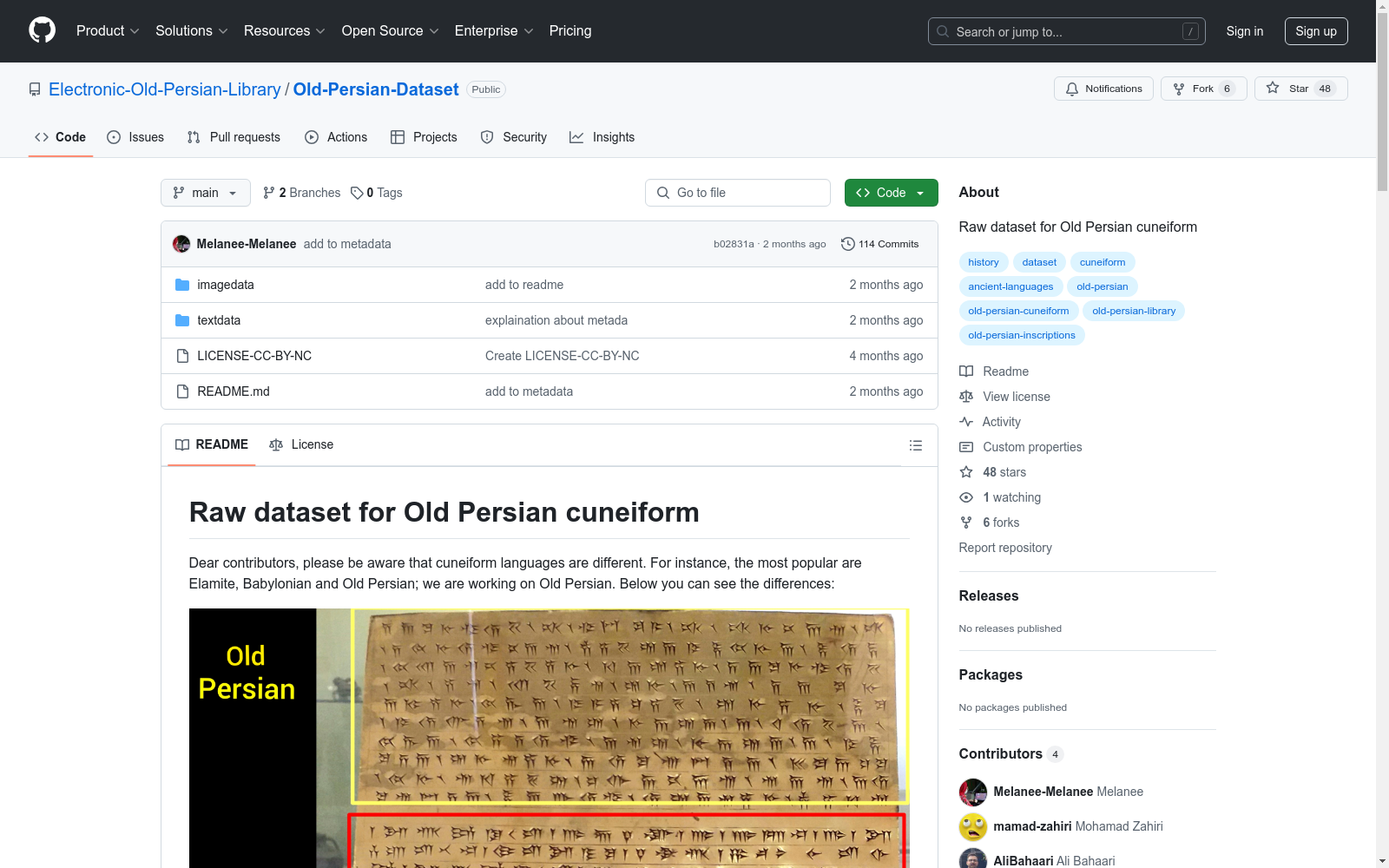
- 数据集专注于古波斯楔形文字(Old Persian cuneiform),区别于埃兰(Elamite)和巴比伦(Babylonian)等其他楔形文字。
- 包含图像数据和文本数据,涵盖古波斯帝国时期的铭文,如大流士一世(Darius)的金板铭文等。
数据结构
图像数据 (/imagedata)
/source/king/: 存储原始图像文件,命名格式为source_king_001.jpg。- 示例路径:
/behistun/darius_1/behistun_darius_1_001.jpg。
文本数据 (/textdata)
/eng_transcription_to_english/: 包含英文转录的JSON文件及元数据。/eng_transliteration_to_english/: 包含英文转写的JSON文件及元数据。/single/: 存储无翻译的纯文本数据,包含转写JSON文件。
元数据说明
图像数据元数据
source: 数据来源。abbreviation: 铭文缩写名称。location: 铭文发现地。translation: 是否包含翻译(1/0)。collection: 当前存储地。artifact_id: CDLI参考编号。asset_number: 大英博物馆藏品编号。museum_number: 大英博物馆编号。
文本数据元数据
abbreviation: 铭文缩写名称。reference: 数据来源参考。location: 铭文发现地。image: 是否包含图像(1/0)。artifact_id: CDLI参考编号。
数据示例与差异说明
- 提供楔形文字类型对比图(古波斯、埃兰、巴比伦)。
- 展示转录(transcription)与转写(transliteration)的差异示例。
数据来源与参考文献
- Livius.org
- 大英博物馆藏品
- 维基百科
- 楔形文字数字图书馆计划(CDLI)
- 书籍《The Inscriptions in Old Persian Cuneiform of the Achaemenian Emperors》
- 伊朗国家博物馆和波斯波利斯的个人摄影
术语表
- 包含关键术语的波斯语对照(如Behistun:بیستون、Susa:شوش等)。
许可信息
- 采用CC-BY-NC许可,禁止商业用途。
搜集汇总
数据集介绍
构建方式
Persian-Old-Dataset的构建基于对古波斯楔形文字的深入研究,数据集包括图像数据和文本数据两大部分。图像数据主要来源于伊朗国家博物馆和塔赫特-贾姆希德(Persepolis)的实物拍摄,以及英国博物馆的收藏。文本数据则涵盖了古波斯语的转写和转录,分别存储在不同的子目录中。每个目录都附有详细的元数据文件,记录了数据来源、发现地点、翻译状态等信息。数据集的构建过程涉及使用OCR模型将古波斯楔形文字转换为英文转写文本,随后通过NLP或大型语言模型将其转换为现代语言。
特点
Persian-Old-Dataset的显著特点在于其专注于古波斯楔形文字,提供了丰富的图像和文本数据,涵盖了多种翻译和转写方法。数据集的结构设计合理,便于用户根据需求进行检索和分析。此外,数据集附带的元数据文件详细记录了每条数据的来源和背景信息,增强了数据的可追溯性和学术价值。
使用方法
使用Persian-Old-Dataset时,用户可以根据研究需求选择图像数据或文本数据进行分析。对于图像数据,用户可以通过元数据文件了解每件文物的详细信息,如发现地点和收藏地点。对于文本数据,用户可以利用提供的转写和转录文件进行语言学分析或翻译研究。此外,数据集还提供了数据处理流程的参考,用户可以借鉴该流程进行进一步的数据处理和模型训练。
背景与挑战
背景概述
Persian-Old-Dataset聚焦于古波斯楔形文字的研究,由Electronic-Old-Persian-Library团队创建。该数据集汇集了来自伊朗国家博物馆和塔赫特-贾姆希德(Persepolis)的珍贵文物图像,以及相关的文本数据,包括英文转录和转写。其核心研究问题在于通过光学字符识别(OCR)和自然语言处理(NLP)技术,将古波斯楔形文字转换为现代语言,从而促进古代语言学和历史研究。该数据集的创建不仅填补了古波斯楔形文字数字化研究的空白,还为相关领域的学者提供了宝贵的资源,推动了古代语言学和历史研究的进展。
当前挑战
Persian-Old-Dataset在构建过程中面临多重挑战。首先,古波斯楔形文字的独特性和复杂性使得OCR模型的训练和优化成为一大难题。其次,由于古波斯楔形文字的稀有性和文物保护的限制,获取高质量的图像数据和文本数据也极具挑战性。此外,将古波斯楔形文字准确转换为现代语言需要高度精确的NLP模型,这对模型的性能和准确性提出了极高的要求。最后,数据集的多样性和复杂性也增加了数据管理和处理的难度,确保数据的一致性和可靠性成为一项重要任务。
常用场景
经典使用场景
Persian-Old-Dataset在古代波斯楔形文字研究领域中具有经典的使用场景。该数据集通过提供丰富的图像和文本数据,支持学者们进行古波斯语的转录和翻译工作。特别是,数据集中的图像数据可以用于训练光学字符识别(OCR)模型,而文本数据则可作为自然语言处理(NLP)模型的输入,以实现从古波斯语到现代语言的机器翻译。这种结合图像和文本的多模态数据处理方式,为古文字研究提供了新的技术路径。
实际应用
Persian-Old-Dataset在实际应用中展现了广泛的价值。博物馆和文化遗产机构可以利用该数据集进行古文物的数字化保存和展示,提升公众对古代文明的认识。教育机构则可以将其用于教学和研究,培养学生对古代语言和文化的兴趣。此外,该数据集还可为历史学家和考古学家提供重要的研究材料,支持他们在古波斯历史和文化领域的深入探索。
衍生相关工作
Persian-Old-Dataset的发布催生了一系列相关经典工作。首先,基于该数据集的OCR模型和NLP模型的开发,为古文字的自动识别和翻译提供了技术支持。其次,学者们利用数据集中的多语言翻译数据,开展了跨语言的文化比较研究,揭示了不同文明间的交流与影响。此外,该数据集还激发了更多关于古文字数字化和人工智能应用的研究,推动了古文字学与现代技术的融合。
以上内容由遇见数据集搜集并总结生成


