mdn
收藏Hugging Face2026-04-05 更新2026-04-06 收录
下载链接:
https://huggingface.co/datasets/deepsweet/mdn
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个预处理的LanceDB集合,包含来自MDN Web Docs的50,000多行数据,主要用于与配套的RAG-MCP服务器结合使用,支持语义搜索和混合向量(1024维)与全文(BM25)检索。数据集涵盖了MDN核心文档部分,包括Web API、JavaScript、HTML、CSS、SVG和HTTP。原始内容以自定义Markdown格式存储,经过处理转化为结构化纯文本,并分割为有意义的独立块。数据嵌入使用了BGE-M3模型(1024维,8192 tokens)。数据集作为MDN Web Docs的衍生作品,遵循复杂的许可协议:散文内容采用CC-BY-SA-2.5许可,2010年8月20日及之后添加的代码示例和片段为公共领域(CC0),之前的则采用MIT许可。所有代码示例在分块过程中未作修改,按原样提供。
This dataset is a preprocessed LanceDB collection containing over 50,000 rows of data sourced from MDN Web Docs. It is primarily intended for use with the accompanying RAG-MCP server, supporting semantic search and hybrid retrieval that combines 1024-dimensional vector search and full-text (BM25) retrieval.
The dataset covers core sections of MDN documentation, including Web API, JavaScript, HTML, CSS, SVG, and HTTP. The original content was stored in a custom Markdown format, processed into structured plain text, and split into semantically meaningful independent chunks. Data embeddings were generated using the BGE-M3 model (1024 dimensions, 8192 tokens).
As a derivative work of MDN Web Docs, this dataset is governed by complex licensing terms: prose content is licensed under CC-BY-SA-2.5, code examples and snippets added on or after August 20, 2010 are released into the public domain (CC0), while those added prior to this date are licensed under MIT. All code examples remained unmodified during the chunking process and are provided as-is.
创建时间:
2026-04-01
原始信息汇总
数据集概述
基本信息
- 数据集名称: deepsweet/mdn
- 许可证: 其他 (基于原始MDN Web Docs内容的复杂许可证)
- 许可证链接: https://github.com/mdn/content/blob/main/LICENSE.md
- 语言: 英语 (en)
- 标签: rag, embeddings, lancedb
数据内容与来源
- 数据来源: MDN Web Docs (https://developer.mozilla.org/)
- 数据形态: 预构建的LanceDB数据库,包含超过50,000行数据。
- 覆盖内容: 核心MDN文档部分,包括:
- Web API
- JavaScript
- HTML
- CSS
- SVG
- HTTP
- 数据处理: 原始的自定义Markdown格式内容经过处理,转换为结构化的纯文本,并进行语义分块,形成有意义的独立文本块。分块过程没有严格的令牌限制或重叠。
技术细节
- 嵌入模型: BGE-M3 (1024维,8192令牌)
- 模型版本: 量化版本 Q4_K_M GGUF (https://huggingface.co/deepsweet/bge-m3-GGUF-Q4_K_M)
- 检索支持: 支持混合向量(1024维)和全文(BM25)检索的语义搜索。
- 使用建议: 为获得正确的相似度,在查询嵌入时强烈建议使用完全相同的模型。
主要用途
- 主要设计用于配套的RAG-MCP服务器 (https://github.com/deepsweet/mdn),以实现语义搜索。
- 其他符合许可证要求的用途也欢迎。
许可证说明
- 本数据集是基于原始MDN Web Docs内容的“衍生作品”。
- 原始内容许可证复杂,包含多种条款:
- “散文”内容采用CC-BY-SA-2.5许可证。
- 2010年8月20日或之后添加的代码示例和片段属于公共领域 (CC0)。
- 2010年8月20日之前添加的代码示例和片段采用MIT许可证。
- 代码示例在分块步骤中未作显式修改,按原样提供。
- 本数据集整体遵循相同条款提供,不主张新的版权。
更多信息
- 详细使用说明请参阅GitHub上的开发仓库:https://github.com/deepsweet/mdn
搜集汇总
数据集介绍
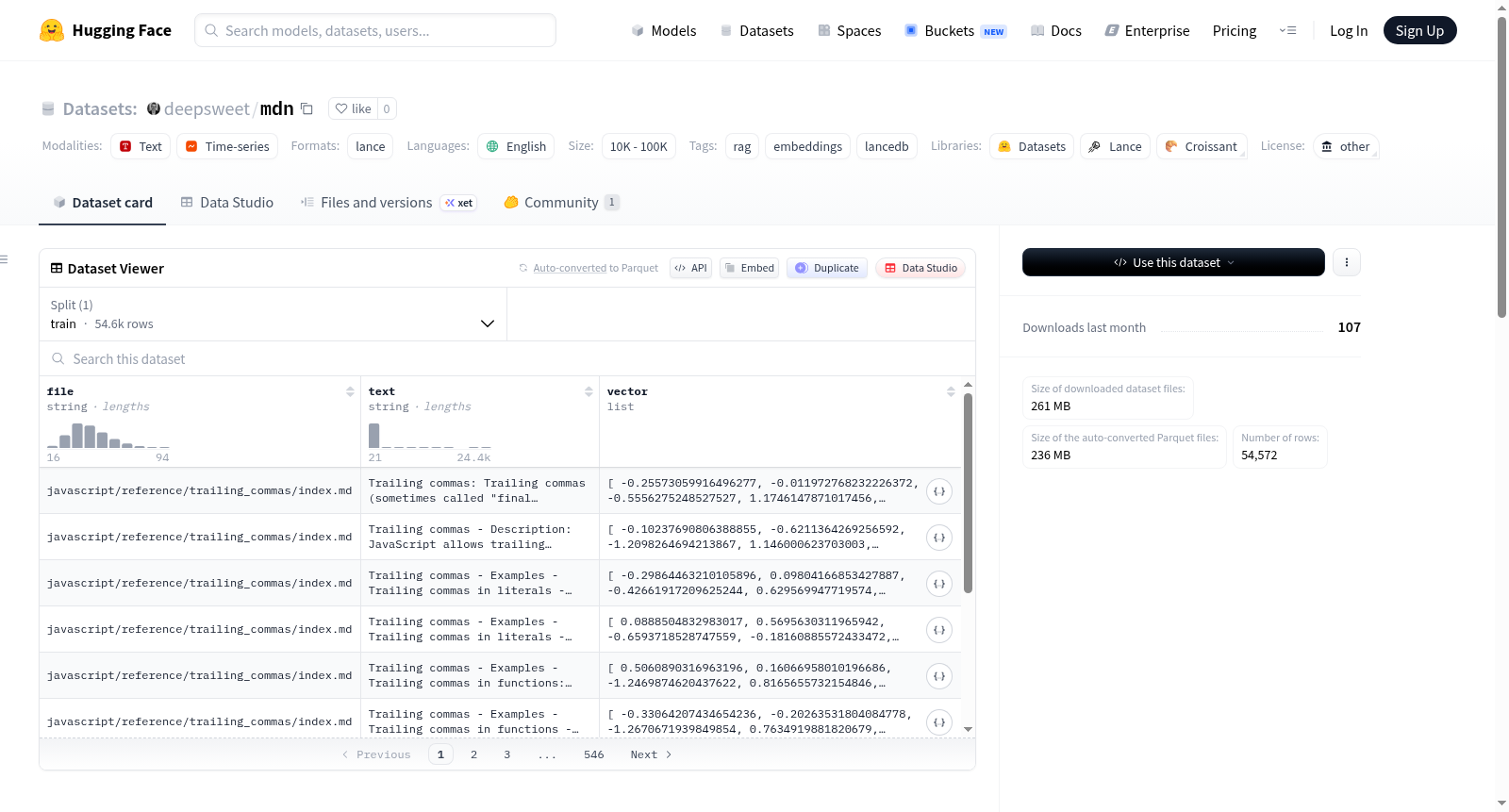
构建方式
在构建MDN数据集的过程中,开发者从MDN Web Docs的原始内容中提取了超过五万行数据,覆盖了Web API、JavaScript、HTML、CSS、SVG和HTTP等核心文档部分。原始内容采用自定义的Markdown格式,经过系统化处理转化为结构清晰的纯文本,并通过语义分割技术将其划分为独立的文本块,避免了硬性的令牌限制或重叠,确保了每个块在语义上的完整性。数据嵌入阶段采用了BGE-M3模型,该模型具有1024维向量和8192令牌的容量,具体使用了量化版本的GGUF格式,为后续的语义检索奠定了高质量的基础。
特点
该数据集的主要特点在于其专为检索增强生成(RAG)应用而设计,支持混合向量和全文检索机制。通过BGE-M3模型生成的1024维向量嵌入,结合BM25算法进行全文搜索,实现了高效的语义匹配与关键词检索的融合。数据集内容经过精心处理,保留了原始文档的结构化信息,同时以语义块的形式呈现,便于机器理解和处理。此外,数据集严格遵循MDN的复杂许可协议,确保了法律合规性,为用户提供了可靠且权威的Web开发知识资源。
使用方法
使用MDN数据集时,建议与配套的RAG-MCP服务器结合,以实现语义搜索功能。用户需要采用与数据嵌入相同的BGE-M3模型进行查询嵌入,以保证相似性计算的准确性。数据集适用于构建智能文档检索系统、知识库问答或教育工具等场景,开发者可通过GitHub上的开发仓库获取详细的使用指南和技术支持。在应用过程中,应注意遵守数据集的许可条款,合理使用其中的文本和代码示例,以促进Web开发领域的知识传播与创新。
背景与挑战
背景概述
MDN数据集源于对MDN Web Docs这一权威网络开发文档资源的系统化处理与重构,由开发者社区于2024年创建并发布。该数据集旨在为检索增强生成(RAG)系统提供高质量、结构化的语义检索基础,核心研究问题聚焦于如何将非结构化的技术文档转化为适于向量检索的标准化文本块,以支持大语言模型在编程辅助、代码生成等场景下的精准知识调用。其出现显著推动了开发工具智能化进程,为构建专业领域的垂直检索系统设立了实践范例。
当前挑战
该数据集致力于解决网络开发知识检索中的语义理解与精准匹配挑战,其核心在于从异构且嵌套的原始Markdown文档中提取出保持逻辑完整性的独立文本单元,同时需平衡代码片段与说明文本的表示一致性。构建过程中的主要困难体现在对MDN复杂文档结构的语义分割策略设计,以及如何选用适配的嵌入模型以确保检索结果的相关性与准确性,此外还需妥善处理原始内容中混合的多重许可协议,保障数据衍生产品的合规性。
常用场景
经典使用场景
在Web开发与文档检索领域,MDN数据集常被用作检索增强生成(RAG)系统的核心知识库。其经典使用场景涉及构建智能文档助手,通过语义搜索与混合检索机制,快速定位并整合MDN Web Docs中的技术内容,为开发者提供精准的API参考、代码示例及概念解释。该数据集经过精细分块与向量化处理,确保了检索结果的相关性与完整性,显著提升了技术文档的查询效率与用户体验。
实际应用
在实际应用层面,MDN数据集广泛集成于开发工具与教育平台中,赋能智能代码编辑器、在线学习系统及技术支持聊天机器人。它使开发者能够通过自然语言查询即时获取Web技术文档,辅助调试、教学与项目开发;同时,企业可将其部署为内部知识管理系统,加速团队的技术资源共享与协作。这些应用显著降低了技术门槛,提升了开发效率与知识传播的覆盖面。
衍生相关工作
围绕MDN数据集,已衍生出多项经典研究工作,例如基于LanceDB的混合检索架构优化、针对代码与文本混合内容的嵌入模型微调策略,以及跨语言文档检索系统的扩展探索。这些工作不仅深化了RAG技术在专业领域的实践,还催生了开源工具链(如配套的RAG-MCP服务器)与评估基准,为后续的文档处理、语义搜索及知识库构建研究提供了重要参考与基础设施支持。
以上内容由遇见数据集搜集并总结生成


