surindersinghssj/sgpc-amritsar-kirtan-live
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/surindersinghssj/sgpc-amritsar-kirtan-live
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- pa
license: cc-by-4.0
task_categories:
- automatic-speech-recognition
tags:
- gurbani
- kirtan
- sikh
- punjabi
- gurmukhi
- speech
- music
- golden-temple
- sgpc
- live-kirtan
size_categories:
- 100K<n<1M
---
# SGPC Amritsar Live Kirtan Dataset
Live Gurbani Kirtan audio dataset from Sachkhand Sri Harmandir Sahib (Golden Temple, Amritsar),
sourced from SGPC's official YouTube channel. Each row contains a ≤30-second audio segment
paired with Punjabi (Gurmukhi) caption text.
## Dataset Description
- **Source**: [SGPC Sri Amritsar YouTube](https://www.youtube.com/@SGPCSriAmritsar)
- **Text**: YouTube auto-generated Punjabi captions
- **Audio**: FLAC, 16kHz, mono
- **Segments**: ≤30 seconds each, instrumental ([ਸੰਗੀਤ]) portions excluded
## Statistics
| Metric | Value |
|--------|-------|
| Total segments | 625,792 |
| Total audio | 804.1 hours |
| Videos | 241 |
| Avg segment duration | 4.6s |
| Audio format | FLAC, 16kHz, mono |
| Language | Punjabi (Gurmukhi) |
## Splits
| Split | Segments |
|-------|----------|
| train | 586,859 |
| validation | 22,667 |
| test | 16,266 |
Splits are by **video ID** (not segment) to prevent data leakage.
## Data Fields
| Field | Type | Description |
|-------|------|-------------|
| `audio` | Audio | FLAC audio segment (16kHz mono) |
| `gurmukhi_text` | string | Punjabi caption text (Gurmukhi script) |
| `start_time` | float | Start time in source video (seconds) |
| `end_time` | float | End time in source video (seconds) |
| `duration` | float | Segment duration (seconds) |
| `video_id` | string | YouTube video ID |
| `video_title` | string | Video title |
| `channel` | string | Source channel name |
## Usage
```python
from datasets import load_dataset
ds = load_dataset("surindersinghssj/sgpc-amritsar-kirtan-live")
# Listen to a sample
sample = ds["train"][0]
print(sample["gurmukhi_text"])
# Audio is directly playable in the HF dataset viewer
```
## Pipeline
1. Download audio-only from YouTube using yt-dlp
2. Download Punjabi auto-generated captions (VTT format)
3. Parse captions, filter out [ਸੰਗੀਤ] (music) segments
4. Keep only Gurmukhi text (>50% Gurmukhi characters)
5. Group consecutive captions into ≤30s chunks
6. Extract audio segments as FLAC 16kHz mono
## License
CC-BY-4.0
## Citation
```bibtex
@dataset{sgpc_kirtan_live,
title={SGPC Amritsar Live Kirtan Dataset},
author={Surinder Singh},
year={2026},
url={https://huggingface.co/datasets/surindersinghssj/sgpc-amritsar-kirtan-live}
}
```
---
语言:
- 旁遮普语(pa)
许可协议:知识共享署名4.0协议(CC-BY-4.0)
任务类别:
- 自动语音识别(Automatic Speech Recognition)
标签:
- 古尔巴尼(Gurbani)
- 基尔坦(Kirtan)
- 锡克教(Sikh)
- 旁遮普语(Punjabi)
- 果鲁穆奇文(Gurmukhi)
- 语音
- 音乐
- 金庙(Golden Temple)
- SGPC(Sri Gurudwara Prabandhak Committee)
- 现场基尔坦(Live-Kirtan)
样本规模:
- 10万<样本数量<100万
---
# SGPC阿姆利则现场基尔坦数据集
本数据集采集自阿姆利则 Sachkhand Sri Harmandir Sahib(金庙,阿姆利则)的现场古尔巴尼基尔坦音频,数据来源为SGPC官方YouTube频道。每条数据对应一段时长不超过30秒的音频片段,并搭配旁遮普语(果鲁穆奇文)字幕文本。
## 数据集详情
- **数据来源**:[SGPC斯里阿姆利则YouTube频道](https://www.youtube.com/@SGPCSriAmritsar)
- **文本数据**:YouTube自动生成的旁遮普语字幕
- **音频格式**:无损音频编码格式FLAC(Free Lossless Audio Codec)、16kHz采样率、单声道
- **音频片段**:单段时长≤30秒,已过滤器乐([ਸੰਗੀਤ])片段
## 统计信息
| 指标 | 数值 |
|--------|-------|
| 总片段数 | 625,792 |
| 总音频时长 | 804.1小时 |
| 源视频数 | 241 |
| 平均片段时长 | 4.6秒 |
| 音频格式 | FLAC、16kHz采样率、单声道 |
| 语言 | 旁遮普语(果鲁穆奇文) |
## 数据集划分
| 划分集 | 片段数 |
|-------|----------|
| 训练集 | 586,859 |
| 验证集 | 22,667 |
| 测试集 | 16,266 |
数据集划分依据**视频ID**(而非单个片段),以避免数据泄露。
## 数据字段说明
| 字段名 | 数据类型 | 字段说明 |
|-------|------|-------------|
| `audio` | 音频 | FLAC格式音频片段(16kHz采样率、单声道) |
| `gurmukhi_text` | 字符串 | 旁遮普语字幕文本(果鲁穆奇文书写) |
| `start_time` | 浮点数 | 源视频中的片段起始时间(单位:秒) |
| `end_time` | 浮点数 | 源视频中的片段结束时间(单位:秒) |
| `duration` | 浮点数 | 片段时长(单位:秒) |
| `video_id` | 字符串 | YouTube视频ID |
| `video_title` | 字符串 | 视频标题 |
| `channel` | 字符串 | 来源频道名称 |
## 快速使用示例
python
from datasets import load_dataset
ds = load_dataset("surindersinghssj/sgpc-amritsar-kirtan-live")
# 试听示例样本
sample = ds["train"][0]
print(sample["gurmukhi_text"])
# 音频可直接在Hugging Face数据集查看器中播放
## 数据处理流程
1. 使用yt-dlp工具从YouTube下载纯音频文件
2. 下载旁遮普语自动生成字幕(WebVTT格式,简称VTT)
3. 解析字幕文本,过滤掉包含[ਸੰਗੀਤ](器乐)的片段
4. 仅保留果鲁穆奇文字符占比超过50%的文本
5. 将连续的字幕合并为时长不超过30秒的片段块
6. 提取音频片段并转换为FLAC格式(16kHz采样率、单声道)
## 许可协议
知识共享署名4.0协议(CC-BY-4.0)
## 引用格式
bibtex
@dataset{sgpc_kirtan_live,
title={SGPC阿姆利则现场基尔坦数据集},
author={Surinder Singh},
year={2026},
url={https://huggingface.co/datasets/surindersinghssj/sgpc-amritsar-kirtan-live}
}
提供机构:
surindersinghssj
搜集汇总
数据集介绍
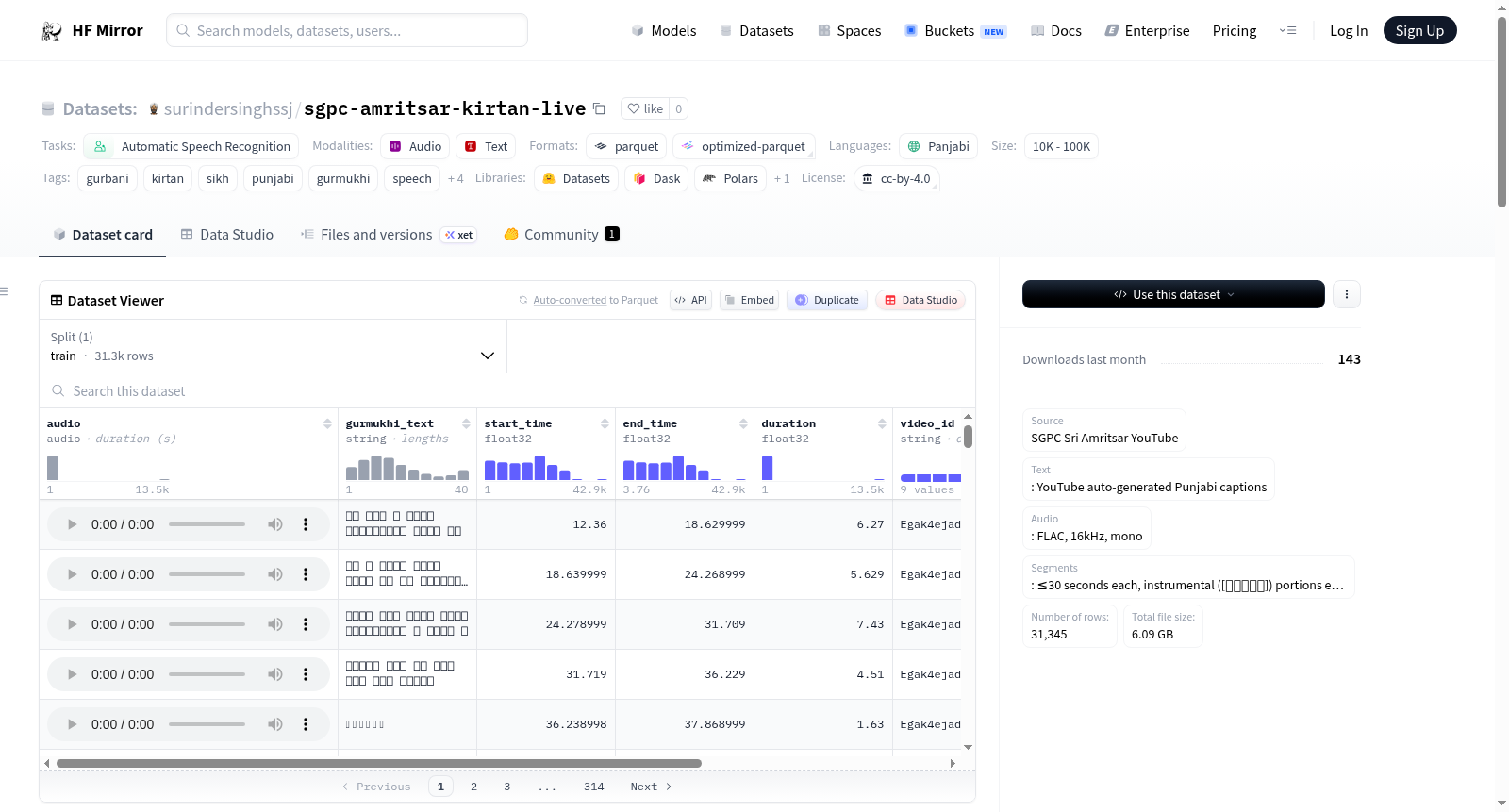
构建方式
在语音识别与宗教音乐研究的交叉领域,SGPC Amritsar Live Kirtan数据集的构建体现了对传统锡克教圣乐的系统性数字化采集。该数据集源自锡克教圣地哈曼迪尔寺(金庙)的官方YouTube频道直播内容,通过自动化流程精心构建:首先利用yt-dlp工具下载纯音频流,同步获取平台自动生成的旁遮普语字幕文件;随后对字幕进行解析与清洗,专门过滤掉标注为[ਸੰਗੀਤ]的纯器乐片段,并保留古木基文字符占比超过50%的文本内容;最终将连续的字幕按时间顺序组合成不超过30秒的音频片段,并以16kHz单声道FLAC格式提取存储,确保语音与文本的精确对齐。
特点
该数据集在宗教语音语料库中展现出独特的多模态特性,其核心在于将现场宗教吟唱与精确的文本转录相结合。数据集包含超过14万条音频片段,总时长约188小时,全部采用16kHz采样率的单声道FLAC格式,保证了音频质量的统一性。每条数据不仅包含音频波形,还配有古木基文脚本的旁遮普语字幕,并附有详细的时序元数据,如起始时间、持续时长及来源视频标识。特别值得注意的是,数据集通过按视频ID划分训练集与测试集,有效避免了数据泄露风险,且所有内容均源自权威宗教机构的官方直播,具有较高的文化真实性与技术一致性。
使用方法
在语音技术研究与文化计算应用中,该数据集为旁遮普语自动语音识别模型的训练与评估提供了珍贵资源。研究者可通过Hugging Face数据集库直接加载,使用标准接口访问音频片段及其对应的文本标注。数据集的标准化格式支持端到端的语音识别流程开发,用户可提取音频特征与文本标签进行模型训练,同时利用附带的时序信息进行细粒度的语音分析。此外,数据集完全兼容主流深度学习框架,支持在文化传承、多语言语音技术等跨学科领域开展实验,为探索宗教音乐的语言特征与语音识别技术在低资源语言中的应用开辟了新的路径。
背景与挑战
背景概述
在自动语音识别领域,针对低资源语言的研究一直是推动技术普惠的关键方向。SGPC Amritsar Live Kirtan 数据集由研究者 Surinder Singh 于2026年创建,其核心目标在于解决旁遮普语(古木基文)在宗教音乐场景下的语音识别难题。该数据集源自锡克教圣地金庙的官方YouTube频道,收录了超过188小时的现场吉尔坦吟唱音频,并配以自动生成的旁遮普语字幕。通过聚焦于这一特定文化语境,该数据集不仅丰富了低资源语言的语音语料库,也为宗教文化遗产的数字化保存与传播提供了重要的数据基础,对跨语言语音技术及计算音乐学领域具有显著的补充价值。
当前挑战
该数据集旨在应对宗教音乐场景下旁遮普语自动语音识别的独特挑战,包括吟唱旋律对语音清晰度的干扰、宗教术语的准确转录,以及现场录音中背景噪声的处理。在构建过程中,研究者需克服数据获取与处理的复杂性:从YouTube提取音频与字幕时需保持时序对齐;过滤纯音乐片段(如标注为[ਸੰਗੀਤ]的部分)以保留有效语音;确保字幕文本中古木基文字符的比例超过50%,以维持语言纯度;同时,为避免数据泄露,需按视频ID而非片段进行数据集划分,这增加了数据分割策略的设计难度。
常用场景
经典使用场景
在旁遮普语语音识别研究领域,SGPC Amritsar Live Kirtan数据集为学者提供了珍贵的实时宗教音乐录音资源。该数据集收录了来自斯里哈曼迪尔萨希卜(金庙)的现场吉尔坦诵唱音频,每条数据均包含不超过30秒的音频片段及其对应的古木基文文本。这种音频与文本的精确对齐结构,使其成为训练和评估旁遮普语自动语音识别模型的理想素材,尤其适用于处理带有音乐背景和特定宗教韵律的语音信号。
衍生相关工作
围绕该数据集,已催生了一系列聚焦于低资源语言和领域特定语音处理的前沿工作。典型研究包括针对旁遮普语ASR模型的微调与优化,探索在音乐伴奏下提升语音识别鲁棒性的算法,以及利用该数据对跨语言预训练模型进行适应性训练。这些衍生工作不仅深化了对特定语言现象的理解,也为其他非主流语言或领域专用语音技术的开发树立了可借鉴的范式。
数据集最近研究
最新研究方向
在语音技术与文化遗产数字化交叉领域,SGPC Amritsar Live Kirtan数据集为旁遮普语自动语音识别研究提供了珍贵资源。该数据集源自锡克教圣地金庙的现场吉尔坦吟唱,其前沿研究聚焦于低资源语言模型优化,特别是在音乐性语音与宗教文本对齐的跨模态建模方面。近期热点事件如印度政府推动的“数字印度”倡议,加速了对地方语言音频资料的智能处理需求,使得该数据集在保护非物质文化遗产、开发多语言语音助手以及促进宗教文献的可访问性方面具有深远影响。
以上内容由遇见数据集搜集并总结生成


