GUI-WORLD
收藏arXiv2024-06-16 更新2024-06-20 收录
下载链接:
https://gui-world.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
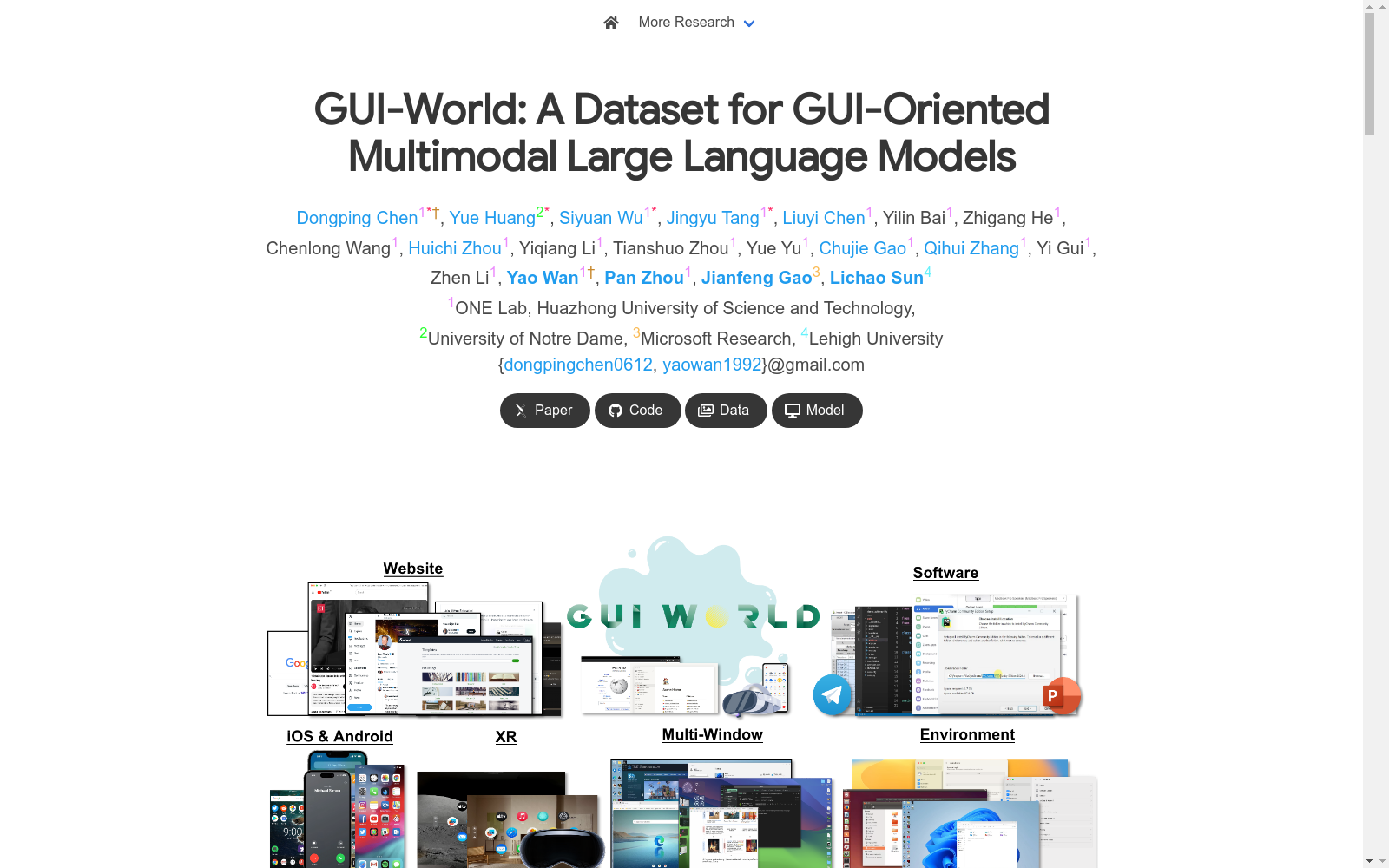
GUI-WORLD是由华中科技大学等机构联合创建的综合性数据集,专注于GUI理解领域,包含超过12,000个视频,覆盖桌面、移动和XR环境等多种场景。数据集通过从YouTube等平台收集的屏幕录制和教学视频构建,采用人机协同方法进行详细标注。GUI-WORLD旨在解决GUI代理在动态和序列化任务处理上的挑战,适用于网页理解、软件操作等多领域应用,为GUI理解能力的提升提供了重要资源。
GUI-WORLD is a comprehensive dataset jointly created by Huazhong University of Science and Technology and other institutions, focusing on the field of GUI understanding. It contains over 12,000 videos covering diverse scenarios including desktop, mobile and XR environments. The dataset is constructed from screen recordings and tutorial videos collected from platforms such as YouTube, with detailed annotations conducted via a human-machine collaborative approach. GUI-WORLD aims to address the challenges faced by GUI agents in handling dynamic and sequential tasks, and is applicable to multi-domain applications such as webpage understanding and software operation, providing an important resource for enhancing GUI understanding capabilities.
提供机构:
华中科技大学
创建时间:
2024-06-16
搜集汇总
数据集介绍
构建方式
在图形用户界面理解领域,现有研究多聚焦于静态网页或移动端界面,缺乏对动态内容与多场景覆盖的综合性评估。为此,GUI-WORLD 数据集通过精心设计的两阶段流程构建而成。首先,研究团队从学生工作者的屏幕录制和 YouTube 教学视频中收集了超过 12,000 个 GUI 视频,涵盖网站、桌面软件、移动操作系统、多窗口交互及扩展现实等六类场景。随后,采用人机协同标注策略:由人工标注关键帧并描述操作意图,再输入 GPT-4V 生成详细描述、摘要及八类问题,包括静态内容检索、序列推理和动态预测等。最后,人工审核员对生成内容进行校正与补充,确保问答对的准确性与挑战性,从而形成兼具广度与深度的 GUI 导向指令微调数据集。
特点
GUI-WORLD 的突出特点在于其全面性与动态性。该数据集覆盖了六种 GUI 场景,包括传统网站、移动应用、桌面软件、多窗口环境以及新兴的扩展现实界面,突破了以往研究局限于单一场景的桎梏。其问题类型丰富多样,不仅包含对图标、文本和布局的静态分析,更强调对时序信息和动态内容的理解,例如基于图像序列的预测任务和多轮对话推理。数据集中每个视频均配有手动提取的关键帧和详细的操作注释,平均关键帧数达 6.719 帧,为模型理解 GUI 操作的细微变化提供了坚实基础。此外,超过 12,000 个视频及其对应的多种格式问答,构成了目前首个面向视频的 GUI 指令微调数据集,为评估和提升多模态大模型在复杂图形界面中的认知能力设立了新标杆。
使用方法
该数据集主要用于评估和增强多模态大模型在 GUI 导向任务中的能力。研究者可基于 GUI-WORLD 构建全面的评测基准,对图像大模型和视频大模型在静态、序列及动态 GUI 内容理解上的表现进行系统分析。具体而言,可将数据集中提供的视频、关键帧序列及对应问答作为输入,测试模型在多项选择、自由问答和对话任务中的性能。此外,数据集支持关键帧选择策略的对比研究,例如随机采样、程序提取与人工标注帧的效果差异。对于模型开发,可利用其进行两阶段微调:第一阶段使用详细描述和摘要数据对齐 GUI 内容与语言模型,奠定基础认知;第二阶段引入更复杂的预测、推理和对话任务,提升模型在真实 GUI 环境中的交互与决策能力。数据集的公开提供也为后续 GUI 智能体的训练与迭代提供了宝贵资源。
背景与挑战
背景概述
GUI-WORLD数据集由华中科技大学、圣母大学、微软研究院及利哈伊大学等机构的研究团队于2024年6月联合发布,旨在应对多模态大语言模型在图形用户界面理解领域的核心挑战。该数据集聚焦于GUI导向的智能体开发,针对现有研究多局限于静态网页或移动端界面的不足,首次系统性地涵盖了桌面软件、多窗口交互及扩展现实等六类复杂场景,并提供了超过1.2万段标注视频与多样化问答对。其构建采用了人机协同的精细化标注框架,通过融合屏幕录制与社交媒体教程视频,显著提升了数据在时序操作与动态内容层面的覆盖广度与深度,为推进GUI智能体的跨平台泛化与动态任务执行能力奠定了关键基础。
当前挑战
GUI-WORLD数据集所应对的核心领域挑战在于提升多模态大语言模型对动态时序GUI内容的理解与推理能力。传统模型在静态图像分类与描述任务中表现优异,却难以处理界面元素的连续变化、用户操作序列的因果关联以及跨窗口的交互逻辑,尤其在广告弹窗、多步流程等动态场景中易出现决策中断。数据构建过程中亦面临多重挑战:一是高质量关键帧的提取困难,GUI视频中鼠标移动、界面微调等细微变化使得自动化算法难以准确捕捉操作转折点,需依赖大量人工标注;二是跨平台数据的采集与标注复杂度高,需协调不同操作系统、软件版本及交互模式的差异,确保数据的一致性与代表性;三是时序任务标注的语义完整性要求严苛,需在视频片段中精准识别操作意图并生成逻辑连贯的问答对,对标注者的领域知识提出了较高要求。
常用场景
经典使用场景
在图形用户界面(GUI)智能体研究领域,GUI-WORLD数据集为评估和增强多模态大语言模型(MLLMs)的界面理解能力提供了基准平台。该数据集通过涵盖网站、桌面软件、移动操作系统、多窗口交互及扩展现实(XR)环境等六大场景,系统性地构建了超过12,000个GUI视频及其对应的人类-MLLM协作标注,包括详细描述、摘要式标注以及多种问答格式。这一设计使得研究者能够全面测试模型在静态内容解析、动态序列理解、跨场景泛化等方面的性能,尤其聚焦于模型对时序操作和界面动态变化的感知能力,为GUI导向的智能体开发奠定了数据基础。
实际应用
在实际应用层面,GUI-WORLD数据集为构建通用GUI控制智能体提供了训练与评估基础。基于该数据集训练的模型可应用于自动化软件操作、跨平台任务执行、无障碍辅助技术及XR环境交互等场景。例如,智能体能够通过学习视频中的操作序列,实现自动填写表单、管理多窗口工作流、或在混合现实界面中完成导航任务。这些能力有望提升办公自动化、远程协助、用户体验测试等领域的效率,同时为残障人士提供更自然的计算机交互方式。数据集的多样性和真实性确保了模型在真实应用场景中的可靠性和适应性。
衍生相关工作
GUI-WORLD的发布催生了一系列相关研究,其中最直接的工作是基于该数据集微调的GUI-Vid模型,该模型作为首个面向GUI任务的视频大语言模型,在动态内容理解任务上显著优于基线。此外,数据集的评估框架被广泛应用于比较GPT-4V、Gemini、Qwen-VL等主流MLLMs的GUI感知能力,揭示了现有模型在时序推理和跨场景泛化方面的不足。这些发现进一步激发了针对关键帧选择策略、视觉-文本对齐方法以及高分辨率输入影响的研究,推动了如ScreenAgent、OSWorld等通用控制智能体的发展,并为后续探索更高效的GUI视频表示学习提供了实证基础。
以上内容由遇见数据集搜集并总结生成


