beyond/chinese_clean_passages_80m
收藏Hugging Face2022-12-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/beyond/chinese_clean_passages_80m
下载链接
链接失效反馈官方服务:
资源简介:
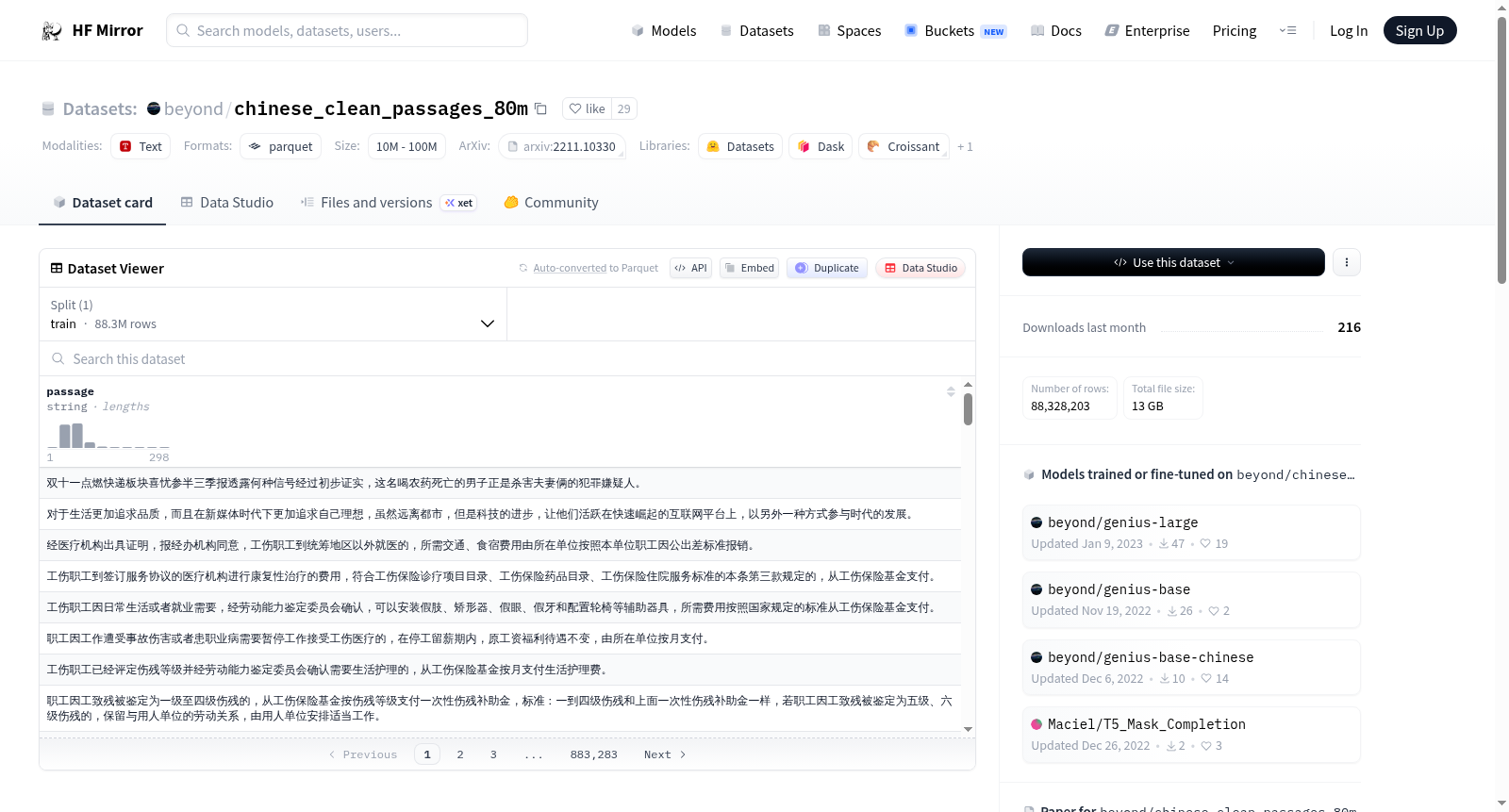
`chinese_clean_passages_80m`数据集包含超过8千万个纯净的中文段落,这些段落不包含任何字母、数字或特殊符号。段落的长度大多在50到200个汉字之间。数据集通过`datasets.load_dataset()`方法下载,会产生38个数据包,总大小约为12GB。该数据集用于训练GENIUS模型的中文版。
The `chinese_clean_passages_80m` dataset contains over 80 million clean Chinese passages that contain no letters, numbers, or special symbols. Most of these passages range from 50 to 200 Chinese characters in length. When downloaded via the `datasets.load_dataset()` method, this dataset includes 38 data packages with a total size of approximately 12 GB. This dataset is used for training the Chinese version of the GENIUS model.
提供机构:
beyond
原始信息汇总
数据集概述
数据集名称
chinese_clean_passages_80m
数据集描述
- 包含88328203个纯净中文段落,不包含任何字母、数字或特殊字符。
- 文本长度大部分介于50至200个汉字之间。
数据集特征
passage: 字符串类型,表示中文段落。
数据集拆分
train: 包含88328203个示例,总大小为18979214734字节。
数据集大小
- 下载大小: 1025261393字节
- 数据集总大小: 18979214734字节
数据集下载与存储
- 下载数据集将产生38个数据包,每个约340MB,总计约12GB。
数据集来源
- 基于CLUE中文预训练语料集处理和过滤得到。
原始数据集引用
@misc{bright_xu_2019_3402023, author = {Bright Xu}, title = {NLP Chinese Corpus: Large Scale Chinese Corpus for NLP }, month = sep, year = 2019, doi = {10.5281/zenodo.3402023}, version = {1.0}, publisher = {Zenodo}, url = {https://doi.org/10.5281/zenodo.3402023} }
搜集汇总
数据集介绍
构建方式
在中文自然语言处理领域,构建高质量文本语料是模型预训练的基础。本数据集源于CLUE中文预训练语料集,通过精细的过滤流程,剔除了所有字母、数字及特殊符号,确保了文本的纯净性。处理后的语料包含超过八千八百万个段落,每个段落均经过长度筛选,多数介于50至200个汉字之间,形成了规模庞大且格式统一的中文文本集合。
特点
该数据集的核心特征在于其纯净性与规模性。所有文本均严格限定为纯中文内容,无任何非汉字字符干扰,为语言模型提供了清晰的语言环境。段落长度分布集中,有利于模型学习连贯的语义表达。数据总量约12GB,划分为38个数据分片,便于分布式处理与存储,兼顾了使用的灵活性与效率。
使用方法
使用本数据集时,可通过Hugging Face的`datasets`库直接加载。调用`load_dataset('beyond/chinese_clean_passages_80m')`即可自动下载全部数据分片,总计约12GB。用户需确保设备具备足够存储空间。加载后,数据以标准格式提供,可直接用于大规模语言模型的预训练或文本生成任务的增强,如GENIUS模型的训练场景。
背景与挑战
背景概述
在自然语言处理领域,大规模高质量中文语料库的构建对于推动预训练语言模型的发展至关重要。由Beyond团队于2022年发布的chinese_clean_passages_80m数据集,源自CLUE中文预训练语料集,经过精细处理与过滤,旨在为GENIUS等生成式模型提供纯净的中文文本资源。该数据集包含超过八千万个段落,每个段落长度集中于50至200个汉字,且严格剔除了字母、数字及特殊符号,确保了语料的纯粹性与一致性。其核心研究问题聚焦于如何通过极端选择性掩码策略优化文本生成与增强任务,为中文自然语言生成模型的预训练奠定了坚实基础,显著提升了模型在文本创作与数据增强方面的性能。
当前挑战
该数据集致力于解决中文文本生成与增强任务中的核心挑战,即缺乏大规模、高质量且无噪声的中文语料资源。在构建过程中,首要挑战在于从原始CLUE语料中实现高效过滤,需精确移除所有字母、数字及特殊符号,同时保持文本语义连贯性与语言规范性。其次,确保段落长度分布集中于50至200汉字范围内,要求复杂的文本分割与质量控制机制。此外,数据规模高达12GB,涉及38个分片,对存储与处理效率提出了严峻考验,需平衡数据完整性、访问速度与资源消耗。这些挑战共同凸显了构建纯净中文语料库在技术实现与实用性方面的复杂性。
常用场景
经典使用场景
在自然语言处理领域,大规模纯净文本语料是预训练语言模型的基础。该数据集凭借其超过八千万个无字母数字的中文段落,为模型提供了高质量的语言表示学习素材。其文本长度集中于50至200个汉字,恰好符合现代预训练任务对上下文长度的典型需求,常被用于训练生成式语言模型,如GENIUS中文版,以提升模型对中文语法结构和语义连贯性的捕捉能力。
实际应用
在实际应用层面,基于该数据集训练的模型能够服务于多种下游任务。例如,在智能写作辅助系统中,模型可生成流畅的中文段落,提升内容创作效率;在教育技术领域,它能作为语言增强工具,为学习者提供高质量的文本示例。此外,在搜索引擎优化与自动摘要生成等场景中,此类模型也能显著改善对中文信息的理解与处理效果,体现了从数据到实际生产力的转化。
衍生相关工作
该数据集直接支撑了GENIUS模型的预训练工作,该模型采用极端选择性掩码策略,专注于文本生成与增强。同时,它作为CLUE中文预训练语料集的衍生与精炼版本,也为后续诸多研究提供了高质量的起点。围绕此类纯净语料,学术界进一步开展了关于数据清洗效度、领域适应迁移以及低资源语言建模等一系列探索,持续丰富了中文自然语言处理的技术谱系。
以上内容由遇见数据集搜集并总结生成


