MultiVerse
收藏Hugging Face2025-10-26 更新2025-10-27 收录
下载链接:
https://huggingface.co/datasets/passing2961/MultiVerse
下载链接
链接失效反馈官方服务:
资源简介:
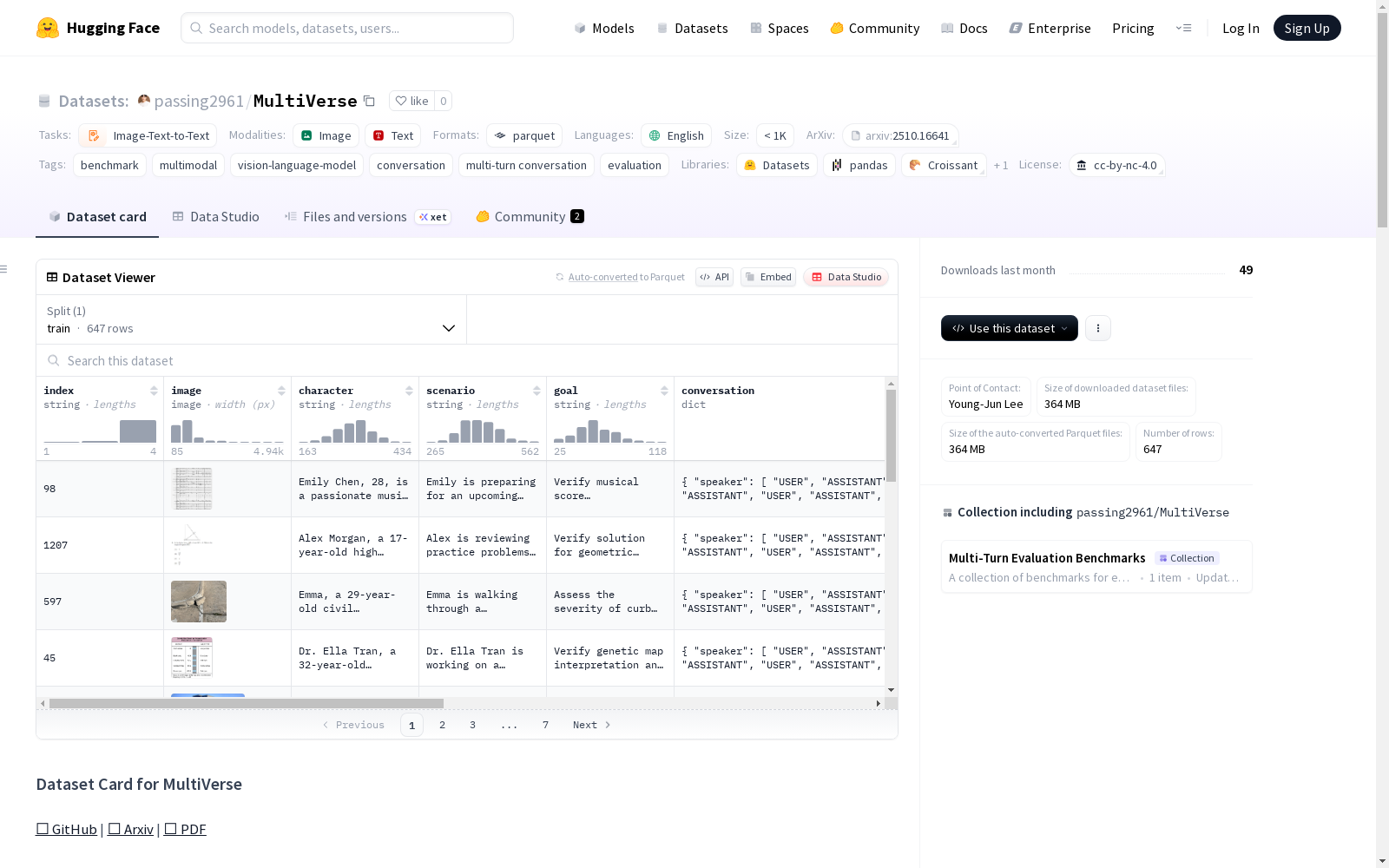
MultiVerse是一个新颖的多轮对话基准,包含647个对话,每个对话平均四轮,从12个流行的VLM评估基准中衍生而来。该数据集包括484个不同的任务和484个交互目标,覆盖了从事实知识、感知到高级推理任务如数学和编程的广泛话题。
MultiVerse is a novel multi-turn dialogue benchmark. It comprises 647 dialogues with an average of four turns per dialogue, derived from 12 popular VLM evaluation benchmarks. This dataset includes 484 distinct tasks and 484 interaction goals, covering a broad spectrum of topics ranging from factual knowledge and perception to advanced reasoning tasks such as mathematics and programming.
创建时间:
2025-10-19
原始信息汇总
MultiVerse数据集概述
基本信息
- 数据集名称: MultiVerse
- 语言: 英语
- 许可证: CC-BY-NC-4.0
- 类型: 多轮对话基准测试数据集
- 标签: 基准测试、多模态、视觉语言模型、对话、多轮对话、评估
数据集规模
- 对话数量: 647个对话
- 平均轮次: 每个对话平均4轮
- 训练集大小: 370 MB
- 下载大小: 364 MB
- 示例数量: 647个
数据来源
- 源自12个流行的视觉语言模型评估基准
- 涵盖484个不同任务和484个交互目标
- 主题范围广泛:从事实知识、感知到数学和编程等高级推理任务
数据结构
主要字段
index: 唯一标识符,格式为idx:source_dataset_name:original_indeximage: 对话相关的源图像character: 对话中主要角色的身份或角色scenario: 对话的叙事或情境背景goal: 目标目的或对话意图conversation: 多轮对话交换序列
对话结构
speaker: 说话者名称或角色utterance: 该轮次的发言文本checklist: 每轮评估检查表question: 评估问题main_criteria: 主要评估维度sub_criteria: 次要评估子维度
分类字段
main_goal_category: 高级目标分类sub_goal_category: 细粒度目标分类main_task_category: 高级任务分类sub_task_category: 细粒度任务分类image_main_category: 高级图像领域分类image_sub_category: 细粒度图像领域分类
数据集创建方法
- 从12个广泛使用的视觉语言模型评估基准收集源图像
- 采用个人背景到对话的方法确保词汇多样性和上下文丰富的多轮对话
- 所有样本经过细致的人工审查,确保:
- 自然对话流程
- 事实准确性
- 盲测鲁棒性
相关资源
- GitHub仓库: https://github.com/passing2961/MultiVerse
- 论文: https://arxiv.org/abs/2510.16641
- 联系方式: passing2961@gmail.com
引用信息
bibtex @misc{lee2025multiversemultiturnconversationbenchmark, title={MultiVerse: A Multi-Turn Conversation Benchmark for Evaluating Large Vision and Language Models}, author={Young-Jun Lee and Byung-Kwan Lee and Jianshu Zhang and Yechan Hwang and Byungsoo Ko and Han-Gyu Kim and Dongyu Yao and Xuankun Rong and Eojin Joo and Seung-Ho Han and Bowon Ko and Ho-Jin Choi}, year={2025}, eprint={2510.16641}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2510.16641}, }
搜集汇总
数据集介绍
构建方式
在视觉语言模型评估领域,MultiVerse数据集通过系统化整合12个主流评测基准构建而成。其构建流程始于从MegaBench、CharXiv等跨领域数据源中筛选高质量种子图像,随后采用角色背景驱动的对话生成策略,确保多轮对话在词汇多样性和上下文连贯性达到平衡。所有样本均经过人工严格审核,剔除不符合自然对话流、存在事实错误或视觉信息不可达的案例,最终形成包含647组对话的精密语料库。
使用方法
研究者可借助该数据集对视觉语言模型进行系统性能力评估。使用时应首先加载图像与对话序列,通过分析模型在多轮交互中的响应质量,对照预设的评估清单进行量化评分。建议重点关注模型在角色一致性、目标完成度和逻辑连贯性等维度的表现,同时利用分层分类标签进行细粒度能力诊断。该数据集支持端到端评估流程,为改进模型的多模态对话能力提供实证依据。
背景与挑战
背景概述
多模态人工智能研究领域近年来呈现出蓬勃发展的态势,其中视觉与语言模型的融合成为关键研究方向。MultiVerse数据集于2025年由Young-Jun Lee等学者联合构建,其核心目标在于解决多轮对话场景下视觉语言模型的综合评估难题。该数据集整合了来自12个主流视觉语言评估基准的对话样本,涵盖数学推理、代码生成等484种任务类型,通过角色背景与情境叙事的深度结合,为多模态对话系统的演进提供了重要实验基础。
当前挑战
在视觉语言模型评估领域,传统基准往往局限于单轮交互,难以捕捉连续对话中的上下文依赖与逻辑连贯性。MultiVerse构建过程中面临双重挑战:其一是确保多轮对话的自然流畅性,需通过人工审核消除语义断裂与事实错误;其二是维持视觉可访问性,要求对话内容与图像语义形成有效关联。这些挑战直接关系到模型在真实场景中的对话理解与生成能力。
常用场景
经典使用场景
在视觉与语言模型研究领域,MultiVerse数据集作为多轮对话评估基准,其经典应用场景聚焦于测试模型在复杂交互情境下的综合表现。该数据集通过整合12个主流视觉语言评估基准的对话样本,构建了涵盖事实知识、感知推理乃至数学计算等多元任务的对话流,为评估模型在多轮对话中保持上下文连贯性与逻辑一致性提供了标准化测试环境。
解决学术问题
该数据集有效解决了视觉语言模型研究中多轮对话评估体系缺失的核心问题。通过引入角色设定、场景叙事与目标导向的对话结构,它突破了传统单轮评测的局限,为衡量模型在长程依赖理解、动态意图追踪及跨模态推理等方面的能力提供了量化依据。其精细化的评估维度设计,显著推进了多模态对话系统在认知层次与交互深度的研究进程。
实际应用
在实际应用层面,MultiVerse为智能客服、教育辅助与沉浸式交互系统提供了关键验证工具。其涵盖的484种任务类型能够模拟真实场景中用户与系统的渐进式对话,例如通过医疗影像对话实现诊断辅助,或基于科学图示开展教学问答。这种高泛化性的评估框架,直接助力于提升产业级多模态系统的场景适应性与决策可靠性。
数据集最近研究
最新研究方向
随着多模态人工智能技术的飞速发展,视觉语言模型在复杂对话场景中的评估成为研究热点。MultiVerse数据集通过整合12个主流基准的647个多轮对话,为模型在跨领域推理、情境感知及交互连贯性等方面的能力提供了系统化评估框架。当前研究聚焦于探索模型在数学推导、代码生成等高级认知任务中的表现,同时关注对话流程的自然性与事实准确性之间的平衡。该数据集通过精细化标注体系推动了多模态对话系统向更深层次语义理解发展,为构建具备人类水平交互能力的通用人工智能奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


