Clinvar_SNV_GnomAD_Pathogen_Variants
收藏Hugging Face2026-01-16 更新2026-01-17 收录
下载链接:
https://huggingface.co/datasets/YADAV0206/Clinvar_SNV_GnomAD_Pathogen_Variants
下载链接
链接失效反馈官方服务:
资源简介:
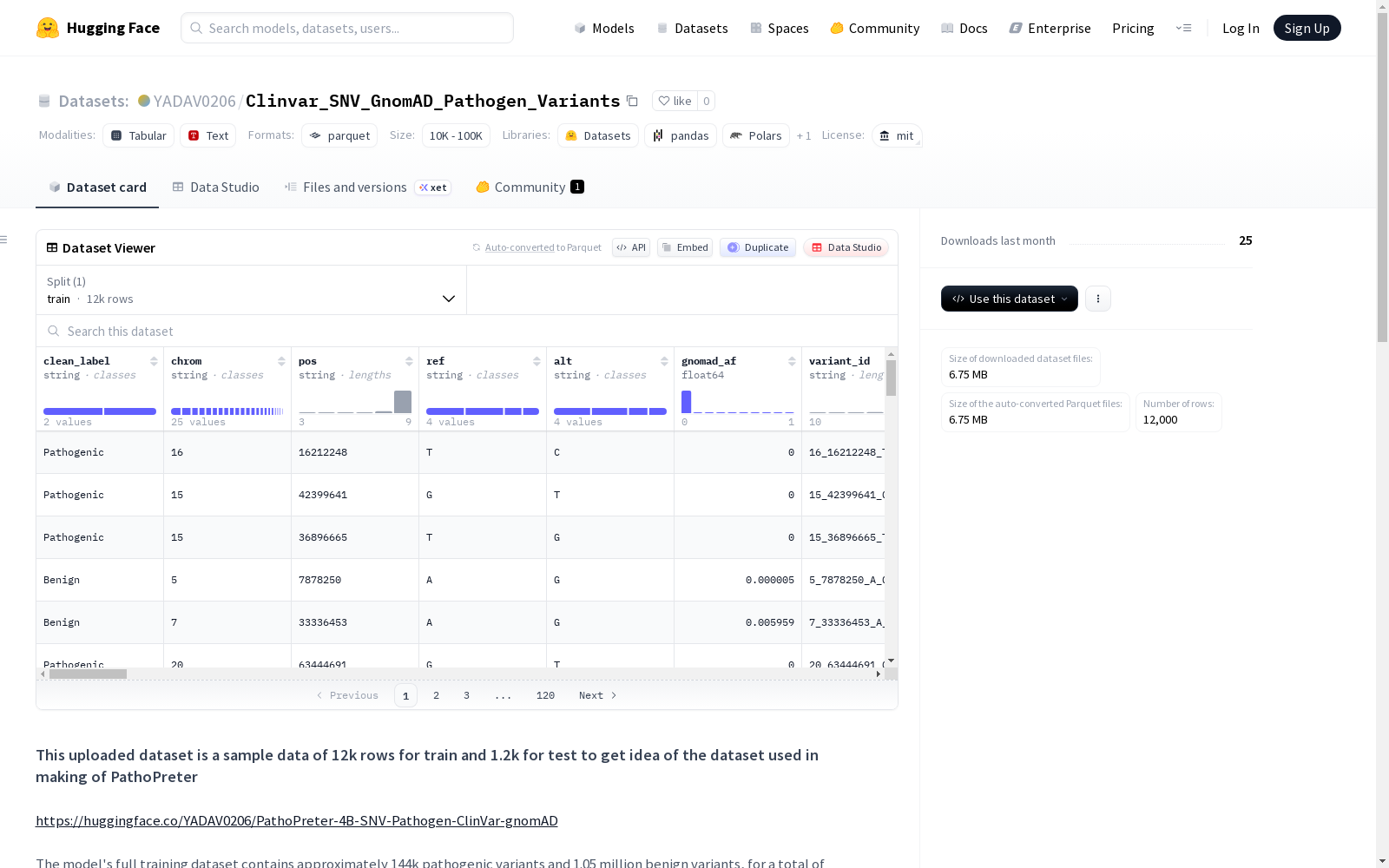
该数据集是用于PathoPreter模型训练和测试的样本数据,包含12k行训练数据和1.2k行测试数据。完整训练数据集包含约144k致病性变异和1.05百万良性变异,总计约1.2百万样本。测试数据集包含55k样本,并进行了11次独立的消融测试。数据集基于公开的基因组资源(如ClinVar和gnomAD)构建,经过大规模提取、规范化、质量控制等处理步骤。数据集可用于基因组学、AI/ML模型开发、基准测试等,需通过联系作者获取许可。
This dataset is sample data for training and testing the PathoPreter model, containing 12,000 training instances and 1,200 test instances. The full training dataset comprises approximately 144,000 pathogenic variants and 1.05 million benign variants, with a total of around 1.2 million samples. The test dataset includes 55,000 samples and has undergone 11 independent ablation tests. It is constructed based on public genomic resources such as ClinVar and gnomAD, and has gone through processing steps including large-scale extraction, standardization, and quality control. This dataset can be used for genomics research, AI/ML model development, benchmark testing and other related scenarios. Permission to access the dataset must be obtained by contacting the authors.
创建时间:
2026-01-11
原始信息汇总
数据集概述
基本信息
- 数据集名称: Clinvar_SNV_GnomAD_Pathogen_Variants
- 许可证: MIT
- 发布者: Rohit Yadav
- 发布者联系方式: yrohit1825@gmail.com
- 相关项目链接: https://github.com/YADAV1825/PathoPreter
- 关联模型链接: https://huggingface.co/YADAV0206/PathoPreter-4B-SNV-Pathogen-ClinVar-gnomAD
数据集内容与规模
- 本页面上传的数据集是一个样本数据,用于展示用于构建PathoPreter模型的数据集概况。
- 样本数据规模:
- 训练集: 12,000行
- 测试集: 1,200行
- 完整训练数据集规模:
- 约包含144,000个致病变异和1.05百万个良性变异。
- 总计约120万个样本。
- 完整测试数据集规模:
- 包含55,000个不同的样本。
- 进行了11项独立的消融测试(基于相同的55,000行数据),总计产生约660,000个测试样本(12 * 55,000)。
数据来源与构建
- 数据来源于公开的、允许商业使用和再分发的基因组资源,如ClinVar和gnomAD。
- 原始数据处理了约800万个ClinVar变异和约250 GB的gnomAD VCF数据。
- 数据构建过程包括大规模提取、标准化、模式统一、质量控制、去重以及严格的训练-测试集分离。
- 构建过程总计消耗约150小时的计算时间和超过250小时的专家工程与整理工作。
数据集组件与格式
- 可用组件包括:
- 大规模ClinVar风格的单核苷酸变异训练数据集。
- 包含跨消融测试相同变异体的留出测试集。
- 受控消融数据集(用于信号移除研究)。
- 用于鲁棒性评估的“假变异”数据集。
- 适用于经典机器学习训练的平衡CSV子集。
- 数据审计和泄漏验证脚本。
- 数据格式:同时提供Parquet和CSV格式。
数据获取与使用
- 本页面数据集为公开样本数据。
- 完整数据集(包括上述所有组件)需通过联系发布者获取,并可能涉及许可授权。
- 数据集可用于应用基因组学、AI/ML模型开发、基准测试、变异优先级排序工作流和内部研究。
- 商业许可、再分发条款和支持选项需根据具体需求进行协商。请求将按个案评估。
搜集汇总
数据集介绍
构建方式
在基因组学与生物信息学领域,高质量的数据集对于推进致病性变异预测研究至关重要。Clinvar_SNV_GnomAD_Pathogen_Variants数据集的构建依托于公开可用的基因组资源,包括ClinVar与gnomAD数据库,这些资源均允许商业使用与再分发。构建过程涉及大规模的数据提取、规范化处理与模式统一,并对约800万个原始ClinVar变异及约250GB的gnomAD VCF数据进行深度处理与融合。通过严格的质量控制、去重操作以及训练集与测试集的明确划分,最终形成了适用于大规模分析与机器学习训练的生产级Parquet数据集,整个构建过程凝聚了超过250小时的专家工程与数据整理工作。
特点
该数据集在致病性单核苷酸变异(SNV)研究领域展现出显著特色。其核心构成包含约144k个致病变异与约105万个良性变异,总计约120万个样本,为模型训练提供了坚实的数量基础。数据集特别设计了包含55k个样本的独立测试集,并在此基础上进行了11种不同的消融测试,生成了总计约660k个测试样本,为模型性能的细致评估创造了条件。此外,数据集还提供了受控的消融数据集、用于鲁棒性评估的模拟变异数据集,以及适用于经典机器学习训练的平衡CSV子集,全面支持基因组学AI模型的开发与基准测试。
使用方法
该数据集专为支持应用基因组学与人工智能模型开发而设计。研究人员可利用其大规模ClinVar风格SNV训练数据集进行致病性预测模型的训练与优化。提供的独立测试集与多种消融测试数据集,能够用于系统评估模型在不同信号缺失情况下的性能与鲁棒性。数据集以Parquet和CSV两种格式提供,便于集成到大规模分析流程与机器学习训练框架中。对于希望进行商业应用、合作研究或基准测试的用户,需要通过指定联系方式获取数据使用许可,具体条款将根据个案进行评估。
背景与挑战
背景概述
Clinvar_SNV_GnomAD_Pathogen_Variants数据集是基因组学与人工智能交叉领域的重要资源,由研究人员Rohit Yadav及其团队构建,旨在支持PathoPreter模型的训练与评估。该数据集整合了ClinVar和gnomAD等公开基因组数据库,专注于单核苷酸变异(SNV)的致病性分类研究。通过大规模提取、归一化和质量控制,数据集包含约144k致病性变异和1.05百万良性变异,总计约1.2百万样本,为基因组变异解释提供了结构化数据基础。其创建过程涉及约150小时计算时间和250小时专家工程工作,推动了精准医学中变异优先级排序和机器学习模型的发展。
当前挑战
该数据集旨在解决基因组学中单核苷酸变异致病性分类的挑战,包括从海量、异构的原始数据中准确区分致病与良性变异,以及应对临床注释不一致和样本不平衡问题。构建过程中的挑战涉及大规模数据处理,如从约8百万原始ClinVar变异和250 GB gnomAD VCF数据中提取、合并并确保训练-测试集无重叠,同时进行模式统一和质量控制,以生成适用于机器学习的生产级数据集。此外,创建受控消融测试和假变异鲁棒性评估数据,以验证模型在噪声环境下的稳定性,进一步增加了数据工程的复杂性。
常用场景
经典使用场景
在基因组学与生物信息学领域,Clinvar_SNV_GnomAD_Pathogen_Variants数据集为单核苷酸变异(SNV)的致病性预测提供了关键资源。该数据集整合了ClinVar的致病性注释与gnomAD的人群频率数据,构建了大规模、高质量的变异-标签对,常用于训练和评估深度学习模型,如PathoPreter,以自动化识别致病性SNV。其经典应用场景在于为研究人员提供一个标准化的基准,用于开发和比较不同机器学习算法在变异分类任务上的性能,从而推动精准医疗中基因组解读的自动化进程。
衍生相关工作
围绕该数据集,已衍生出一系列重要的研究工作。最典型的代表是PathoPreter模型,这是一个专门针对SNV致病性解读的大规模预训练模型。此外,基于其构建的消融测试数据集催生了关于不同基因组特征(如人群频率、保守性评分)对预测性能影响的信号移除研究。这些工作不仅验证了数据集的效用,还进一步拓展了可解释性人工智能在基因组学中的应用,为后续开发更高效、更透明的变异解读工具奠定了方法论基础。
数据集最近研究
最新研究方向
在基因组学与生物信息学领域,Clinvar_SNV_GnomAD_Pathogen_Variants数据集作为PathoPreter模型的核心训练资源,正推动着单核苷酸变异致病性预测的前沿探索。当前研究聚焦于利用大规模临床变异数据与群体基因组学信息,通过深度学习方法构建可解释的AI模型,以提升致病性注释的准确性与鲁棒性。热点方向包括开发针对虚假变异的稳健性评估框架,以及通过信号消融实验解析不同特征对模型决策的贡献,这有助于揭示基因组数据中的潜在偏差并增强临床应用的可靠性。该数据集的精心构建与高质量标注为精准医疗和遗传诊断提供了关键基础设施,其衍生模型在加速罕见病研究和变异优先排序流程中展现出深远影响。
以上内容由遇见数据集搜集并总结生成


