M3GIA
收藏arXiv2024-06-08 更新2024-06-18 收录
下载链接:
https://huggingface.co/datasets/Songweii/M3GIA
下载链接
链接失效反馈官方服务:
资源简介:
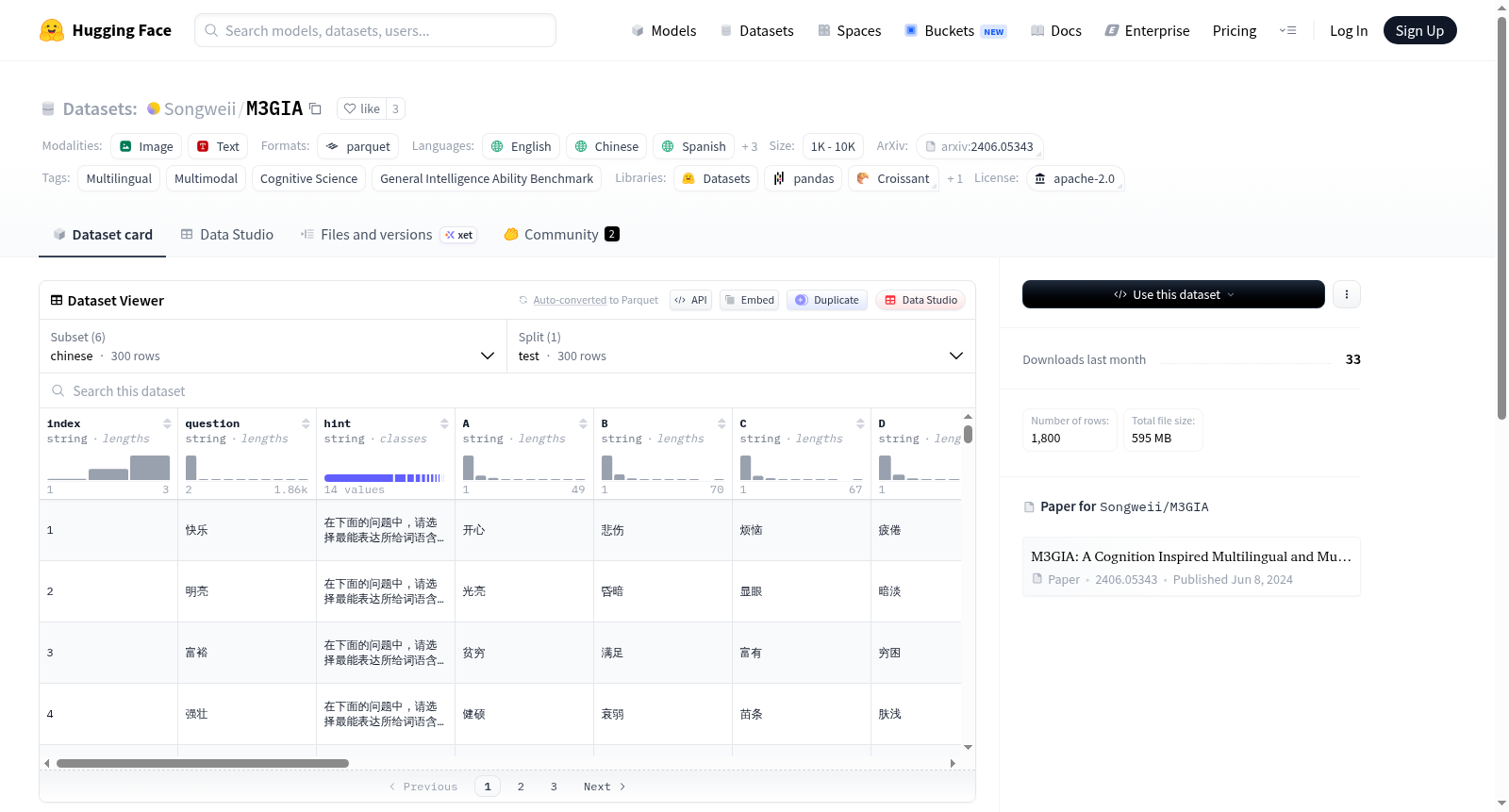
M3GIA是由西湖大学AutoLab创建的多语种多模态通用智能能力基准数据集,旨在通过认知科学理论评估大型语言模型的智能水平。该数据集包含1800个问题,涵盖英语、中文、法语、西班牙语、葡萄牙语和韩语六种语言,确保了文化背景的多样性。数据集的创建过程参考了人类智能测试,如Raven's Progressive Matrices Test,并根据Cattell-Horn-Carroll (CHC)模型划分了五个认知维度。M3GIA的应用领域广泛,主要用于评估和提升多模态大型语言模型在不同语言和文化背景下的认知能力,以解决现有基准在评估模型智能时可能存在的偏差问题。
M3GIA is a multilingual multimodal general intelligence benchmark dataset created by AutoLab at Westlake University, designed to evaluate the intelligence of large language models (LLMs) using cognitive science theories. This dataset contains 1,800 questions spanning six languages: English, Chinese, French, Spanish, Portuguese, and Korean, ensuring diverse cultural backgrounds. The development of M3GIA draws on human intelligence tests such as the Raven's Progressive Matrices Test, and partitions the dataset into five cognitive dimensions based on the Cattell-Horn-Carroll (CHC) model. M3GIA has a wide range of applications, primarily used to assess and enhance the cognitive abilities of multimodal large language models across different linguistic and cultural contexts, thereby addressing potential biases in existing benchmarks when evaluating model intelligence.
提供机构:
西湖大学AutoLab
创建时间:
2024-06-08
搜集汇总
数据集介绍
构建方式
在认知科学领域,Cattell-Horn-Carroll(CHC)智力模型为评估人类认知能力提供了坚实的理论基础。M3GIA数据集以此为框架,精心构建了涵盖六种语言(英语、中文、法语、西班牙语、葡萄牙语和韩语)的评估基准。数据收集过程严格遵循认知维度划分,将问题设计为五个广泛认知集群:常识、视觉空间、理解、数学和推理,进一步细分为18个狭窄问题类型。为确保文化真实性,所有涉及文化背景的数据均从各语言原生语境中采集,避免了英语中心偏差。最终,数据集包含1800道多项选择题,其中超过半数问题依据心理学测试标准从头设计,确保了评估的全面性与平衡性。
特点
M3GIA数据集的核心特点在于其认知科学驱动的评估理念。与传统的任务导向型基准不同,该数据集基于CHC理论,将多模态大语言模型的认知能力解构为五个关键维度:流体推理、理解知识、视觉处理、阅读写作和定量知识。这种设计使得评估能够深入揭示模型的内在智力结构,而非仅仅关注表面任务表现。数据集的多语言覆盖进一步拓展了评估边界,六种语言的平行测试不仅检验了模型的语言适应性,也为探究语言对认知能力的影响提供了实证基础。数据集中问题类型的多样性与认知维度的重叠性设计,模拟了人类智能的复杂交互,为全面衡量模型的通用智力能力奠定了科学基础。
使用方法
M3GIA数据集的使用旨在为零样本环境下的多模态大语言模型提供认知能力评估。研究人员可通过标准化的提示工程,将模型置于统一的测试框架中,无需针对基准进行微调或少量样本学习。评估过程涵盖所有认知维度与语言变体,通过准确率指标量化模型在各狭窄问题类型上的表现。更为重要的是,数据集引入了基于验证性因子分析(CFA)的通用智力准确率(GIA)指标,该指标源自人类测试数据,能够综合反映模型的整体认知水平。通过对比模型与人类参与者的GIA分数,研究者可以直观判断模型在特定语言及认知领域与人类智能的差距,从而为模型的改进与优化提供方向性指导。
背景与挑战
背景概述
在人工智能领域,随着多模态大语言模型(MLLMs)在复杂任务中展现出卓越能力,学界开始探讨这些模型是否能够真正模拟人类智能。然而,现有基准测试多聚焦于任务性能评估,如对象属性识别的准确性,而结合认知科学深入理解模型智能本质的研究尚属空白。为此,由西湖大学、阿里巴巴集团及中国科学院等机构的研究团队于2024年共同创建了M3GIA数据集,这是首个基于认知科学理论的多语言多模态通用智能能力基准。该数据集以广泛认可的Cattell-Horn-Carroll(CHC)智力模型为理论基础,旨在从流体推理、理解知识、视觉处理、阅读写作和定量知识五个核心认知维度,系统评估MLLMs的通用智能能力,并覆盖英语、中文、法语、西班牙语、葡萄牙语和韩语六种语言,以消除英语中心偏差,推动人工智能模型认知能力的深入研究与发展。
当前挑战
M3GIA数据集致力于解决多模态大语言模型在通用智能能力评估中的核心挑战。在领域问题层面,现有基准测试往往局限于任务导向的性能衡量,缺乏对模型底层认知能力的系统性评估,难以真实反映其智能水平;M3GIA通过引入CHC认知模型,试图构建一个理论扎实、维度全面的评估框架,以揭示模型在流体推理、视觉空间等关键认知领域的表现差距。在构建过程中,挑战主要体现在多语言与文化适配性方面:为确保数据真实性与公平性,团队需从各语言原生语境中收集与文化背景相关的数据,而非简单翻译英语内容,这增加了数据采集与标注的复杂性;同时,将抽象认知因素转化为具体多模态问题类型,并保持六种语言间问题结构、数量与分布的一致性,亦是一项艰巨的工程与设计任务。
常用场景
经典使用场景
在人工智能领域,多模态大语言模型的认知能力评估正成为研究热点。M3GIA数据集通过引入认知科学中的CHC理论框架,构建了一个涵盖六种语言的多模态通用智能能力基准。其经典使用场景在于系统性地评估模型在流体推理、理解知识、视觉空间处理、读写能力及量化知识等五个核心认知维度上的表现,为研究者提供了一个超越传统任务导向评估的综合性工具,从而深入探索模型是否具备类似人类的通用智能特质。
解决学术问题
M3GIA数据集解决了当前多模态大语言模型评估中存在的关键学术问题。传统基准往往局限于特定任务性能的测量,缺乏对模型底层认知能力的系统性分析。该数据集基于CHC智力模型,将评估维度锚定于认知科学理论,使得研究者能够区分模型的晶体智力与流体智力,揭示模型在跨语言环境下的认知差异。其意义在于推动了人工智能评估从表面任务完成度向深层智能结构的转变,为理解模型智能的本质提供了实证基础。
衍生相关工作
M3GIA数据集的推出催生了一系列相关研究,尤其是在认知科学与人工智能的交叉领域。基于其理论框架,后续工作可能深入探索模型在更多认知因子上的表现,如听觉处理或工作记忆。该数据集也启发了对多模态模型“通用智能能力”存在性的实证检验,促进了类似基准的构建,例如扩展更多语言或融入动态交互评估。这些衍生工作共同推动了以认知为导向的模型评估范式,为人工智能向人类智能对齐提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


