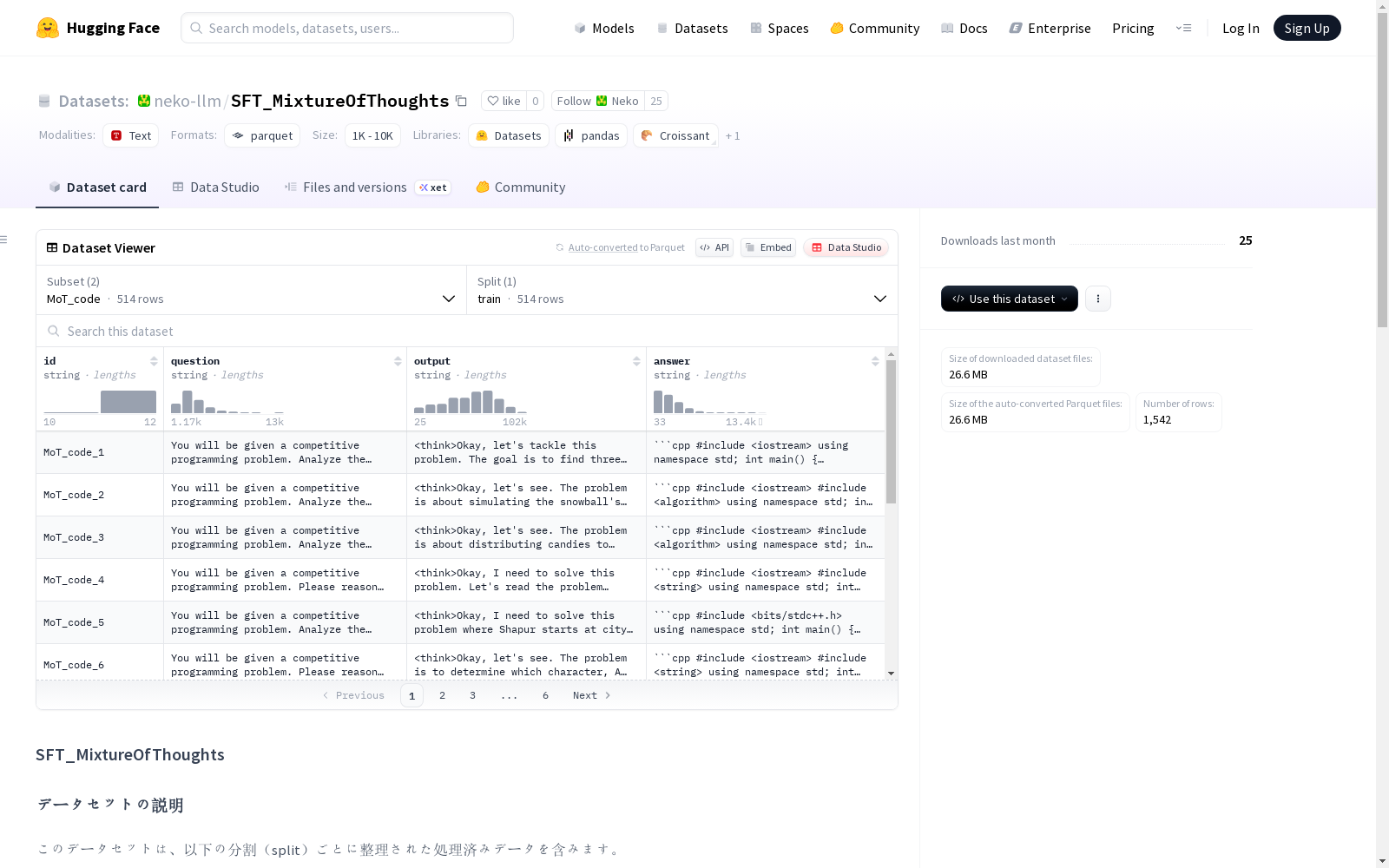
SFT_MixtureOfThoughts
收藏Hugging Face2025-08-02 更新2025-08-03 收录
下载链接:
https://huggingface.co/datasets/neko-llm/SFT_MixtureOfThoughts
下载链接
链接失效反馈官方服务:
资源简介:
SFT_MixtureOfThoughts数据集包含了两个部分:MoT_science和MoT_code。每个部分都包含了JSON和Parquet两种格式的文件。这些文件是为了方便进行大规模数据处理而设计的。数据集可以通过指定的Python库加载处理。
The SFT_MixtureOfThoughts dataset consists of two components: MoT_science and MoT_code. Each component includes files in both JSON and Parquet formats. These files are designed to facilitate large-scale data processing, and the dataset can be loaded and processed using the specified Python libraries.
创建时间:
2025-07-30
原始信息汇总
SFT_MixtureOfThoughts 数据集概述
数据集描述
- 包含两个分割(split)的处理后数据:
- MoT_science
- MoT_code
数据格式
- 每个分割提供两种格式:
- JSON格式:位于各分割子文件夹内(如
MoT_code/) - Parquet格式:位于
data/目录下,文件名以分割名作为前缀(如data/MoT_code_*.parquet)
- JSON格式:位于各分割子文件夹内(如
文件结构
SFT_MixtureOfThoughts/ ├── MoT_science/ │ ├── file1.json │ ├── file2.json │ └── ... ├── data/ │ └── MoT_science/ │ ├── file1.parquet │ ├── file2.parquet │ └── ... └── README.md
使用方法
python from datasets import load_dataset
加载特定分割
MoT_science_data = load_dataset("neko-llm/SFT_MixtureOfThoughts", "MoT_science") MoT_code_data = load_dataset("neko-llm/SFT_MixtureOfThoughts", "MoT_code")
手动指定文件加载
dataset = load_dataset( "parquet", data_files={ "MoT_science": "data/MoT_science_.parquet", "MoT_code": "data/MoT_code_.parquet", } )
加载单个文件
import pandas as pd df = pd.read_parquet("data/MoT_science_filename.parquet")
加载特定分割的所有文件
from pathlib import Path split_files = list(Path("data").glob("MoT_science_*.parquet")) for file in split_files: df = pd.read_parquet(file)
搜集汇总
数据集介绍
构建方式
在人工智能领域,高质量的数据集是模型训练的关键基础。SFT_MixtureOfThoughts数据集通过精心设计的构建流程,将科学和编程领域的知识整合为结构化的数据资源。该数据集采用双格式存储策略,原始数据以JSON格式保存于各子目录中,同时转换为Parquet格式进行优化存储,显著提升了大规模数据处理的效率。构建过程中严格遵循数据标准化原则,确保每个JSON文件都有对应的Parquet版本,为研究者提供了灵活的数据访问选择。
特点
作为多领域混合思维数据集,SFT_MixtureOfThoughts展现出鲜明的专业特色。数据集包含科学(MoT_science)和编程(MoT_code)两大核心领域,每个领域配置500个精选样本。其双格式存储体系既保留了原始JSON数据的完整性,又通过Parquet格式实现了高效压缩和快速读取。特别值得注意的是,数据集采用分片存储设计,允许研究者根据需要灵活加载特定领域或样本子集,这种模块化架构大大提升了数据使用的便捷性。
使用方法
针对不同研究需求,SFT_MixtureOfThoughts提供了多层次的数据访问方案。通过Hugging Face的datasets库,用户可以便捷地加载整个数据集或特定领域子集。对于需要精细控制的研究场景,支持直接指定Parquet文件路径进行加载。数据集兼容pandas等主流数据处理工具,研究者可以使用read_parquet方法直接读取单个文件,或通过通配符批量处理同领域的所有样本。这种多样化的访问接口设计,确保了从探索性分析到大规模实验的各种研究需求都能得到满足。
背景与挑战
背景概述
SFT_MixtureOfThoughts数据集由neko-llm研究团队构建,旨在探索混合思维链(Mixture of Thoughts, MoT)在科学和代码生成领域的应用潜力。该数据集通过整合科学问题求解与编程任务两种模态,为复杂推理任务的模型训练提供了跨领域基准。其创新性在于采用思维链增强技术,将逻辑推理过程显式编码,显著提升了语言模型在专业领域的表现。作为多模态思维链研究的代表性成果,该数据集为人工智能系统的复杂问题解决能力评估设立了新标准。
当前挑战
该数据集面临的核心挑战体现在两个方面:领域适应性方面,科学问题与编程任务存在显著差异,要求模型同时掌握自然语言理解与形式化语言生成能力;数据构建层面,思维链标注需要领域专家参与,标注成本高昂且一致性难以保证。技术实现上,Parquet与JSON双格式存储虽提升存取效率,但跨模态数据的对齐与标准化处理仍需解决语义鸿沟问题。此外,科学推理的严谨性与代码生成的灵活性之间存在固有张力,这对数据集的平衡性设计提出了更高要求。
常用场景
经典使用场景
在自然语言处理领域,SFT_MixtureOfThoughts数据集以其独特的科学和代码混合思维结构,为研究者提供了丰富的训练素材。该数据集特别适用于探索混合思维模式下的语言模型微调,尤其是在处理跨领域知识融合任务时展现出显著优势。通过科学问题推理与代码生成的双重维度,它成为评估模型复杂思维能力的理想基准。
实际应用
在实际应用层面,SFT_MixtureOfThoughts数据集显著提升了智能教育系统的开发效率。教育科技公司利用其科学-代码双模态特性,构建能够同步解释理论概念和演示算法实现的智能辅导系统。在自动化科研助手开发中,该数据集支持构建兼具文献解析和实验代码生成能力的复合型AI助手。
衍生相关工作
基于该数据集衍生的研究已产生多项重要成果,包括混合思维链微调框架MoT-Tuning和跨领域知识蒸馏算法SciCodeDistill。这些工作通过创新性地利用数据集的二元结构特征,在ACL、NeurIPS等顶级会议上发表了系列突破性论文,推动了多模态思维建模领域的方法论革新。
以上内容由遇见数据集搜集并总结生成


