NanoBEIR-ko
收藏Hugging Face2025-12-20 更新2025-12-21 收录
下载链接:
https://huggingface.co/datasets/sionic-ai/NanoBEIR-ko
下载链接
链接失效反馈官方服务:
资源简介:
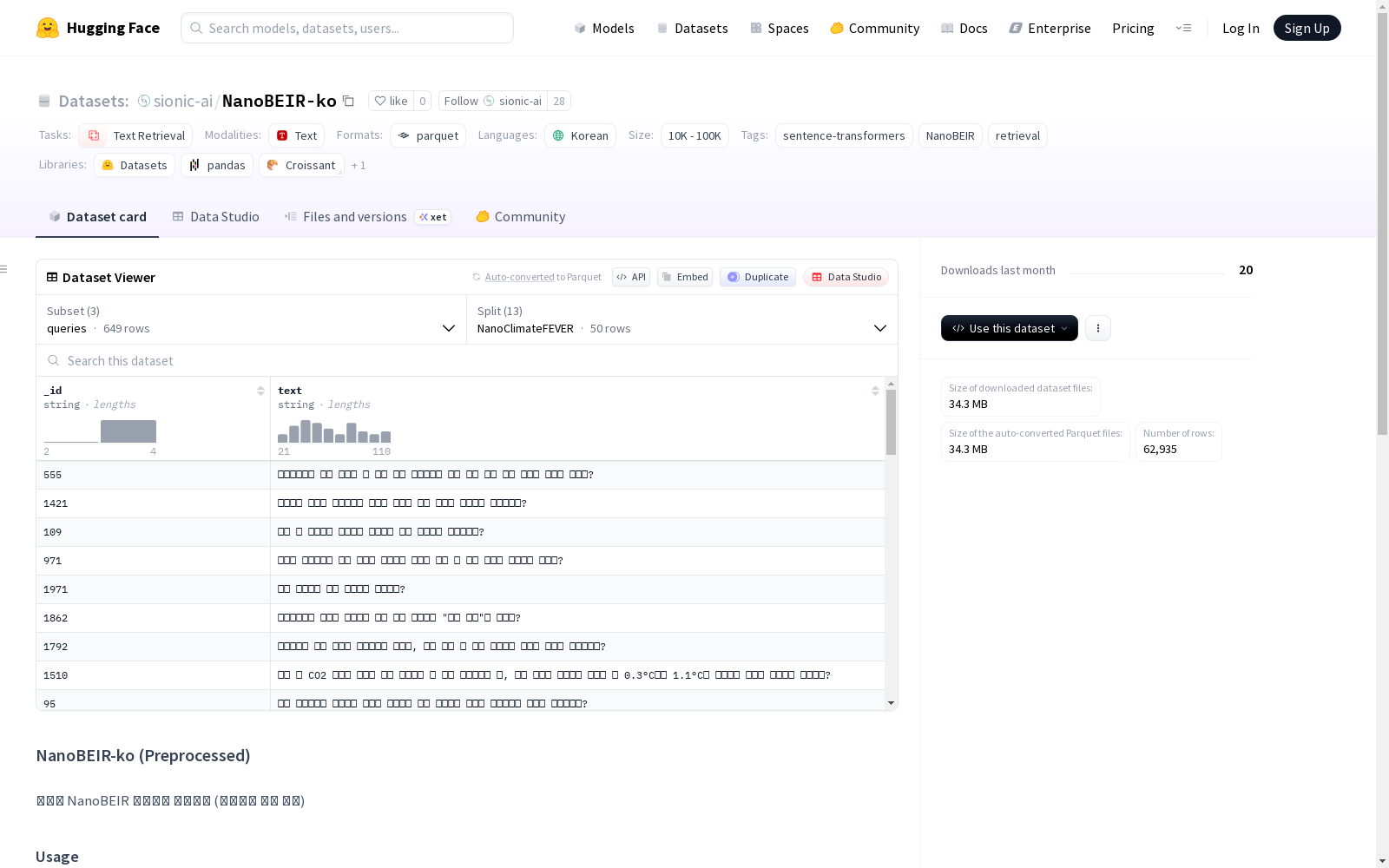
NanoBEIR-ko是一个韩语的NanoBEIR基准数据集,包含预处理过的查询。该数据集主要用于文本检索任务,包含三个主要配置:语料库(corpus)、查询相关文档(qrels)和查询(queries)。数据集包含多个子集,如NanoClimateFEVER、NanoDBPedia等,每个子集都有详细的字节数和示例数。预处理流程包括格式检测与转换(如将STATEMENT转换为QUESTION)以及质量验证与修复。
NanoBEIR-ko is a Korean-language NanoBEIR benchmark dataset containing preprocessed queries. It is primarily designed for text retrieval tasks and includes three core configurations: corpus, qrels, and queries. The dataset comprises multiple subsets such as NanoClimateFEVER and NanoDBPedia, with each subset featuring detailed byte counts and example counts. The preprocessing workflow covers format detection and conversion (e.g., converting STATEMENT to QUESTION) as well as quality validation and repair.
提供机构:
sionic-ai
创建时间:
2025-12-19
原始信息汇总
NanoBEIR-ko 数据集概述
数据集基本信息
- 数据集名称:NanoBEIR-ko (Preprocessed)
- 托管地址:https://huggingface.co/datasets/sionic-ai/NanoBEIR-ko
- 主要语言:韩语 (ko)
- 任务类别:文本检索 (text-retrieval)
- 相关标签:sentence-transformers, NanoBEIR, retrieval
数据集结构与配置
数据集包含三个独立的配置(config),每个配置下包含多个数据子集(split)。
1. 语料库配置 (corpus)
- 用途:存储检索文档/段落。
- 特征:
_id:字符串类型,文档标识符。text:字符串类型,文档文本内容。
- 子集与规模:
子集名称 示例数量 数据大小(字节) NanoClimateFEVER 3408 3,591,837 NanoDBPedia 6045 1,696,874 NanoFEVER 4996 4,468,102 NanoFiQA2018 4598 2,919,833 NanoHotpotQA 5090 1,454,406 NanoMSMARCO 5043 1,223,067 NanoNFCorpus 2953 2,617,249 NanoNQ 5035 2,012,592 NanoQuoraRetrieval 5046 273,698 NanoSCIDOCS 2210 1,355,295 NanoArguAna 3635 2,467,897 NanoSciFact 2919 2,559,907 NanoTouche2020 5745 7,492,610 - 总下载大小:34,133,367 字节
- 总数据集大小:34,133,367 字节
2. 查询配置 (queries)
- 用途:存储检索查询。
- 特征:
_id:字符串类型,查询标识符。text:字符串类型,查询文本内容。
- 子集与规模:
子集名称 示例数量 数据大小(字节) NanoClimateFEVER 50 7,977 NanoDBPedia 50 4,269 NanoFEVER 50 4,942 NanoFiQA2018 50 5,162 NanoHotpotQA 50 7,662 NanoMSMARCO 50 4,091 NanoNFCorpus 50 3,427 NanoNQ 50 4,833 NanoQuoraRetrieval 50 4,919 NanoSCIDOCS 50 7,526 NanoArguAna 50 41,933 NanoSciFact 50 6,480 NanoTouche2020 49 4,019 - 总下载大小:107,240 字节
- 总数据集大小:107,240 字节
3. 相关性判断配置 (qrels)
- 用途:存储查询与相关文档的对应关系。
- 特征:
query-id:字符串类型,查询ID。corpus-id:字符串类型,相关文档ID。
- 子集与规模:
子集名称 示例数量 数据大小(字节) NanoClimateFEVER 148 4,217 NanoDBPedia 1158 22,607 NanoFEVER 57 3,188 NanoFiQA2018 123 3,118 NanoHotpotQA 100 3,861 NanoMSMARCO 50 2,571 NanoNFCorpus 2518 13,680 NanoNQ 57 2,493 NanoQuoraRetrieval 70 2,749 NanoSCIDOCS 244 14,384 NanoArguAna 50 3,816 NanoSciFact 56 2,562 NanoTouche2020 932 18,062 - 总下载大小:97,308 字节
- 总数据集大小:97,308 字节
数据预处理流程
数据集经过了特定的预处理流程,旨在优化查询格式以用于检索任务。
- 第一阶段:格式检测与转换
- 使用模型:Gemini 2.5 Flash
- 步骤:将查询分类为QUESTION(问题)、KEYWORD(关键词)、STATEMENT(陈述句),并将STATEMENT格式转换为QUESTION格式。
- 第二阶段:质量验证与修正
- 使用模型:GPT-4o
- 步骤:检测不恰当的修正并进行重新修正。
使用示例
加载数据集的Python代码示例如下: python from datasets import load_dataset queries = load_dataset("sionic-ai/NanoBEIR-ko", "queries", split="NanoClimateFEVER") corpus = load_dataset("sionic-ai/NanoBEIR-ko", "corpus", split="NanoClimateFEVER") qrels = load_dataset("sionic-ai/NanoBEIR-ko", "qrels", split="NanoClimateFEVER")
预处理示例
预处理将原始陈述句查询转换为疑问句格式。
| 子集 | 原始查询 | 预处理后查询 |
|---|---|---|
| NanoClimateFEVER | 알래스카에서 갈색 곰들은 더 일찍 익는 엘더베리를 먹기 위해 먹이 섭취 습관을 바꾸고 있다. | 알래스카에서 갈색 곰들은 더 일찍 익는 엘더베리를 먹기 위해 먹이 섭취 습관을 바꾸고 있나요? |
| NanoClimateFEVER | 극지방의 빙하와 고산지대의 평원이 녹으면 메탄 가스가 위험하게 방출될 수 있다. | 극지방의 빙하와 고산지대의 평원이 녹으면 메탄 가스가 위험하게 방출될까요? |
| NanoClimateFEVER | 해빙은 과학자들과 기후 모델이 예상했던 것보다 훨씬 더 빠른 속도로 줄어들고 있다. | 해빙은 과학자들과 기후 모델이 예상했던 것보다 훨씬 더 빠른 속도로 줄어들고 있나요? |
| NanoClimateFEVER | 풍력 에너지의 탄소 발자국은 상당하다. | 풍력 에너지의 탄소 발자국은 상당한가? |
搜集汇总
数据集介绍
构建方式
在信息检索领域,构建高质量基准数据集对评估模型性能至关重要。NanoBEIR-ko数据集的构建采用了系统化的预处理流程,首先利用Gemini 2.5 Flash模型进行格式检测与转换,将原始陈述句分类并转化为疑问句式;随后通过GPT-4o模型进行质量验证与修正,确保查询语句的准确性与自然度,最终形成包含语料库、查询和相关性标注的结构化数据。
特点
该数据集作为韩国语信息检索的微型基准,其显著特点在于覆盖了十三个多样化的子集,如NanoClimateFEVER、NanoDBPedia等,每个子集均包含语料、查询及对应相关性标注,规模紧凑但领域广泛。数据经过精心预处理,所有查询均被统一转化为自然疑问句,提升了检索任务的一致性与评估的可靠性,为韩语检索模型提供了多场景的测试环境。
使用方法
研究人员可通过Hugging Face的datasets库便捷加载NanoBEIR-ko,分别导入queries、corpus和qrels三个配置,并指定所需子集进行实验。该数据集适用于训练和评估句子嵌入模型及检索系统,用户可依据查询在语料库中匹配相关文档,并利用标注数据计算检索指标,从而推动韩语信息检索技术的发展。
背景与挑战
背景概述
在信息检索领域,构建高质量的基准数据集对于评估和推进检索模型的性能至关重要。NanoBEIR-ko数据集作为NanoBEIR基准的韩语版本,由Sionic AI等机构的研究人员创建,旨在为韩语密集检索模型提供一个标准化、轻量化的评估框架。该数据集精心整合了来自ClimateFEVER、DBPedia、MSMARCO等13个知名检索数据集的子集,涵盖了科学论证、事实核查、问答等多种任务场景,其核心研究问题聚焦于解决韩语检索模型在多样化、多领域文本中精准匹配查询与文档的难题。通过提供经过统一预处理的查询、文档和相关度标注,该数据集显著降低了韩语检索研究的入门门槛,并为跨语言检索模型的性能对比提供了重要基准。
当前挑战
NanoBEIR-ko数据集致力于应对韩语信息检索领域的核心挑战,即如何在海量、多领域的韩语文本中实现高效且准确的语义匹配。具体而言,该挑战体现在模型需要理解复杂的韩语语法结构、处理专业领域术语,并克服韩语中丰富的形态变化和语境依赖性问题。在数据集构建过程中,研究人员面临多重技术障碍,包括将原始陈述句或关键词格式的查询统一转换为高质量的疑问句,这一过程需要先进的自然语言处理模型进行格式检测与语义转换。同时,确保转换后查询的语义保真度与流畅性,以及跨多个异构源数据集进行数据清洗、格式对齐与质量验证,均是构建过程中需要克服的关键难题。
常用场景
经典使用场景
在信息检索领域,NanoBEIR-ko数据集为韩语密集检索模型的评估提供了标准化基准。该数据集整合了多个经典检索任务的微型版本,涵盖科学文献、事实核查、问答等多种场景,研究者能够利用其统一的查询-文档对结构,系统性地测试模型在跨领域韩语文本上的检索性能。通过对比不同子集上的表现,可以深入分析模型在语义匹配、多跳推理等核心任务上的泛化能力。
解决学术问题
该数据集有效解决了韩语检索研究中基准数据稀缺且分散的学术困境。通过将BEIR基准中的13个任务韩语化并微型化,它构建了一个轻量级但全面的评估框架,使得研究者能够在资源受限条件下,高效验证检索模型的语言适应性与任务鲁棒性。其意义在于推动了韩语信息检索的标准化进程,为多语言检索模型的公平比较提供了关键基础设施,促进了该领域在非英语语境下的方法创新与理论发展。
衍生相关工作
围绕NanoBEIR-ko数据集,已衍生出一系列专注于韩语检索模型优化的经典工作。研究者们基于其多任务基准,开发了如Ko-SBERT、KorDense等预训练编码器,并在微调策略与负采样技术上取得了进展。这些工作不仅验证了跨语言迁移学习在韩语上的有效性,也推动了如DPR、ColBERT等先进检索架构的本地化适配,形成了以该数据集为核心的评价与创新循环。
以上内容由遇见数据集搜集并总结生成


