aditijc/snooker-testbed-canary-7055319-rewardshape-v1
收藏Hugging Face2026-04-24 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/aditijc/snooker-testbed-canary-7055319-rewardshape-v1
下载链接
链接失效反馈官方服务:
资源简介:
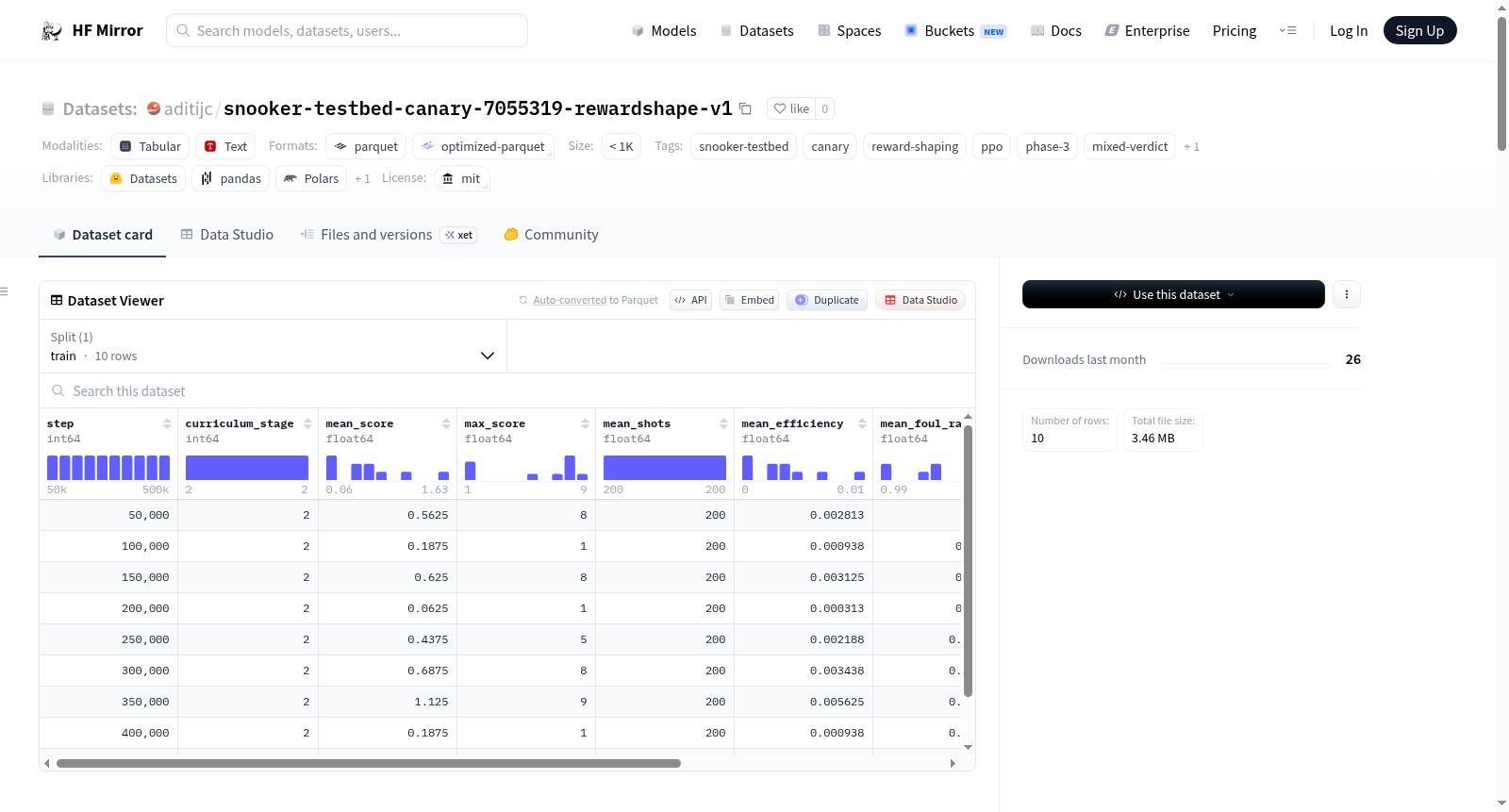
该数据集与使用强化学习(特别是近端策略优化PPO)和奖励塑造的斯诺克测试台实验相关。数据集包含训练过程中的指标,如得分、犯规率和其他性能指标。实验旨在提高策略合法接触球的能力,但在犯规率和得分表现方面遇到了挑战。数据集包括10行和9列,详细描述了训练和评估过程的各个方面。
This dataset is related to a snooker testbed experiment using reinforcement learning, specifically Proximal Policy Optimization (PPO) with reward shaping. The dataset contains metrics from the training process, including scores, foul rates, and other performance indicators. The experiment aimed to improve the policys ability to contact balls legally but encountered challenges with foul rates and score performance. The dataset includes 10 rows and 9 columns, detailing various aspects of the training and evaluation process.
提供机构:
aditijc
搜集汇总
数据集介绍
构建方式
该数据集源自一项针对斯诺克智能体强化学习策略的探索性实验,具体构建于Phase-3 Option-C金丝雀测试框架之上。研究者在渐进的stage-0课程学习与每工作线程回合追踪机制基础上,引入了一种名为“hit-any-ball”的奖励塑形策略:每当球杆与任何目标球发生接触,智能体便获得+2.0的密集奖励。实验采用稳定基线库中的PPO算法,搭载MlpPolicy网络架构([256,256]),总计运行50万时间步,最终采集了10条高维训练状态记录。每条记录均包含全局时间步、课程阶段、平均得分、最大得分、平均回合次数、效率、犯规率、评估回合数及数据源文件路径等九项核心指标,构成了一组紧凑而信息丰富的训练快照。
使用方法
本数据集可通过Hugging Face的datasets库直接加载使用,推荐调用`load_dataset("aditijc/snooker-testbed-canary-7055319-rewardshape-v1", split="train")`方法获取全部10条训练记录。研究者可借助`mean_score`、`mean_foul_rate`与`mean_efficiency`等字段,快速复现并评估奖励塑形策略在斯诺克任务中的阶段性效果。对于希望深入分析策略退化原因的用户,建议结合`curriculum_stage`与`step`字段构建时间序列,观察策略性能随训练进程的演变轨迹。此外,数据集中记录的50个近期回合奖励数值,可用于探索奖励方差随梯度优化推进的变化规律。
背景与挑战
背景概述
在深度强化学习与智能体控制的交叉领域中,稀疏奖励问题长期是阻碍策略收敛的核心瓶颈,尤其在台球这类需要精确序列决策的任务中尤为突出。为破解这一困境,snooker-testbed-canary-7055319-rewardshape-v1数据集应运而生,其由研究者于2026年4月构建,依托snooker-testbed实验平台,聚焦于通过奖励塑形方法引导智能体学会台球击球动作中的合法触球策略。该数据集记录了近50万时间步的PPO训练过程中的关键指标,包含10条样本、9个字段,全面涵盖得分、击球效率、犯规率及课程阶段等信息。作为Phase-3 Option-C的金丝雀测试,其核心贡献在于验证了密集奖励惩罚机制(每球杆-球接触+2.0)能否打破梯度消失与熵值停滞的僵局,为复杂物理模拟环境中的奖励设计提供了实证参考,对稀疏奖励、课程学习及策略熵调控等研究方向具有重要启发意义。
当前挑战
该数据集所面对的挑战本质上源于台球任务中稀疏奖励与合法动作歧义性的叠加困境。在算法层面,智能体虽通过密集奖励学会了“接触球”的基本行为,但由于缺乏对“接触合法球”的语义区分,峰值得分仅1.62,远逊于随机基线2.10,且犯规率始终维持在98%-99%的高位,显示策略陷入了次优局部解。在构建层面,数据集生成过程中经历了严峻的工程挑战:如何在保持策略方差下降的同时避免梯度退化,如何设置hit-any-ball奖励的衰减调度以防止过度强化,以及如何在有限训练步数内平衡课程阶段的推进与探索效率。最终数据集以混合判决告终,揭示了单纯增加接触奖励不足以解决合法-非法动作的区分难题,亟需更精细的奖励调度机制或语义感知架构来突破瓶颈。
常用场景
经典使用场景
在深度强化学习与复杂物理仿真环境的交叉研究领域,斯诺克台球因其高维状态空间、稀疏奖励与严格的规则约束,成为评估智能体探索与利用能力的理想试验场。snooker-testbed-canary-7055319-rewardshape-v1 数据集的核心用途在于系统性地剖析基于奖励塑形(reward shaping)的PPO算法在长时序决策任务中的行为演变。通过对每个训练步的课程阶段、平均得分、犯规率及策略标准差等关键指标进行细粒度记录,研究者能够精准追踪密集奖励信号如何影响策略熵的衰减趋势以及梯度流动的动态平衡。该数据集尤其适合用于验证稀疏奖励环境下‘接触任意球’与‘接触合法球’之间的语义鸿沟,为揭示奖励塑形在引导策略探索与约束行为合规性之间的张力提供定量依据。
解决学术问题
该数据集直面深度强化学习中一个长期存在的棘手问题:在稀疏奖励场景下,如何设计辅助奖励函数以打破熵与梯度的僵局,同时避免误导智能体形成次优行为模式。实验数据清晰表明,尽管+2.0的‘接触任意球’密集奖励成功促使策略标准差首次出现下降(0.990→0.923),但最高评估得分(1.62)仍低于随机基线(2.10),且犯规率持续高居98%-99%。这一矛盾现象揭示了奖励塑形带来的‘奖励黑客’风险——智能体学会了增加接触频次却未能理解合法目标球的约束。该数据集为学术界验证‘奖励渐退调度’、‘课程学习与塑形协同’等假设提供了无偏的实证基座,推动了对于奖励设计在策略探索深度与行为语义对齐之间平衡关系的理论认知。
实际应用
在机器人操作与自动控制等实际工程应用中,该数据集所揭示的奖励塑形陷阱具有直接借鉴意义。例如,在工业机械臂执行零件装配任务时,若简单给予‘接触工件’的正向奖励,机械臂可能习得频繁触碰而非精准插入的无效行为。数据集提供的策略标准差变化曲线、课程阶段演进与犯规率演变等高维时序指标,可作为安全关键系统的奖励信号设计模板,帮助工程师提前诊断‘合法动作识别’缺失所导致的策略退化。此外,该数据集还可用于验证自适应奖励缩放或双课程学习(行为课程+奖励课程)等实际部署方案,确保在仿真到现实的迁移中,策略在保持探索活力的同时不违反物理规则与安全边界。
数据集最近研究
最新研究方向
在强化学习与台球模拟环境的交叉前沿,该数据集聚焦于通过奖励塑形策略破解稀疏奖励环境中的探索困境。当前研究热点在于平衡密集奖励信号与策略熵的关系——实验验证了基于触碰任意球的即时奖励(+2.0/次)能首次促使策略标准差在训练过程中下降(0.990→0.923),打破熵与梯度间的僵局。然而,峰值评估得分1.62低于随机基线2.10,且犯规率持续高达98-99%,揭示出策略虽学会触碰球体却未能瞄准合规目标球的根本局限。这一矛盾为后续研究指明方向:需设计衰减型奖励调度,或利用已激活的梯度流进行更长程训练,以实现从机械奖惩响应到规则内化语义理解的跨越。该工作为复杂物理模拟中细粒度引导信号的时序设计与空间泛化提供了关键实证。
以上内容由遇见数据集搜集并总结生成


