mergekit-configs
收藏Hugging Face2024-11-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/louisbrulenaudet/mergekit-configs
下载链接
链接失效反馈官方服务:
资源简介:
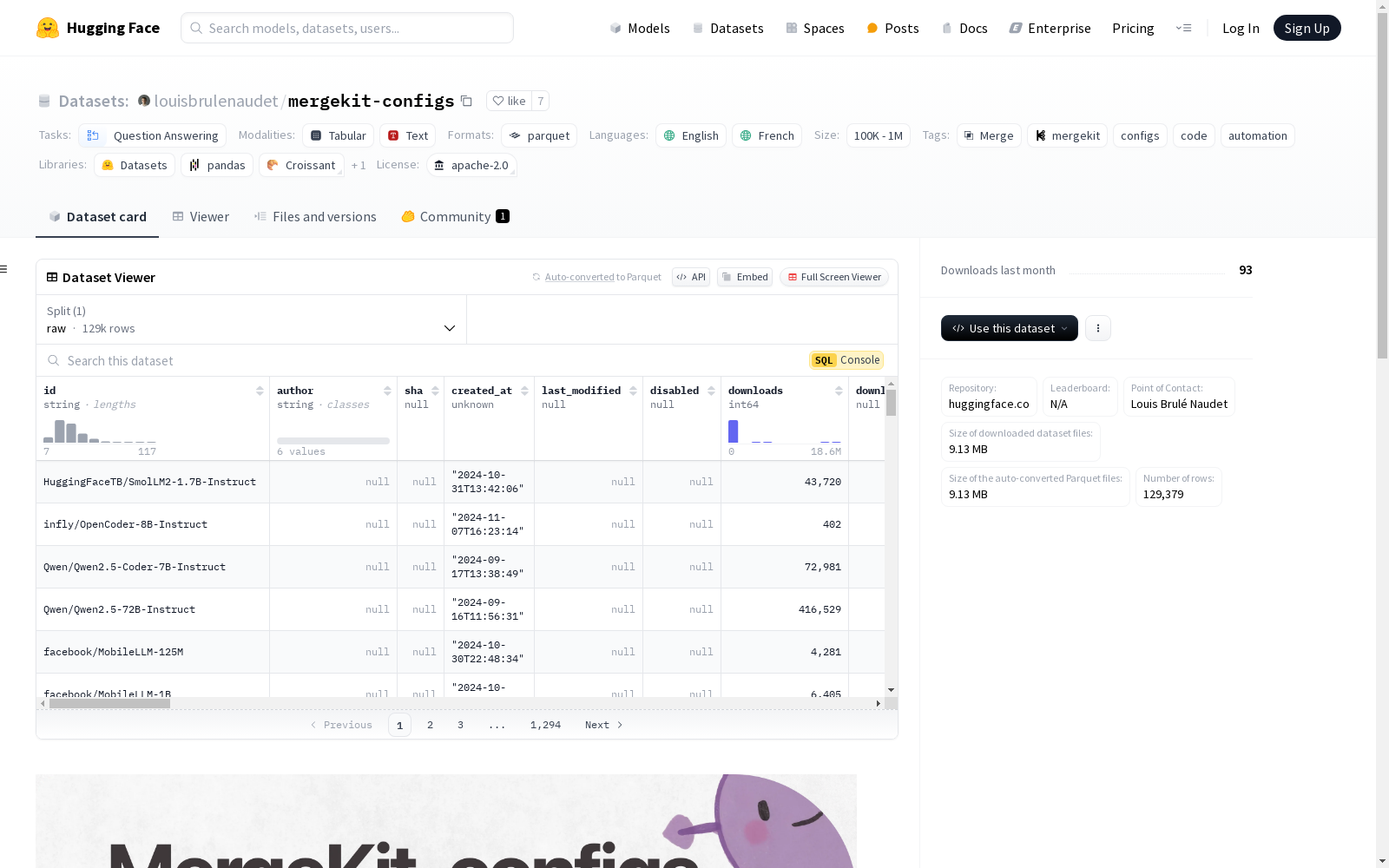
该数据集名为'mergekit-configs',主要用于帮助用户搜索与MergeKit兼容的模型架构,从而自动化模型合并过程。数据集包含了Hub的配置状态快照,消除了手动打开配置文件的需求。数据集的特征包括模型ID、作者、创建时间、下载次数、模型类型、隐藏层大小等详细信息。数据集支持英语和法语,适用于问题回答任务。
This dataset is named 'mergekit-configs'. It is primarily developed to help users search for model architectures compatible with MergeKit, thereby automating the model merging process. The dataset contains configuration state snapshots from the Hub, eliminating the requirement to manually open configuration files. It features detailed attributes including model ID, author, creation time, download count, model type, hidden layer size, and other relevant details. This dataset supports both English and French, and is suitable for question answering tasks.
创建时间:
2024-11-12
原始信息汇总
数据集概述
数据集信息
- 名称: mergekit-configs
- 描述: 该数据集用于搜索与MergeKit兼容的架构,简化高性能合并搜索的自动化过程。它提供了Hub配置状态的快照,无需手动打开配置文件。
- 许可证: Apache 2.0
- 任务类别: 问答
- 语言: 英语、法语
- 标签: merge, mergekit, configs, code, automation
- 大小类别: 100K<n<1M
数据集特征
- id: 字符串
- author: 字符串
- sha: null
- created_at: 时间戳(微秒,UTC时区)
- last_modified: null
- disabled: null
- downloads: 64位整数
- downloads_all_time: null
- gated: 布尔值
- gguf: null
- inference: null
- likes: 64位整数
- library_name: 字符串
- tags: 字符串序列
- pipeline_tag: 字符串
- mask_token: null
- model_index: null
- trending_score: 64位整数
- architectures: 字符串序列
- bos_token_id: 64位整数
- eos_token_id: 64位整数
- hidden_act: 字符串
- hidden_size: 64位整数
- initializer_range: 64位浮点数
- intermediate_size: 64位整数
- max_position_embeddings: 64位整数
- model_type: 字符串
- num_attention_heads: 64位整数
- num_hidden_layers: 64位整数
- num_key_value_heads: 64位整数
- rms_norm_eps: 64位浮点数
- rope_theta: 64位浮点数
- sliding_window: 64位整数
- tie_word_embeddings: 布尔值
- torch_dtype: 字符串
- transformers_version: 字符串
- use_cache: 布尔值
- vocab_size: 64位整数
- attention_bias: 布尔值
- attention_dropout: 64位浮点数
- head_dim: 64位整数
- mlp_bias: 布尔值
- pretraining_tp: 64位整数
- rope_scaling: 结构体
- factor: 64位浮点数
- original_max_position_embeddings: 64位浮点数
数据集分割
- raw:
- num_bytes: 70119636
- num_examples: 129379
数据集大小
- 下载大小: 9132674
- 数据集大小: 70119636
配置
- config_name: default
- data_files:
- split: raw
- path: data/raw-*
- data_files:
引用
BibTeX @misc{HFforLegal2024, author = {Louis Brulé Naudet}, title = {MergeKit-configs: access all Hub architectures and automate your model merging process}, year = {2024} howpublished = {url{https://huggingface.co/datasets/louisbrulenaudet/mergekit-configs}}, }
搜集汇总
数据集介绍
构建方式
mergekit-configs数据集的构建基于Hugging Face Hub中模型配置的全面抓取与整合。通过自动化脚本,数据集从Hub中提取了包括模型架构、隐藏层大小、模型类型等在内的关键配置信息,并将其结构化存储为Parquet格式。这一过程不仅确保了数据的完整性与一致性,还显著提升了数据访问的效率,为模型合并的自动化流程提供了坚实的基础。
特点
该数据集的核心特点在于其全面性与易用性。它涵盖了Hugging Face Hub中大量模型的配置信息,包括但不限于模型架构、隐藏层大小、中间层大小等关键参数。数据集以Parquet格式存储,支持高效的数据读取与处理。此外,数据集还提供了丰富的元数据,如模型下载次数、点赞数等,为研究人员提供了多维度的分析视角。
使用方法
使用mergekit-configs数据集时,用户首先需要通过Hugging Face CLI进行登录,随后使用Polars库读取Parquet文件。数据集支持基于模型架构、隐藏层大小等关键参数的分组与聚合操作,便于用户快速筛选出符合需求的模型配置。通过这一流程,用户可以高效地自动化模型合并过程,提升模型开发的效率与效果。
背景与挑战
背景概述
在深度学习模型的开发与优化过程中,模型合并(Model Merging)作为一种提升模型性能的技术手段,逐渐受到研究者的关注。mergekit-configs数据集由Louis Brulé Naudet于2024年创建,旨在为模型合并提供兼容架构的自动化搜索支持。该数据集通过整合Hugging Face Hub中的配置信息,简化了高性能模型合并的流程,避免了手动查阅配置文件的繁琐操作。其核心研究问题在于如何高效地识别和匹配不同模型的架构参数,从而加速模型合并的自动化进程。该数据集的发布为深度学习领域的模型优化提供了新的工具,推动了模型合并技术的进一步发展。
当前挑战
mergekit-configs数据集在解决模型合并的自动化问题时,面临多重挑战。首先,模型合并本身需要高度兼容的架构参数,而不同模型之间的参数差异可能导致合并失败或性能下降,如何精准匹配这些参数成为关键难题。其次,数据集的构建过程中,需要从Hugging Face Hub中提取大量配置信息,并确保数据的完整性与一致性,这对数据处理和存储提出了较高要求。此外,随着模型架构的不断更新,数据集需要持续维护和扩展,以保持其时效性和实用性。这些挑战不仅考验了数据集的构建技术,也对模型合并的自动化研究提出了更高的标准。
常用场景
经典使用场景
在自然语言处理领域,mergekit-configs数据集被广泛应用于模型合并的自动化过程中。通过提供Hub架构的配置快照,研究人员可以快速查找兼容的模型架构,从而高效地进行模型合并。这一数据集的使用显著简化了模型合并的流程,使得研究人员能够专注于模型性能的优化,而非繁琐的配置工作。
解决学术问题
mergekit-configs数据集解决了模型合并过程中架构兼容性验证的难题。传统方法需要手动打开和检查配置文件,耗时且容易出错。该数据集通过自动化配置文件的提取和整理,为研究人员提供了一个统一的接口,极大地提高了模型合并的效率和准确性。这一创新为自然语言处理领域的模型优化提供了强有力的支持。
衍生相关工作
基于mergekit-configs数据集,许多经典工作得以衍生。例如,研究人员开发了自动化模型合并工具MergeKit,该工具利用数据集中的配置信息,实现了模型合并的自动化流程。此外,该数据集还推动了多语言模型的研究,通过合并不同语言的模型,研究人员开发了能够处理多种语言的高性能模型,进一步拓展了自然语言处理的应用范围。
以上内容由遇见数据集搜集并总结生成


