ai4privacy/pii-masking-43k
收藏Hugging Face2026-04-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ai4privacy/pii-masking-43k
下载链接
链接失效反馈官方服务:
资源简介:
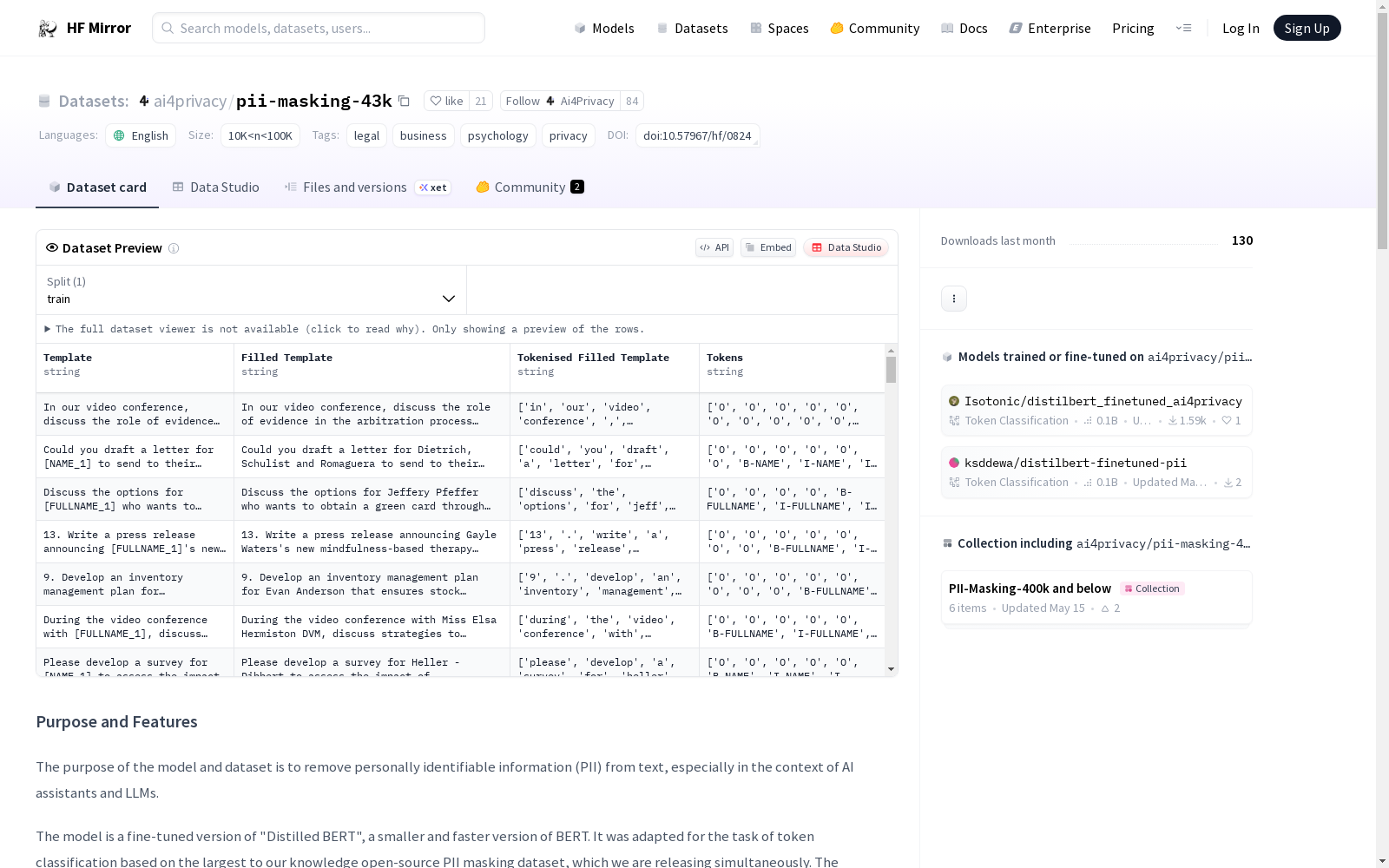
该数据集的主要目的是从文本中移除个人可识别信息(PII),特别是在AI助手和大型语言模型(LLMs)的背景下。数据集包含约43,000条观察数据,每条数据以自然语言句子开始,句子中包含PII的占位符,并用模拟的个人信息填充,然后使用BERT分词器进行分词,并标记出与PII对应的分词作为训练模型的真实标签。数据集涵盖了PII可能出现的多种上下文,包括商业、心理学和法律领域,以及5种交互风格。
The primary purpose of this dataset is to remove Personally Identifiable Information (PII) from text, particularly in the context of AI assistants and Large Language Models (LLMs). The dataset contains approximately 43,000 observations. Each entry starts with a natural language sentence that contains placeholders for PII, which are filled with simulated personal information. The sentences are then tokenized using the BERT tokenizer, and the tokens corresponding to PII are labeled as the ground truth for model training. The dataset covers a wide range of contexts where PII may appear, including commercial, psychological, and legal domains, as well as five interaction styles.
提供机构:
ai4privacy
原始信息汇总
数据集概述
数据集目的与特征
- 目的:移除文本中的个人身份信息(PII),特别是在AI助手和大型语言模型(LLMs)的上下文中。
- 模型:基于“Distilled BERT”的微调版本,专为标记分类任务设计,模型大小为6200万参数,压缩后大小为43MB。
- 数据集构成:约43,000个观测值,每个观测值包含一个包含PII占位符的自然语言句子,随后填充模拟的个人信息并使用BERT分词器进行分词。
- 数据集覆盖范围:涉及54种敏感数据类型,约111个标记类别,涵盖125个讨论主题/用例,跨越商业、心理学和法律领域,以及5种交互风格。
数据集关键事实
- 当前规模:560万标记,包含43,000个PII示例。
- 未来扩展:计划扩展至10万示例。
- 验证方式:通过人机交互验证。
- 数据生成:使用专有算法生成的合成数据。
- 模型框架:基于PyTorch。
- 量化级别:8位量化。
性能评估
- 测试精度:0.998636
- 测试召回率:0.998945
- 测试准确率:0.994621
- 训练/测试集分割:4300个测试示例(10%),38,700个训练示例。
应用场景
- 聊天机器人
- 客户支持系统
- 电子邮件过滤
- 数据匿名化
- 社交媒体平台
- 内容审核
- 在线表单
- 协作文档编辑
- 研究和数据共享
- 内容生成
支持与维护
- 项目隶属:AI4Privacy项目隶属于AISuisse SA。
搜集汇总
数据集介绍
构建方式
该数据集的构建以深度学习模型Distilled BERT为基础,通过对其参数进行微调,以实现文本中个人身份信息(PII)的自动识别与遮蔽。数据集由约43,000条观测构成,每一条观测均包含一个自然语言句子,并以内置的占位符代表PII,随后使用BERT分词器对这些句子进行分词处理,并将对应的PII标记为真实值以训练模型。数据集涵盖了54种敏感数据类型,并在商业、心理学和法务领域针对125种不同的讨论主题或使用场景进行构建。
特点
本数据集的特点在于其广泛的应用场景和精细的构建细节。它包含5.6百万个标记,其中43,000个为PII示例,且数据集规模有望进一步扩大至100,000个示例。数据集经过人工在环验证,确保了数据质量,并采用专有算法生成合成数据。此外,数据集支持8位量化,以减小模型体积,提升泛化能力。
使用方法
使用该数据集时,用户可将其集成至聊天机器人、客户支持系统、电子邮件过滤、数据匿名化、社交媒体平台、内容审查、在线表单、协作文档编辑以及研究数据共享等多种应用场景。数据集提供了与PyTorch框架兼容的模型,并可通过订阅Newsletter获取最新的维护和更新信息。
背景与挑战
背景概述
在人工智能助手和大型语言模型的应用场景中,保护个人隐私信息(PII)至关重要。'ai4privacy/pii-masking-43k' 数据集应运而生,旨在通过深度学习模型自动从文本中识别并移除PII。该数据集由AI4Privacy团队开发,是与Distilled BERT模型微调相伴的产物,后者是一种更小、更快的BERT版本。数据集包含了约43,000条观测记录,涵盖了54种敏感数据类型,涉及商业、心理和法律等多个领域的125种讨论主题或用例。该数据集的创建,不仅为模型训练提供了丰富的基准,也对隐私保护领域的研究产生了深远影响。
当前挑战
该数据集在构建过程中面临的挑战主要包括:确保数据覆盖广泛且具有代表性,以适应不同场景下的PII识别;合成数据的质量控制,以保证模型训练的有效性和泛化能力;以及模型性能的优化,以实现在保持高精度的同时减少模型大小,增强其在实际应用中的可用性。此外,数据集在解决PII识别领域问题时,也面临着如何平衡隐私保护与数据可用性之间的挑战,以及在多语言环境下如何提高模型适用性的问题。
常用场景
经典使用场景
在隐私保护领域,'ai4privacy/pii-masking-43k'数据集的典型应用场景在于文本中个人身份信息(PII)的自动识别与遮蔽。该数据集支持的研究人员能够构建并优化模型,以识别并处理包含敏感个人数据的文本,如姓名、地址、电话号码和电子邮件地址等,确保在多种语境下个人信息的安全。
解决学术问题
该数据集解决了学术研究中对个人隐私信息保护的迫切需求。通过提供大规模的标注数据,它帮助研究人员克服了在自然语言处理中准确识别和遮蔽PII的挑战,从而推动了隐私保护技术的发展,并在法律、商业和心理学等多个领域产生了深远的影响。
衍生相关工作
基于此数据集,已经衍生出了一系列相关的工作,包括多语言PII遮蔽模型的开发、现有开源解决方案的集成、数据集规模的持续扩大以及模型的进一步优化,以减少模型大小并提高泛化能力。这些工作进一步推动了隐私保护技术的发展和应用。
以上内容由遇见数据集搜集并总结生成


