CACD 跨年龄人脸识别和检索数据集
收藏帕依提提2024-03-04 收录
下载链接:
https://www.payititi.com/opendatasets/show-1734.html
下载链接
链接失效反馈官方服务:
资源简介:
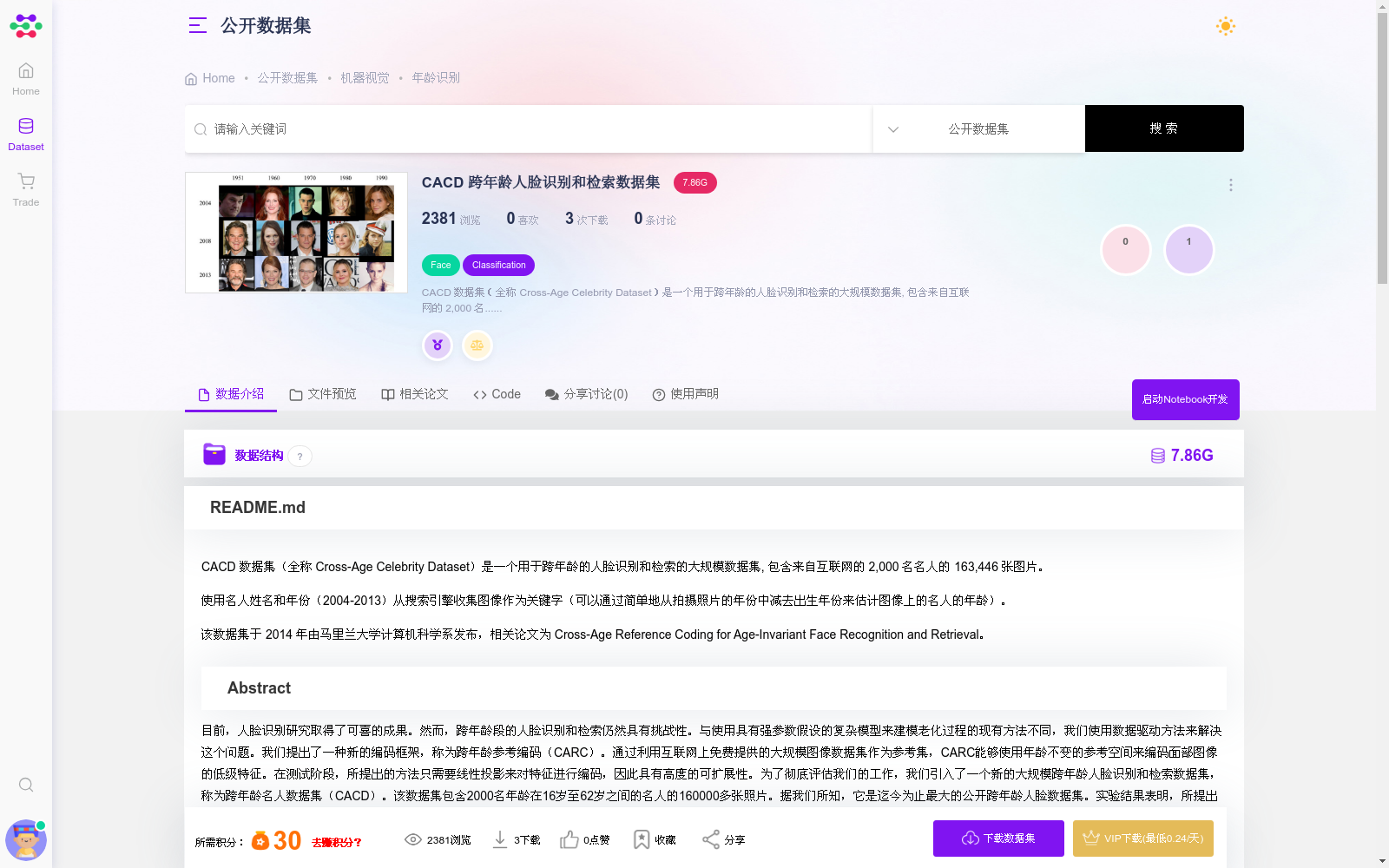
CACD 数据集(全称 Cross-Age Celebrity Dataset)是一个用于跨年龄的人脸识别和检索的大规模数据集, 包含来自互联网的 2,000 名名人的 163,446 张图片。 使用名人姓名和年份(2004-2013)从搜索引擎收集图像作为关键字(可以通过简单地从拍摄照片的年份中减去出生年份来估计图像上的名人的年龄)。 该数据集于 2014 年由马里兰大学计算机科学系发布,相关论文为 Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval。 目前,人脸识别研究取得了可喜的成果。然而,跨年龄段的人脸识别和检索仍然具有挑战性。与使用具有强参数假设的复杂模型来建模老化过程的现有方法不同,我们使用数据驱动方法来解决这个问题。我们提出了一种新的编码框架,称为跨年龄参考编码(CARC)。通过利用互联网上免费提供的大规模图像数据集作为参考集,CARC能够使用年龄不变的参考空间来编码面部图像的低级特征。在测试阶段,所提出的方法只需要线性投影来对特征进行编码,因此具有高度的可扩展性。为了彻底评估我们的工作,我们引入了一个新的大规模跨年龄人脸识别和检索数据集,称为跨年龄名人数据集(CACD)。该数据集包含2000名年龄在16岁至62岁之间的名人的160000多张照片。据我们所知,它是迄今为止最大的公开跨年龄人脸数据集。实验结果表明,所提出的方法可以在我们的数据集以及用于跨年龄人脸识别的其他广泛使用的数据集(morphi数据集)上实现最先进的性能。 跨年龄名人数据集(CACD)包含163446张来自互联网上2000位名人的照片。这些图片是从搜索引擎收集的,使用名人姓名和年份(2004-2013)作为关键词。因此,我们可以通过简单地从照片拍摄年份减去出生年份来估计照片上名人的年龄。下载的数据集包含两个MATLAB结构: 注意: *我们手动删除排名小于或等于5的名人的嘈杂图像。然而,由于有些图像即使对人类来说也很难识别,数据集可能仍然包含小噪声。此外,我们只使用非常简单的重复检测方法,因此数据集可能仍然包含接近重复的图像。 *其他名人(排名高于五位)的照片将包含噪音,因此不应用于评估。 *该数据集主要用于跨年龄人脸识别和检索。CACD数据集中的年份标签是粗略的,因此我们不建议将其应用于年龄估计工作。 CACD人脸检索性能 在这里,我们报告了使用原始特征(高维LBP)和所提出的方法(CARC)对具有三个不同子集的人脸检索的结果。在所有三个子集中,2013年拍摄的图像被用作查询图像。该数据库包含分别在2004-2006年、2007-2009年和2010-2012年拍摄的三个子集的图像。所有三个子集仅包含排名从3到5的名人的图像。 1. D.Chen,X.Cao,F.Wen,andJ.Sun,“Blessingofdimensionality:High- dimensional feature and its efficient compression for face verification,” in IEEE Conf. Computer Vision and Pattern Recognition, 2013, pp. 3025– 3032. 2. D. Gong, Z. Li, D. Lin, J. Liu, and X. Tang, “Hidden factor analysis for age invariant face recognition,” in IEEE Int. Conf. Computer Vision, 2013. 3. Chen, Bor-Chun, Chu-Song Chen, and Winston H. Hsu. "Face recognition and retrieval using cross-age reference coding with cross-age celebrity dataset." IEEE Transactions on Multimedia 17.6 (2015): 804-815. 4. Wen, Yandong, Zhifeng Li, and Yu Qiao. "Latent factor guided convolutional neural networks for age-invariant face recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. If you use our dataset and would like to report your results, please e-mail Sirius Chen. We will be gald to put your results on this webstie. For cross-age reference coding (CARC) code use in this paper, please visit [here] We also implemented the high-dimensional LBP features (Chen, Cao, Wen, and Sun, CVPR 2013), please visit [here] for more information.
CACD Dataset (full name: Cross-Age Celebrity Dataset) is a large-scale dataset for cross-age face recognition and retrieval, containing 163,446 images of 2,000 celebrities collected from the Internet. Images were gathered from search engines using celebrity names and years (2004–2013) as keywords, and the age of the celebrity in each image can be roughly estimated by subtracting the celebrity’s birth year from the photo capture year. This dataset was released by the Department of Computer Science, University of Maryland in 2014, with the associated paper titled *Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval*.
Currently, remarkable progress has been achieved in face recognition research. However, cross-age face recognition and retrieval remain highly challenging. Unlike existing approaches that employ complex models with strong parametric assumptions to model the aging process, we adopt a data-driven framework to address this issue. We propose a novel coding framework termed Cross-Age Reference Coding (CARC). By leveraging the large-scale freely accessible image dataset on the Internet as a reference set, CARC can encode the low-level features of facial images using an age-invariant reference space. During the testing phase, the proposed method only requires linear projection for feature encoding, thus exhibiting excellent scalability.
To thoroughly evaluate our work, we introduce a new large-scale cross-age face recognition and retrieval dataset named the Cross-Age Celebrity Dataset (CACD). This dataset contains over 160,000 photos of 2,000 celebrities aged between 16 and 62. To the best of our knowledge, it is the largest publicly available cross-age face dataset to date. Experimental results demonstrate that the proposed method achieves state-of-the-art performance on both our dataset and other widely used cross-age face recognition datasets (e.g., the MORPH Dataset).
The Cross-Age Celebrity Dataset (CACD) contains 163,446 photos of 2,000 celebrities collected from the Internet. These images were gathered from search engines using celebrity names and years (2004–2013) as search keywords. As such, the age of the celebrity in each photo can be estimated by subtracting the celebrity’s birth year from the photo’s capture year. The downloaded dataset includes two MATLAB structures:
**Note:**
* We manually removed noisy images of celebrities with a rank ≤ 5. However, since some images are difficult to recognize even for human observers, the dataset may still contain minor levels of noise. Furthermore, we only utilized a very simple duplicate detection method, so the dataset may still include near-duplicate images.
* Photos of other celebrities (with a rank > 5) contain noise and thus should not be used for evaluation purposes.
* This dataset is primarily designed for cross-age face recognition and retrieval tasks. The year labels in the CACD dataset are approximate, so we do not recommend applying it to age estimation work.
### CACD Face Retrieval Performance
Here, we report the face retrieval results using raw high-dimensional LBP features and the proposed method (CARC) across three distinct subsets. For all three subsets, images captured in 2013 were used as query images. The database consists of images from three subsets captured in 2004–2006, 2007–2009, and 2010–2012, respectively. All three subsets only contain images of celebrities with a rank of 3 to 5.
#### References
1. D. Chen, X. Cao, F. Wen, and J. Sun, "Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification," in *IEEE Conference on Computer Vision and Pattern Recognition*, 2013, pp. 3025–3032.
2. D. Gong, Z. Li, D. Lin, J. Liu, and X. Tang, "Hidden factor analysis for age invariant face recognition," in *IEEE International Conference on Computer Vision*, 2013.
3. Chen, Bor-Chun, Chu-Song Chen, and Winston H. Hsu. "Face recognition and retrieval using cross-age reference coding with cross-age celebrity dataset." *IEEE Transactions on Multimedia* 17.6 (2015): 804–815.
4. Wen, Yandong, Zhifeng Li, and Yu Qiao. "Latent factor guided convolutional neural networks for age-invariant face recognition." *Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition*, 2016.
If you use our dataset and wish to report your results, please contact Sirius Chen via email. We will be glad to publish your results on this website. For the Cross-Age Reference Coding (CARC) code used in this paper, please visit [here]. We also implemented the high-dimensional LBP features (Chen, Cao, Wen, and Sun, CVPR 2013); please visit [here] for additional information.
提供机构:
帕依提提
搜集汇总
数据集介绍
背景与挑战
背景概述
CACD数据集是一个大规模跨年龄人脸识别和检索数据集,包含2000名名人的163,446张图片,覆盖16至62岁的年龄范围,专为研究跨年龄段人脸识别问题设计。数据集通过名人姓名和年份从互联网收集,并提供了年龄估计和身份信息,适用于数据驱动的年龄不变人脸识别方法研究。
以上内容由遇见数据集搜集并总结生成


