LiM-De/blenderllm-v2-polyhaven-dataset
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/LiM-De/blenderllm-v2-polyhaven-dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_examples: 493
size_categories:
- n<1K
language:
- en
license: apache-2.0
tags:
- blender
- bpy
- 3d-modeling
- poly-haven
- code-generation
---
# BlenderLLM v2 - Poly Haven Training Dataset
Fine-tuning dataset for BlenderLLM to use **local Poly Haven library** (2,194 assets).
## Purpose
BlenderLLM v1 only generates primitive-based scripts. This dataset teaches it to:
- **Load models** from local .blend files (426 models)
- **Apply HDRIs** for realistic lighting (963 HDRIs)
- **Apply textures** with PBR materials (805 textures)
- **Compose scenes** combining real assets + primitives
- **Search/list** available assets by category
- **Handle errors** (missing assets, overlaps, verification)
## Dataset Structure
| Category | Samples | Description |
|----------|---------|-------------|
| Load single model | 100 | bpy.data.libraries.load() from .blend |
| Load + position | 100 | Load + location/rotation |
| HDRI lighting | 80 | World environment from .hdr |
| Apply textures | 80 | Diffuse + Normal maps |
| Scene compositions | 32 | Multi-asset + HDRI + camera |
| Search assets | 20 | os.listdir + info.json |
| Error handling | 33 | Missing assets, verification |
| Combined (primitives + assets) | 48 | Hybrid scenes |
| **Total** | **493** | |
## Base Model
[FreedomIntelligence/BlenderLLM](https://huggingface.co/FreedomIntelligence/BlenderLLM) (Qwen2.5-Coder-7B fine-tuned on BlendNet 12.1K samples)
## Training
See for the complete Unsloth LoRA training notebook.
## Local Poly Haven Library
Assets at:
- Each asset: + +
- Models loaded with:
- HDRIs loaded with:
数据集信息:
特征字段:
- 名称:指令(instruction)
数据类型:字符串(string)
- 名称:输出(output)
数据类型:字符串(string)
数据集划分:
- 名称:训练集(train)
样本数量:493
样本规模类别:样本量小于1000(n<1K)
语言:英语(en)
开源协议:Apache 2.0(apache-2.0)
标签:Blender、bpy、三维建模(3d-modeling)、Poly Haven、代码生成(code-generation)
# BlenderLLM v2 - Poly Haven 训练数据集
本数据集为BlenderLLM的微调专用数据集,用于调用本地Poly Haven资源库(共包含2194个资源资产)。
## 数据集用途
BlenderLLM v1仅支持生成基于基础图元的脚本。本数据集可帮助模型掌握以下能力:
- 从本地.blend格式文件加载模型(共计426个模型)
- 应用高动态范围图像(HDRI)实现写实级光照效果(共计963个HDRI资源)
- 为模型添加基于物理的渲染(PBR)材质纹理(共计805组纹理资源)
- 搭建融合真实资产与基础图元的复合场景
- 根据分类规则搜索、列举可用资源资产
- 处理各类异常场景(如资源缺失、资源冲突、合规校验等)
## 数据集结构
| 任务类别 | 样本数量 | 功能描述 |
|----------|---------|-------------|
| 加载单模型 | 100 | 通过bpy.data.libraries.load()读取.blend文件 |
| 加载并定位模型 | 100 | 加载模型并设置其位置与旋转参数 |
| HDRI光照设置 | 80 | 通过.hdr文件设置世界环境光照 |
| 应用纹理材质 | 80 | 添加漫反射与法线贴图 |
| 场景组合搭建 | 32 | 多资产+HDRI+相机的完整场景 |
| 资源资产搜索 | 20 | 通过os.listdir与info.json检索资源 |
| 异常处理 | 33 | 处理资源缺失、合规校验等异常场景 |
| 混合场景(基础图元+资产) | 48 | 融合基础图元与真实资产的混合场景 |
| **总计** | **493** | |
## 基础模型
[FreedomIntelligence/BlenderLLM](https://huggingface.co/FreedomIntelligence/BlenderLLM)(基于BlendNet的12.1K样本对Qwen2.5-Coder-7B大语言模型进行微调得到的模型)
## 训练流程
完整的Unsloth LoRA训练教程可参阅对应资料。
## 本地Poly Haven资源库
资源存放路径:
- 单条资产: + +
- 模型加载方式:
- HDRI资源加载方式:
提供机构:
LiM-De
搜集汇总
数据集介绍
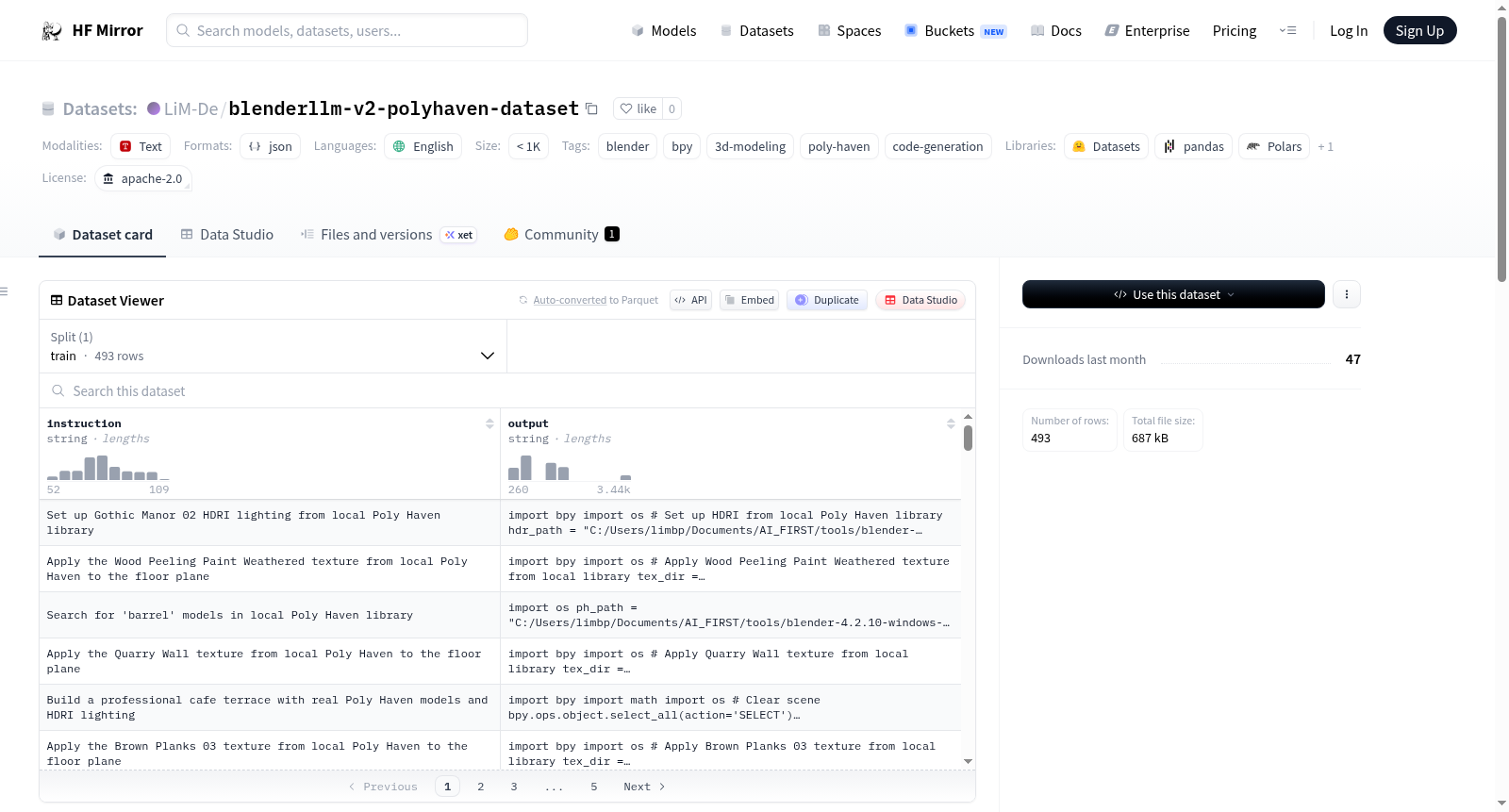
构建方式
在三维建模与计算机图形学领域,高质量的数据集对于训练能够理解复杂场景构建的模型至关重要。BlenderLLM v2 - Poly Haven训练数据集的构建基于对本地Poly Haven资源库的深度整合,该资源库包含2,194个资产,涵盖模型、高动态范围图像和纹理。数据集的493个样本通过精心设计的任务类别生成,包括加载单个模型、定位模型、应用HDR照明、纹理映射、场景合成、资产搜索及错误处理等,每个样本均以指令-输出对的形式呈现,确保模型能够学习从本地.blend文件加载资源、组合真实资产与图元,并处理缺失或重叠资产等实际场景中的复杂操作。
使用方法
使用BlenderLLM v2数据集时,研究人员或开发者可将其用于微调基于Qwen2.5-Coder-7B的BlenderLLM基础模型,以增强模型在三维场景生成中的代码生成能力。数据集以标准的指令-输出格式组织,可直接应用于训练流程,如通过Unsloth LoRA等高效微调技术。用户需确保本地已配置Poly Haven资源库,并按照数据集提供的示例,指导模型学习从特定路径加载资产、应用照明与纹理,以及组合复杂场景。该数据集适用于计算机图形学、自动化三维建模及代码生成领域的研究与开发项目。
背景与挑战
背景概述
随着三维建模与计算机图形学领域的快速发展,自动化场景生成技术逐渐成为研究热点。BlenderLLM-v2-Polyhaven数据集由FreedomIntelligence团队于近期构建,旨在扩展大型语言模型在Blender环境中的实际应用能力。该数据集聚焦于解决基于本地Poly Haven资源库的复杂三维场景合成问题,通过493条精细标注的指令-输出对,教导模型如何加载外部模型、应用高动态范围图像照明、添加纹理材质,并进行多资产场景组合。这一工作不仅推动了代码生成与三维视觉的交叉研究,也为智能内容创作工具的开发提供了关键数据支撑。
当前挑战
在三维场景自动生成领域,模型需克服资产管理与空间布局的复杂性,例如精准调用本地资源库中的特定模型、协调多种材质与光照效果,并避免物体间的冲突与重叠。数据集构建过程中,研究人员面临多类挑战:一是如何设计多样化的指令以覆盖从单一模型加载到复合场景合成的完整工作流;二是确保生成的Blender Python脚本在语法与功能上的正确性,需处理资产路径验证、错误恢复等边缘情况;三是平衡不同任务类别的样本分布,使模型能均衡学习搜索、组合与纠错等能力,从而在有限数据规模下实现泛化性能的提升。
常用场景
经典使用场景
在三维建模与计算机图形学领域,BlenderLLM v2 - Poly Haven数据集主要用于训练大型语言模型生成Blender脚本,以自动化操作本地Poly Haven资产库。该数据集的核心应用场景是教导模型如何加载本地.blend格式的三维模型、应用高动态范围图像(HDRI)进行光照设置,以及为模型赋予基于物理渲染(PBR)的纹理材质。通过结合真实资产与基础几何体,模型能够生成复杂的场景组合脚本,从而显著提升三维内容创作的效率与自动化水平。
解决学术问题
该数据集旨在解决三维建模自动化中代码生成的学术挑战,特别是如何将自然语言指令转化为可执行的Blender操作脚本。它突破了早期版本仅能生成基础几何体脚本的限制,通过引入对本地资产库的调用能力,解决了模型加载、光照配置、纹理应用等多模态任务集成问题。其意义在于推动了语言模型在专业图形软件中的实际应用,为跨模态人工智能研究提供了重要数据支撑,促进了自动化三维内容生成技术的发展。
实际应用
在实际应用中,该数据集支持了智能三维建模助手系统的开发,允许用户通过自然语言描述直接生成Blender场景。例如,设计师可以指令“创建一个带有木质纹理的沙发模型并添加室内HDRI光照”,系统便能自动调用本地Poly Haven资产库中的沙发模型和纹理,并配置相应光照环境。这种应用不仅降低了三维建模的专业门槛,还大幅缩短了场景搭建时间,在游戏开发、影视预演、虚拟现实等领域具有广泛实用价值。
数据集最近研究
最新研究方向
在三维建模与计算机图形学领域,BlenderLLM v2 - Poly Haven数据集正推动基于大语言模型的自动化场景生成技术迈向新阶段。该数据集专注于教导模型如何整合本地Poly Haven资源库中的高质量资产,包括模型、高动态范围图像和纹理,以实现从基础几何体到复杂真实感场景的跨越。前沿研究聚焦于多模态指令跟随与代码生成,旨在提升模型在资产加载、光照配置、材质应用及错误处理等方面的精确性与鲁棒性。这一方向不仅呼应了AIGC在创意产业中加速内容创作的热潮,也为降低三维内容制作门槛、促进个性化数字环境构建提供了关键技术支撑,对游戏开发、影视制作和虚拟现实等领域具有深远影响。
以上内容由遇见数据集搜集并总结生成


