doronys/synthmed-retina-hpp-sample
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/doronys/synthmed-retina-hpp-sample
下载链接
链接失效反馈官方服务:
资源简介:
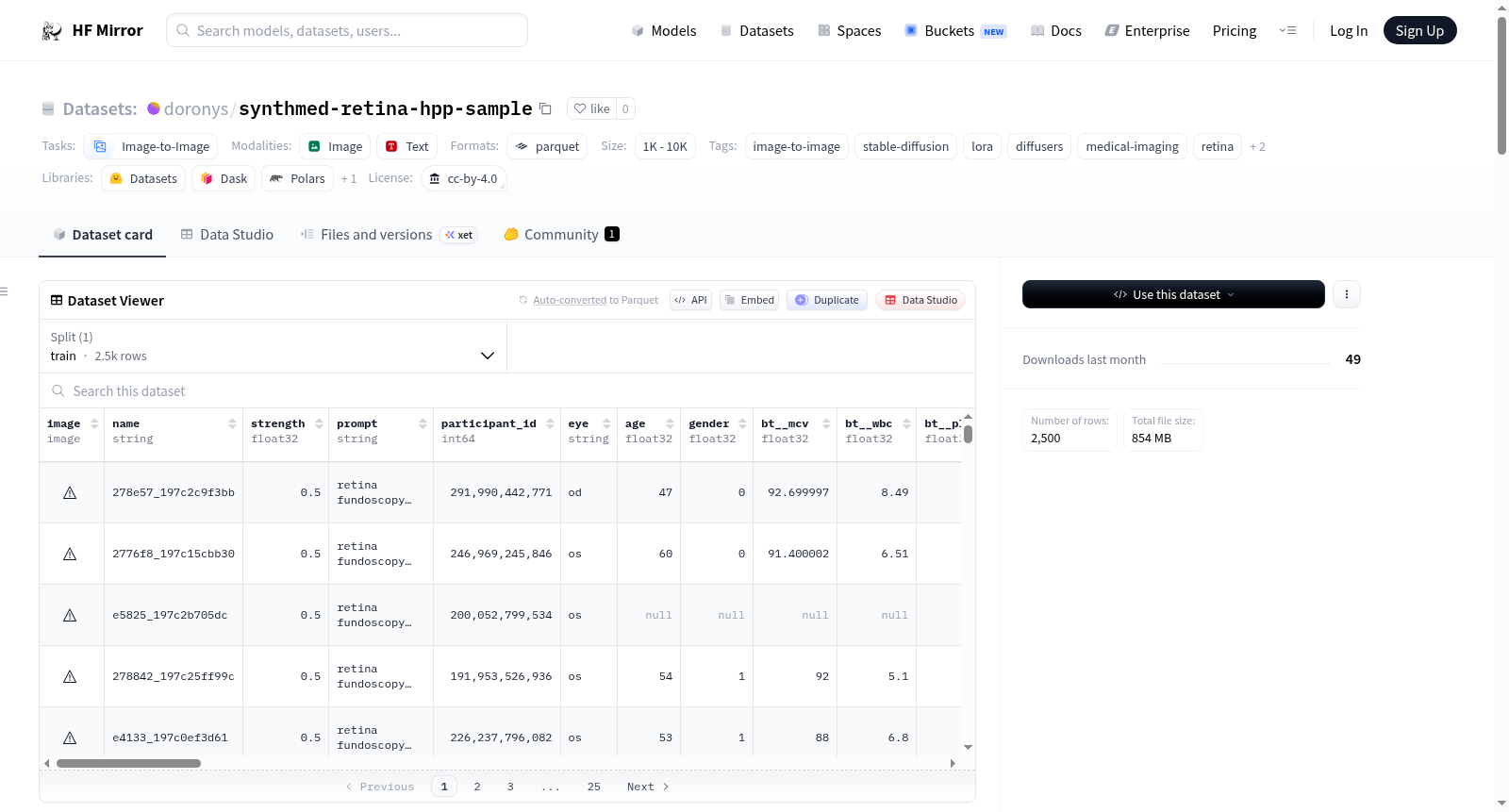
SynthMed Retina — HPP I2I样本数据集包含2,500张通过图像到图像(I2I)扩散技术生成的合成视网膜眼底图像,这些图像源自人类表型项目(HPP)10K队列的真实眼底照片。每张合成图像都配有匿名化的患者元数据,包括人口统计学信息(年龄、性别)、血液检查指标(血红蛋白、胆固醇等)、血压和身体测量数据等。该数据集是为评估I2I扩散作为医学图像去识别化方法的有效性而创建的,研究发现在强度为0.5时,能显著降低再识别风险(约20%)同时保持较高的生物标志物一致性(Pearson r≈0.7)。技术实现上使用了Stable Diffusion v1-4基础模型和特定的LoRA适配器(hpp-retina),采用DDIM调度器进行50步推理,生成分辨率为512×512的图像。
The SynthMed Retina — HPP I2I Sample dataset contains 2,500 synthetic retinal fundus images generated via image-to-image (I2I) diffusion from the Human Phenotype Project (10K) cohort, paired with anonymized patient metadata. This includes demographic data (age, gender), blood test metrics (hemoglobin, cholesterol, etc.), blood pressure, and anthropometric measurements. Created to evaluate I2I diffusion as a medical image de-identification approach, the study found that at strength=0.5, it reduces top-1 re-identification rate to ~20% while maintaining high biomarker agreement (Pearson r≈0.7). Technically, it uses Stable Diffusion v1-4 with a specific LoRA adapter (hpp-retina), DDIM scheduler for 50 inference steps, producing 512×512 resolution images.
提供机构:
doronys
搜集汇总
数据集介绍
构建方式
该数据集源自人类表型项目(HPP)10K队列的真实视网膜眼底照片,采用图像到图像(I2I)扩散生成技术构建。具体而言,研究团队以CompVis/stable-diffusion-v1-4作为基础模型,并适配hpp-retina LoRA适配器(秩为64,alpha为32),在DDIM调度器下进行50步推理,固定I2I强度为0.5。每张源图像仅生成一张512×512像素的RGB合成图像,最终产出2,500张视网膜合成图像,同时配以匿名化的患者元数据。
使用方法
使用者可通过HuggingFace的datasets库直接加载数据集,调用load_dataset("doronys/synthmed-retina-hpp-sample", split="train")即可获取训练集。每个样本包含PIL.Image格式的图像以及所有元数据列,例如通过example["prompt"]获取生成提示词、example["age"]获取年龄。数据集采用CC BY 4.0许可协议,允许自由使用、分享和改编,但需注明出处。需注意,原始源图像并未包含在数据集中,仅释放了合成输出和匿名化元数据。
背景与挑战
背景概述
SynthMed Retina — HPP I2I Sample数据集由Doron Yaya-Stupp、Guy Lutsker、Or Spiegel和Eran Segal等研究人员于2026年创建,旨在通过图像到图像(I2I)扩散模型生成合成视网膜眼底图像,以解决医疗影像数据共享中的隐私保护难题。该数据集源自Human Phenotype Project(HPP)10K队列,包含2,500张512×512的RGB合成视网膜图像及去标识化的患者元数据,如年龄、性别、血液生物标志物等。研究证明,在0.5的I2I强度下,合成图像在保持结构保真度的同时,将重新识别风险降至约20%,且生物标志物一致性(如血红蛋白的Pearson r系数)仍维持在0.7左右。该数据集为医学影像的隐私保护数据发布提供了可行方案,并支持跨队列迁移学习,对推动计算机辅助诊断和流行病学研究具有重要影响。
当前挑战
SynthMed Retina数据集面对的核心挑战是平衡合成图像的隐私保护与生物医学效用。一方面,直接共享原始视网膜眼底图像因其高度识别性和敏感性而受限于伦理与法律约束,迫切需要一种既能降低重新识别风险又能保留诊断相关特征的数据生成方法。另一方面,构建过程中需精细控制I2I扩散强度,以在结构保真度与匿化安全性之间寻找最优权衡;此外,还需处理多模态元数据中的缺失值(如部分生物标志物为null)并采用标准化编码策略,同时确保跨队列迁移时合成数据的泛化能力不会显著下降。这些挑战共同要求数据集在隐私保护水平、图像质量及临床相关性之间实现高度协调。
常用场景
经典使用场景
在医学图像合成与隐私保护领域,SynthMed Retina HPP Sample数据集凭借其独特的图像到图像扩散生成机制,成为了评估合成图像在结构保真度与去识别风险之间权衡的经典基准。研究者常采用该数据集作为验证平台,通过调节扩散强度参数,系统性地分析合成视网膜眼底图像在保留真实解剖结构细节的同时,如何有效降低患者重新识别几率。这一使用场景不仅为后续的隐私安全医学图像共享提供了可量化标准,也推动了合成医学图像在临床研究与数据发布中的可信应用。
解决学术问题
该数据集有针对性地解决了医学图像共享中隐私保护与数据可用性之间的矛盾这一核心学术难题。通过引入图像到图像扩散模型并系统评估不同条件下的去识别效果,研究表明在扩散强度为0.5时,能够将患者重新识别率从较高水平降低至约20%,同时维持血红蛋白等关键生物标志物的一致性相关系数在0.7左右。这一发现为学术界提供了一种实用的隐私保护框架,使得在不牺牲数据科学价值的前提下,实现医学图像的安全公开,对促进多中心协作研究具有重要意义。
实际应用
在实际应用中,SynthMed Retina HPP Sample数据集展示了跨队列迁移的巨大潜力。研究显示,在该合成图像上预训练的疾病分类器,当其迁移至真实的UK Biobank眼底图像数据并进行微调时,其性能与采用真实图像预训练的模型相当。这一结果表明该合成数据集可以作为一种低成本、隐私安全的预训练资源,助力医院和科研机构在缺乏大规模真实标注数据的情况下,快速构建可靠的视网膜疾病筛查系统,推动人工智能眼科学临床落地的进程。
数据集最近研究
最新研究方向
基于图像到图像扩散模型的医学图像去标识化合成技术,正成为隐私保护与数据共享的前沿方向。SynthMed Retina — HPP I2I Sample数据集通过LoRA微调的条件扩散模型,从真实视网膜眼底图像生成合成副本,在0.5的扩散强度下实现了再识别率降至约20%的同时,保持了血红蛋白等生物标志物约0.7的Pearson相关性,展示了隐私-效用权衡的精准调控潜力。该研究还揭示,基于合成图像预训练的模型在跨队列迁移至英国生物样本库数据时,性能与真实图像预训练相当,为大规模医学图像开放共享提供了可行路径。这一工作呼应了全球对医疗数据隐私合规的迫切需求,推动了去标识化合成数据在临床研究、多中心协作和负责任AI开发中的实际应用。
以上内容由遇见数据集搜集并总结生成


