HybridSyntheticMedicalQA
收藏Hugging Face2025-06-01 更新2025-06-02 收录
下载链接:
https://huggingface.co/datasets/Proximile/HybridSyntheticMedicalQA
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了经过筛选的医疗问题和答案,用于训练医疗问答的语言模型。数据集来源于AskDoc,由Proximile LLC进行处理和审核,确保了中高质量的内容。但是,数据集可能存在医学准确性、人口统计偏差等局限性,并建议仅用于研究和开发目的。
This dataset contains filtered medical questions and answers, intended for training language models for medical question answering. It is sourced from AskDoc and processed and audited by Proximile LLC to ensure medium-to-high quality content. However, the dataset may have limitations such as medical inaccuracies and demographic biases, and it is recommended for research and development purposes only.
创建时间:
2025-06-01
原始信息汇总
HybridSyntheticMedicalQA 数据集概述
基本信息
- 许可证: MIT
- 任务类别: 问答、文本生成、文本到文本生成
- 语言: 英语
- 标签: 医学
- 规模: 10K<n<100K
数据集描述
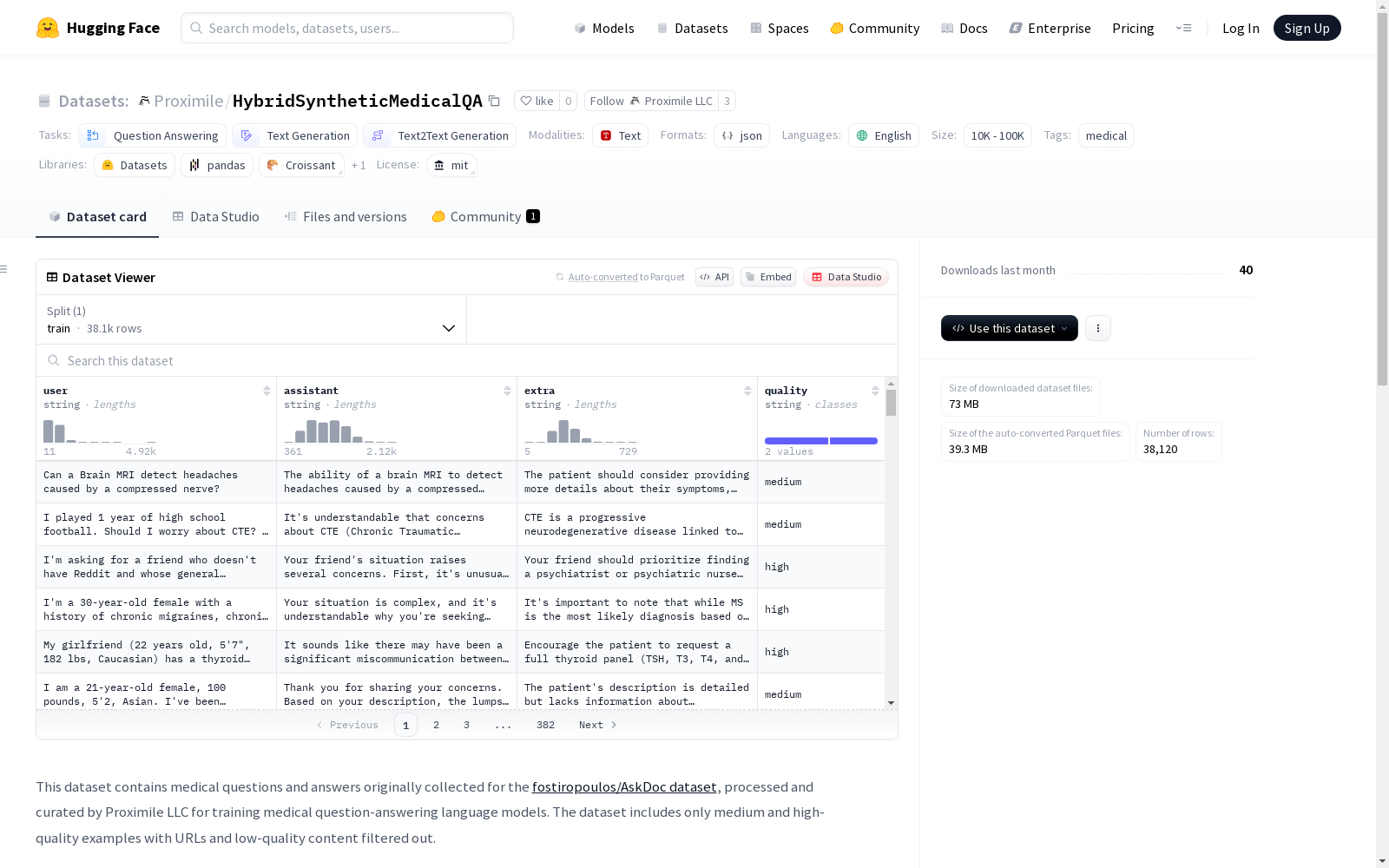
- 该数据集包含医学问题和答案,最初为 fostiropoulos/AskDoc 数据集 收集,由 Proximile LLC 处理和整理,用于训练医学问答语言模型。
- 仅包含中等和高质量示例,过滤掉了 URL 和低质量内容。
偏见、风险和限制
- 医学准确性: 虽然经过质量过滤,但回答源自在线社区,可能不总是反映当前医学最佳实践或专业医学共识。
- 人口统计偏见: 数据集反映了 Reddit 用户的人口统计特征,可能不代表寻求医学信息的更广泛人群。
- 训练限制: 仅基于此数据训练的模型不应在没有额外保障和验证的情况下部署用于直接医学咨询。
- 范围限制: 仅限于来自单一在线社区的英语内容。
建议
- 该数据集仅用于研究和开发目的。
- 医学信息应始终由合格的医疗保健专业人员验证。
- 基于此数据训练的系统在部署前需要额外的安全措施。
- 考虑与其他经过验证的医学数据集结合以获得更稳健的训练。
- 在训练模型中实施适当的内容过滤和安全措施。
- 建议定期根据医学基准进行评估。
引用
bibtex @misc{hybrid_synthetic_medical_proximile2025, title={HybridSyntheticMedicalQA}, author={Proximile LLC}, year={2025}, note={Processed from original AskDoc dataset: https://github.com/fostiropoulos/AskDoc} }
联系方式
如有关于此处理数据集的问题,请联系 Proximile LLC。
搜集汇总
数据集介绍
构建方式
HybridSyntheticMedicalQA数据集源自AskDoc项目收集的原始医学问答数据,经由Proximile LLC团队精心筛选与处理,构建过程严格遵循质量优先原则。研究团队采用多级过滤机制,剔除低质量内容及无效URL链接,仅保留中等及以上质量的问答样本,确保数据源的可靠性与专业性。该数据集特别注重内容真实性验证,通过社区反馈机制对医学准确性进行初步把控,为自然语言处理任务提供了经过净化的语料资源。
特点
该数据集最显著的特征在于其专业医学领域的针对性,涵盖经过人工筛选的英文医学问答对,内容质量显著高于普通网络文本。数据样本呈现典型的社区互动特征,真实反映在线医疗咨询场景中的语言模式和问题类型。值得注意的是,数据集存在固有的局限性,其内容受Reddit用户群体分布影响,可能无法完全代表广泛人群的医疗信息需求,且部分回答可能未达到最新医学共识标准。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,建议将其作为医疗问答系统开发的辅助训练资源。使用时应结合其他权威医学数据集进行联合训练,以提升模型的泛化能力。为规避潜在风险,任何基于该数据集开发的系统都需经过严格的医学专业验证,并配备完善的安全防护机制。典型应用场景包括医学知识检索系统的原型开发、医疗对话系统的语言理解模块训练等非诊断性研究领域。
背景与挑战
背景概述
HybridSyntheticMedicalQA数据集由Proximile LLC于2025年基于fostiropoulos/AskDoc原始数据构建而成,旨在为医疗问答系统提供高质量的英文训练语料。该数据集聚焦于在线医疗咨询场景,通过严格筛选机制保留了中等及高质量的问题-答案对,同时剔除了低质量内容和无效URL。作为医疗自然语言处理领域的重要资源,该数据集为开发基于人工智能的医疗问答模型提供了关键支持,特别是在患者自主咨询和预诊断场景中展现出独特价值。其构建过程体现了跨学科合作特点,融合了临床医学知识与自然语言处理技术,为医疗AI的可解释性和可靠性研究提供了新的数据基础。
当前挑战
该数据集面临的核心挑战主要体现在医学专业性和数据代表性两个维度。在领域问题层面,网络社区来源的答案难以保证与最新医学指南同步,存在知识时效性风险;非专业回答中的表述模糊性增加了模型学习准确医学知识的难度。数据构建过程中,Reddit用户群体的年龄、地域分布不均导致样本存在潜在人口统计学偏差;英语单语种限制影响了模型在多语言医疗场景的适用性。质量过滤机制虽提升了数据纯净度,但可能过度剔除边缘病例信息,削弱了模型对罕见病症的识别能力。这些挑战要求研究者在模型训练阶段引入额外的医学知识验证机制和偏差缓解策略。
常用场景
经典使用场景
在医学自然语言处理领域,HybridSyntheticMedicalQA数据集为构建智能医疗问答系统提供了重要支持。该数据集经过严格筛选,保留了中等和高质量的医学问答对,特别适合用于训练和评估医疗领域的问答模型。研究人员可利用该数据集开发能够理解复杂医学问题并生成准确回答的语言模型,为患者提供初步的医疗信息咨询。
实际应用
在实际应用层面,HybridSyntheticMedicalQA数据集支撑了多个医疗AI系统的开发。基于该数据集训练的模型可部署在医疗信息平台,为用户提供24/7的初步医疗咨询服务。这些系统能够有效分流非紧急医疗咨询,减轻医疗机构负担。同时,该数据集也被用于开发医学生教育工具,帮助培养问诊和诊断思维能力。
衍生相关工作
围绕HybridSyntheticMedicalQA数据集,学术界已产生多项重要研究。部分工作专注于提升模型在医疗问答中的准确性,开发了专门的评估指标和微调方法。另一些研究则探索如何将此类社区医疗数据与专业医学知识库相结合。值得关注的是,该数据集还催生了关于在线医疗信息可信度评估和偏见缓解的创新方法。
以上内容由遇见数据集搜集并总结生成


