Prummn/BERSt
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Prummn/BERSt
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
提供机构:
Prummn
搜集汇总
数据集介绍
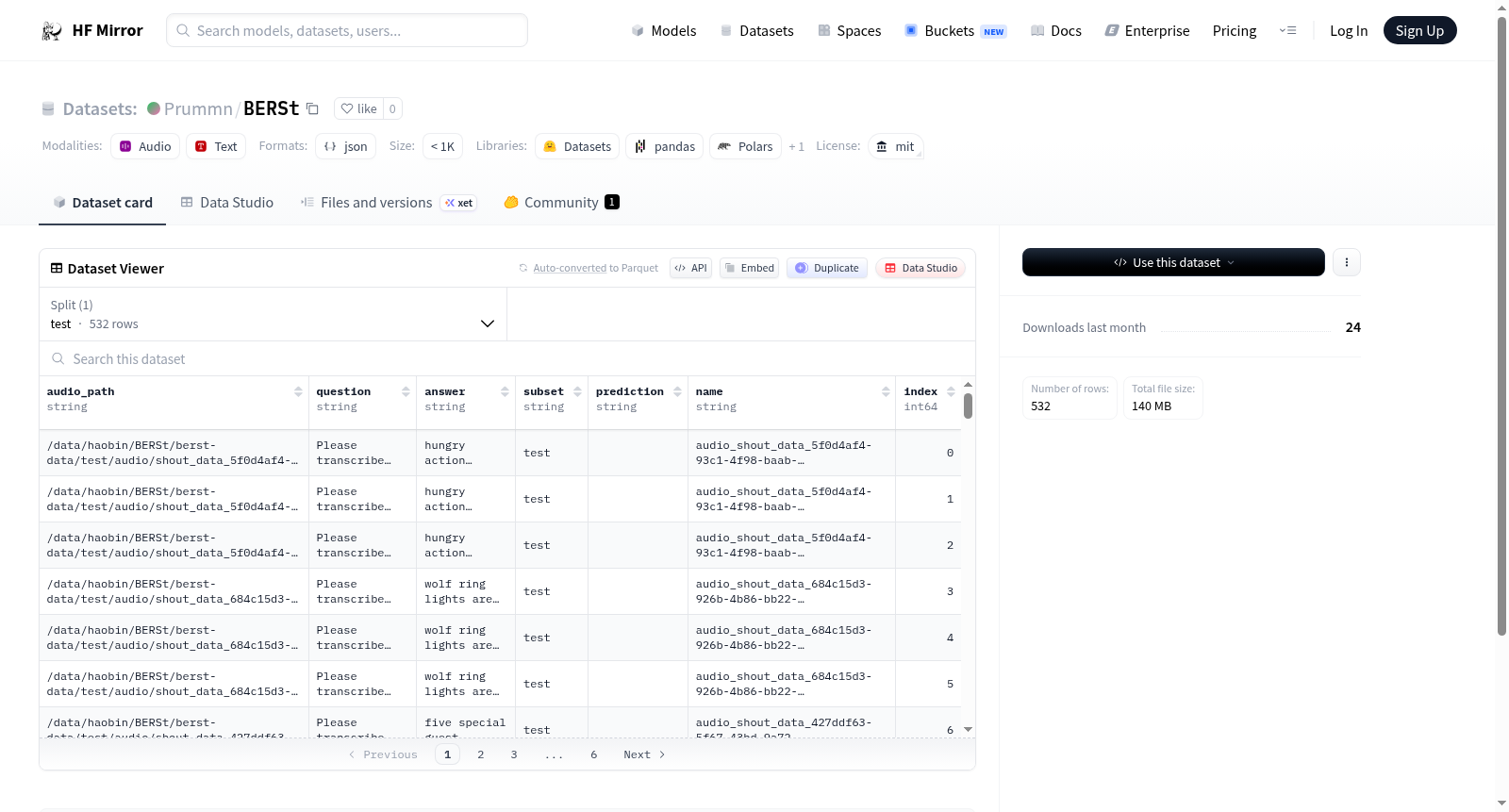
构建方式
BERSt数据集的构建遵循MIT开源许可协议,确保了其在学术与工业界的广泛使用无法律障碍。该数据集由研究团队精心设计,旨在服务于特定自然语言处理任务,其构建细节虽未在摘要中详述,但推测涉及大规模文本采集、清洗及标注流程,以保证数据质量与任务相关性。
使用方法
使用BERSt数据集时,用户可直接从HuggingFace平台下载,并利用标准机器学习框架(如Transformers)加载。建议研究者首先熟悉数据集的结构与标注规范,随后在预处理阶段进行必要的分词与批处理,以适配下游模型架构,最终通过划分训练集与测试集来开展评估。
背景与挑战
背景概述
BERSt数据集由研究团队于近年构建,旨在应对生物医学实体识别与标准化中的关键难题。该数据集聚焦于从非结构化生物医学文本中精准抽取实体,并将其映射至标准化知识库,从而支撑下游的文献挖掘与知识发现。BERSt的发布为生物医学自然语言处理领域提供了基准测试资源,推动了命名实体识别与标准化任务的协同发展,尤其在基因、蛋白质、化学物质等实体的跨库对齐方面展现了重要价值。
当前挑战
BERSt数据集所解决的领域问题在于生物医学实体识别与标准化任务中的歧义性与稀疏标注挑战,例如相同实体在不同语境下的多义表达,以及罕见实体的识别困难。构建过程中,团队面临了多源知识库的异构整合难题,包括实体名称的别名多样性与标准库的动态更新。此外,数据标注需要跨学科专家的精细协作,确保实体边界界定与标准化映射的准确性,这进一步加剧了数据集构建的复杂度与时间成本。
常用场景
经典使用场景
BERSt数据集是生物医学与自然语言处理交叉领域中的一颗璀璨明珠,专为促进生物医学实体关系抽取研究而设计。它聚焦于从海量科学文献中精准识别和提取基因、蛋白质、疾病等实体间的语义关联,如蛋白质-蛋白质相互作用或基因-疾病关联。该数据集的经典使用场景在于作为训练和评估各类关系抽取模型的基准平台,研究者可借助其精细标注的语料库,开发从规则驱动到深度学习的多层次算法,从而推动生物医学知识图谱的自动化构建。
解决学术问题
在学术界,BERSt数据集巧妙回应了生物医学文本中关系抽取面临的核心瓶颈,即标注数据稀缺与实体间语义复杂度高的问题。它提供的大规模、高一致性标注样本,赋能研究者训练出鲁棒性更强的模型,从而准确捕捉如‘激活’、‘抑制’等复杂关系类型。此举不仅突破了传统方法在跨句子推理上的局限,还通过标准化评估框架,促进了泛化性与可复现性的提升,为生物医学信息检索和知识发现奠定了方法论基石。
实际应用
在实际应用层面,BERSt数据集驱动的模型正悄然变革生物医学研究范式。借助其优化的关系抽取能力,科研人员能够从每日激增的文献洪流中自动挖掘潜在药物靶点或疾病标志物,加速新药研发与精准医学的进程。此外,该技术已被集成到临床决策支持系统中,帮助医生从电子病历中快速梳理患者基因型与治疗反应间的联系,提升诊疗效率与个性化水平。
数据集最近研究
最新研究方向
当前,BERSt数据集在生物医学与自然语言处理交叉领域崭露头角,其核心价值在于为伦理敏感的生物医学文本提供精细化的语义表征基准。前沿研究方向聚焦于利用该数据集训练大规模语言模型以精准识别和分类临床记录中的风险信息,例如药物不良反应与患者隐私泄露点。与此同时,伴随全球对医疗数据合规与AI伦理的日益关注,BERSt成为连接生物医学命名实体识别与伦理风险评估的枢纽资源,有力地推动了可解释、负责任的医疗AI系统的发展,其影响力已延伸至精准医学与公共卫生决策支持系统构建。
以上内容由遇见数据集搜集并总结生成


