Sora100K
收藏Hugging Face2026-03-31 更新2026-04-01 收录
下载链接:
https://huggingface.co/datasets/ysicong/Sora100K
下载链接
链接失效反馈官方服务:
资源简介:
Sora100K是一个大规模多模态视频数据集资源,旨在支持文本到视频生成、单轮视频编辑和多轮视频编辑的研究。该数据集在一个统一的元数据和分析框架下,为现代视频创作和编辑研究提供支持。Sora100K包含103,439个视频,分为18,451个生成样本、76,964个单轮编辑样本和8,024个多轮编辑样本或链。当前发布的Hugging Face仓库仅包含元数据层,而非原始视频文件。数据集结构分为三个子集文件夹,分别对应不同的任务设置,每个子集都有详细的README文件描述任务设置、发布状态、元数据文件和特定字段说明。Sora100K适用于多镜头组合、场景转换、编辑轨迹等视频创作工作流的结构属性研究。用户需注意,不同子集的发布完整度可能不同,且原始视频文件的获取需遵循原始平台的访问权限和条款。
Sora100K is a large-scale multimodal video dataset resource designed to support research on text-to-video generation, single-round video editing, and multi-round video editing. Built upon a unified metadata and analysis framework, this dataset supports modern video creation and editing research. Sora100K comprises 103,439 videos, categorized into three groups: 18,451 generation samples, 76,964 single-round editing samples, and 8,024 multi-round editing samples or chains. The currently released Hugging Face repository only contains the metadata layer rather than the raw video files. The dataset is structured into three subset folders corresponding to distinct task settings, each accompanied by a detailed README file that describes the task setup, release status, metadata files and specific field descriptions. Sora100K is applicable to research on the structural attributes of video creation workflows such as multi-shot composition, scene transition and editing trajectories. Users should note that the release completeness of different subsets may vary, and access to raw video files must comply with the access permissions and terms of the original platforms.
创建时间:
2026-03-24
原始信息汇总
Sora100K 数据集概述
数据集基本信息
- 数据集名称:Sora100K
- 许可证:other
- 语言:英语
- 标签:video, multimodal, tabular, text-to-video, video-editing, datasets
数据集配置
数据集包含三个配置,均仅提供训练集分割:
- text_to_video_generation (默认配置)
- 数据文件路径:
Text-to-Video Generation/*.csv
- 数据文件路径:
- single_turn_video_editing
- 数据文件路径:
Single-Turn Videos Editing/*.csv
- 数据文件路径:
- multi_turn_video_editing
- 数据文件路径:
Multi-Turn Videos Editing/*.csv
- 数据文件路径:
核心描述
Sora100K 是一个用于研究文本到视频生成、单轮视频编辑和多轮视频编辑的大规模多模态视频数据集资源,其构建在统一的元数据和分析框架之下。该资源旨在支持跨多种任务设置的现代视频创作和编辑研究。当前发布的版本主要包含数据集的元数据层、文档和补充材料,不直接重新分发底层的原始视频文件。
关键统计信息
完整的 Sora100K 资源包含:
- 视频总数:103,439 个
- 文本到视频生成样本:18,451 个
- 单轮视频编辑样本:76,964 个
- 多轮视频编辑样本(链):8,024 个
数据集结构
仓库按任务设置组织为三个子集文件夹,每个文件夹包含其自身的 README.md 文件,用于描述任务设置、当前发布状态、发布的元数据文件、代表性字段以及子集特定的说明和限制。
Text-to-Video Generation/Single-Turn Videos Editing/Multi-Turn Videos Editing/
当前发布状态
三个子集的发布完整度目前不完全一致:
- Single-Turn Videos Editing 文件夹反映了当前最成熟的元数据发布部分,是当前实验中使用的主要子集。
- Text-to-Video Generation 文件夹对应于 Sora100K 的生成子集,其元数据组织可能会随着更多生成特定文件的准备而继续扩展。
- Multi-Turn Videos Editing 文件夹对应于组织为编辑链的多轮编辑子集,提供了子集特定的元数据和文档。
数据来源与访问
- 来源:数据集构建自与多种视频创作设置(包括文本到视频生成、单轮视频编辑和多轮视频编辑)相关的视频和结构化记录。在构建和预处理过程中,每个样本的结构化记录(如
meta.json、result.json、scenedetect.json)被处理并转换为表格元数据文件。 - 视频获取:用户可以通过以下步骤获取底层视频:
- 使用发布的元数据文件识别目标样本。
- 遵循仓库中提供的检索工作流程或脚本。
- 根据来源可用性和访问权限,从原始或其他授权来源访问相应的视频。
- 在原始平台要求时,重新生成有效的源级访问链接。
- 重要标识符:对于长期参考和恢复,推荐的标识符是
sample_id、source_post_id、edited_post_id。元数据中的某些链接可能是临时的,不应被视为稳定或永久的标识符。
许可与使用条款
- 此仓库标记为
license: other,因为发布的资源包含元数据、文档和相关工具,而底层原始媒体可能涉及混合所有权或平台特定的权利条件。 - 除非另有说明,此仓库不声明对元数据引用的任何原始媒体的重新许可或重新分发权利。
- 用户在检索或使用底层视频时,有责任遵守原始平台条款、创作者权利以及任何适用的法律或法规。
预期用途与限制
- 预期用途:支持多模态视频生成和编辑的研究,特别是用于数据集分析和基准测试、元数据驱动的检索与过滤、源-编辑关系与编辑轨迹研究、场景级和结构分析(包括时间组织和多镜头构图)以及可重现的数据整理、预处理和子集级评估工作流程。
- 限制:
- 当前发布版本不直接重新分发原始视频文件。
- 元数据中引用的一些源级链接或签名 URL 可能是临时的,或会随时间过期。
- 不同的子集目前可能以不同的完整度发布。
- 数据集可能继承原始生成或编辑平台的偏见、伪影或覆盖不平衡。
- 对底层视频的访问可能取决于来源可用性、平台政策或授权条件。
加载数据集示例
python from datasets import load_dataset
gen_ds = load_dataset("YOUR_USERNAME/YOUR_REPO_NAME", "text_to_video_generation") single_edit_ds = load_dataset("YOUR_USERNAME/YOUR_REPO_NAME", "single_turn_video_editing") multi_edit_ds = load_dataset("YOUR_USERNAME/YOUR_REPO_NAME", "multi_turn_video_editing")
引用
如果使用此资源,请引用相应的论文和数据集页面。
搜集汇总
数据集介绍
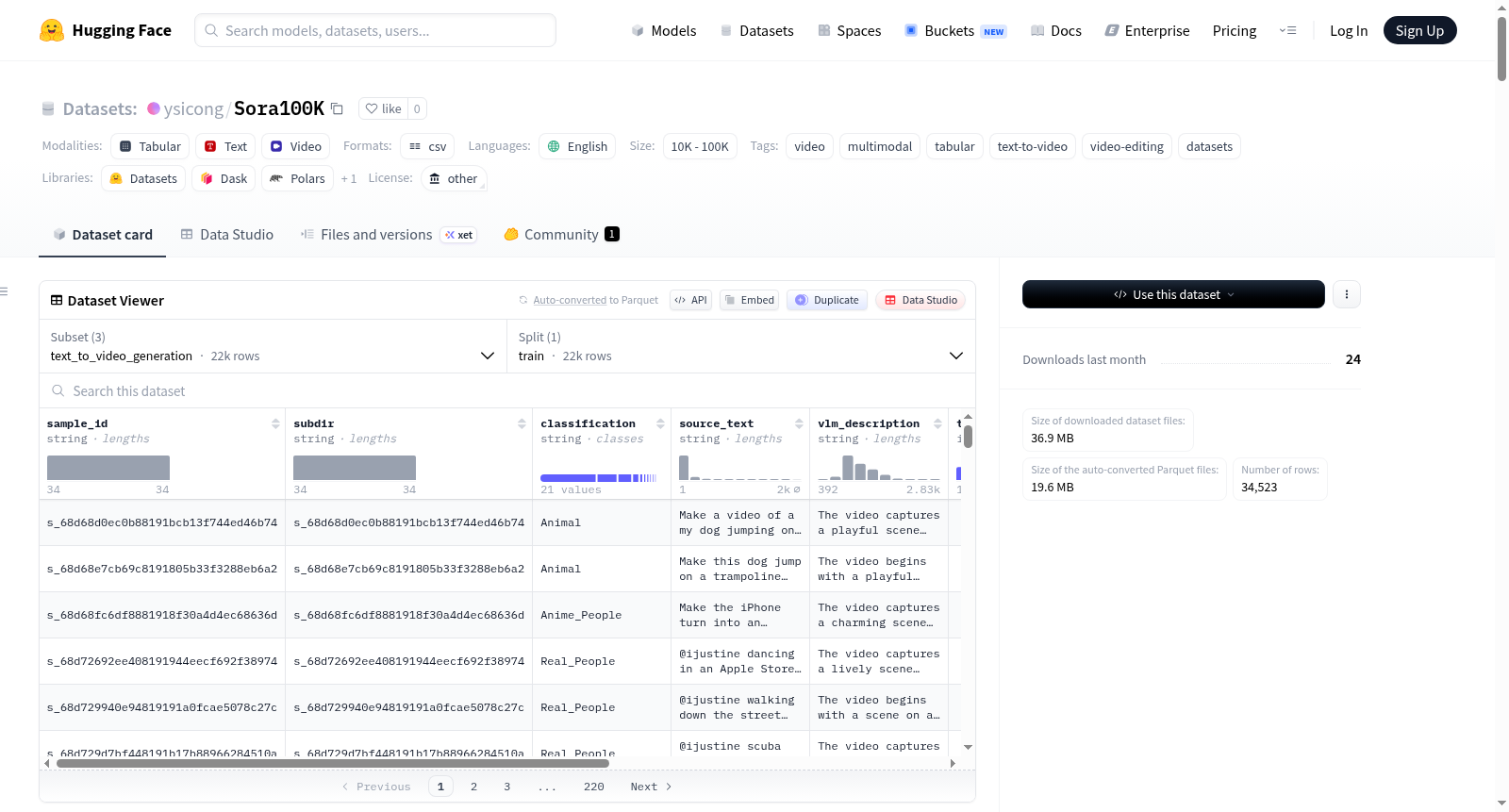
构建方式
在视频生成与编辑研究领域,构建高质量的大规模数据集对于推动算法创新至关重要。Sora100K数据集通过整合文本到视频生成、单轮视频编辑以及多轮视频编辑三种任务场景的结构化记录,形成了统一的分析框架。其构建过程涉及对原始视频及其关联的元数据文件(如meta.json、result.json和scenedetect.json)进行系统化处理,将这些非结构化信息转化为便于分析的表格化元数据。这一方法不仅确保了数据的一致性与可追溯性,还为研究者提供了深入探究视频创作流程中多镜头组合、场景转换及编辑轨迹等结构特性的基础。
特点
作为面向多模态视频研究的资源,Sora100K数据集展现出鲜明的特点。它涵盖了超过十万个视频样本,其中包含一万八千余个生成样本、近七万七千个单轮编辑样本以及八千余个多轮编辑链,构成了当前规模较为可观的视频生成与编辑数据集之一。该数据集以元数据层为核心发布内容,通过清晰的子集划分(文本到视频生成、单轮视频编辑、多轮视频编辑)支持跨任务比较与分析。其结构化设计便于进行元数据驱动的检索、过滤与基准测试,同时保留了样本标识符(如sample_id、source_post_id)以确保长期可引用性。
使用方法
在具体应用层面,研究者可通过Hugging Face平台加载数据集的元数据层,利用提供的配置名称分别访问不同任务子集。使用示例展示了如何通过load_dataset函数加载文本到视频生成、单轮及多轮视频编辑的元数据表格。由于数据集未直接分发原始视频文件,用户需依据元数据中的标识符与检索说明,从原始或授权来源获取对应视频资源。这种设计既支持基于元数据的分析与基准构建,也要求使用者在获取底层视频时遵守源平台的服务条款与版权规定,确保学术研究的合规性。
背景与挑战
背景概述
随着生成式人工智能技术的迅猛发展,视频生成与编辑领域正经历深刻变革。Sora100K数据集作为一项面向ACM MM 2026数据集赛道提交的大规模多模态视频资源,由相关研究团队于近期构建,旨在为文本到视频生成、单轮视频编辑及多轮视频编辑任务提供统一的元数据与分析框架。该数据集包含超过十万个视频样本,覆盖了从生成到复杂编辑链的完整工作流程,其核心研究问题聚焦于如何通过结构化元数据驱动对视频创作过程的多维度分析,包括多镜头构图、场景转换与编辑轨迹等深层结构特性。这一资源的出现,为视频生成模型的评估、编辑技术的创新以及创作流程的标准化研究奠定了重要基础,有望推动多模态视频理解与生成领域的实证研究迈向新的高度。
当前挑战
Sora100K数据集致力于解决视频生成与编辑领域中的核心挑战,即如何系统化地建模并评估从文本描述到复杂视频编辑序列的完整创作流程。具体而言,该数据集需要应对生成视频的语义保真度、编辑指令的连贯性以及多轮修改中的状态一致性等复杂问题。在构建过程中,研究团队面临多重挑战:首先,数据源涉及多样化的生成与编辑平台,需在尊重原始版权与访问条款的前提下,协调并统一不同来源的结构化记录;其次,将原始的JSON等非结构化元数据转换为适于分析的表格形式,并确保跨子集(生成、单轮编辑、多轮编辑)元数据的一致性与完整性,是一项繁重的工程;此外,数据集当前仅发布元数据层,而未直接分发原始视频文件,这要求设计稳健的检索工具与访问流程,以支持用户在遵守原始平台政策的前提下获取底层媒体,同时需处理临时链接过期等不稳定因素,确保长期研究的可重复性。
常用场景
经典使用场景
在视频生成与编辑研究领域,Sora100K数据集为探索文本到视频生成、单轮视频编辑及多轮视频编辑任务提供了统一框架。该数据集通过结构化元数据支持对多镜头构图、场景转换及编辑轨迹的分析,成为评估生成模型在复杂视频创作流程中表现的关键基准。研究人员可依据其丰富的任务设置,系统性地检验模型在保持视觉连贯性与语义一致性方面的能力,从而推动视频内容自动生成技术的演进。
实际应用
在实际应用中,Sora100K为视频内容创作平台提供了自动化编辑工具的研发基础。基于其元数据构建的检索与过滤系统,能够辅助实现智能视频剪辑、场景重组及风格化转换等功能。该数据集还可用于训练视频推荐算法,通过分析编辑轨迹理解用户创作意图,从而优化个性化内容生成服务。在影视后期与广告制作领域,其多轮编辑样本为自动化工作流的设计提供了宝贵参考。
衍生相关工作
围绕Sora100K衍生的经典工作主要集中在视频生成模型的基准测试框架构建上,例如基于其元数据开发的统一评估指标与跨任务性能对比研究。部分研究利用其编辑链数据探索视频语义连续性的保持机制,提出了多轮编辑中的一致性约束算法。此外,该数据集还催生了针对视频结构分析的深度学习方法,如基于场景检测元数据的时序建模网络,显著推动了视频内容理解与生成技术的交叉融合。
以上内容由遇见数据集搜集并总结生成


