sal
收藏Hugging Face2025-03-28 更新2025-03-29 收录
下载链接:
https://huggingface.co/datasets/pss0204/sal
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了问题、解决方案和答案等教育相关数据,涵盖了不同的科目和难度级别。数据集分为训练集,并提供了多种预测结果和相关评分信息,用于评估模型在不同情况下的表现。
This dataset encompasses education-related data such as questions, solutions and answers, spanning a wide range of subjects and difficulty levels. It is divided into training subsets, and provides a variety of prediction outcomes and corresponding scoring metrics to assess the performance of models across diverse scenarios.
创建时间:
2025-03-28
搜集汇总
数据集介绍
构建方式
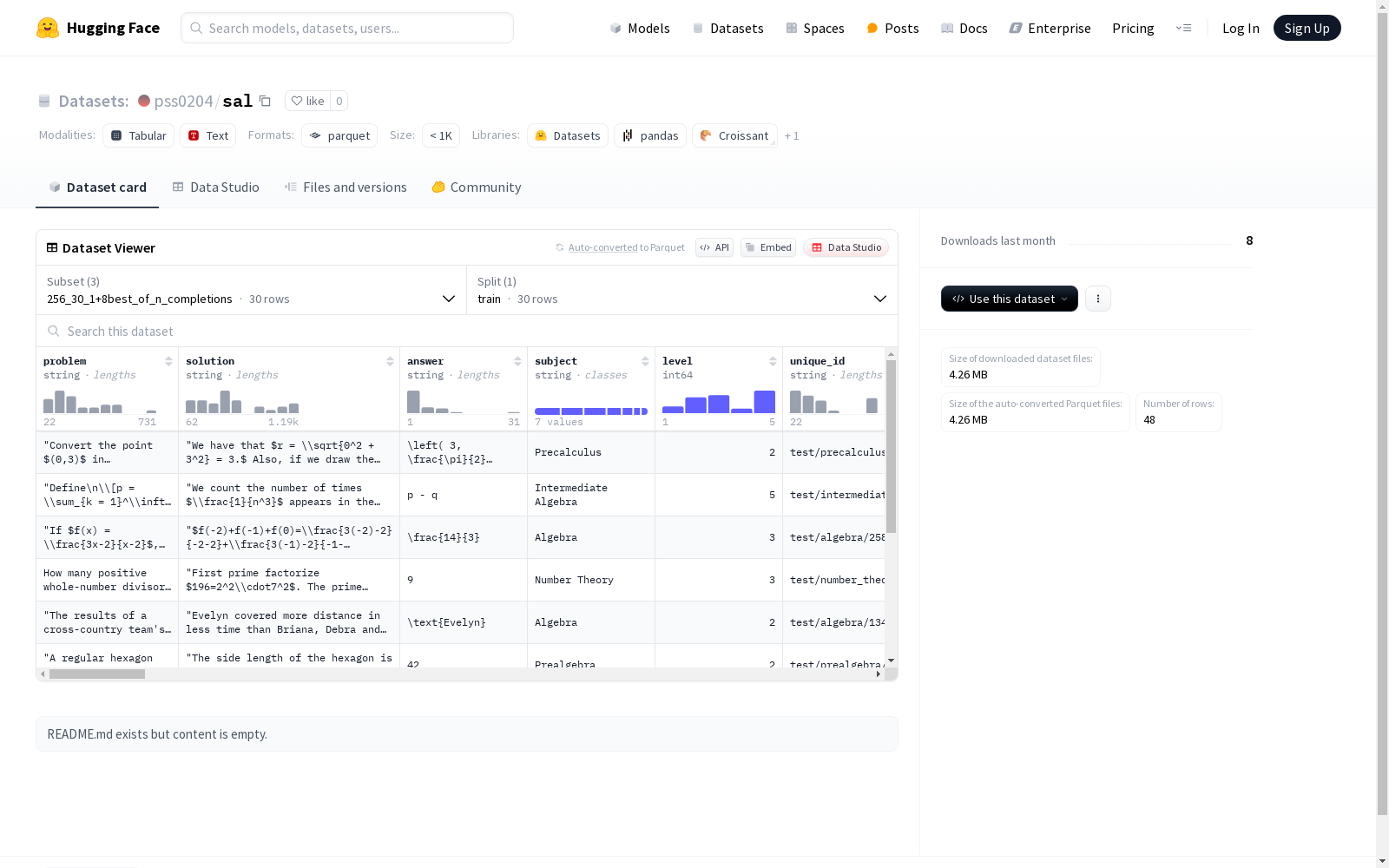
在人工智能教育领域,sal数据集的构建采用了多层次的结构化设计方法。数据集通过256_30_1+8best_of_n_completions、qwen_n4_best_of_n_completions等多种配置模式,系统性地收集了包含问题描述、解决方案、参考答案等核心要素的教育数据。每个数据样本都标注了学科类别和难度等级,并通过unique_id确保数据唯一性。特别值得注意的是,数据集采用序列化方式存储了不同模型生成的多个补全结果及其对应评分,为研究模型输出的多样性提供了丰富素材。
使用方法
使用该数据集时,研究者可根据config_name选择适合的配置版本进行加载。对于模型评估研究,可通过分析不同n值下的acc_naive、acc_weighted等指标来比较预测方法的优劣。教育应用场景下,可结合subject和level字段实现学科专属模型的训练与测试。数据集提供的pred_weighted@n系列字段,特别适合用于研究预测集成方法在不同规模下的表现规律。所有数据均采用标准化的JSON格式存储,可通过HuggingFace数据集库直接加载使用。
背景与挑战
背景概述
sal数据集是一个专注于问题解决与答案生成的多维度评估数据集,由前沿研究团队构建,旨在探索大规模语言模型在复杂问题求解中的表现。该数据集涵盖了多个学科领域的问题及其解决方案,通过独特的评分机制和预测方法,为研究者提供了丰富的模型性能评估基准。其核心研究问题聚焦于如何通过不同的预测策略(如加权预测、多数投票等)提升模型生成答案的准确性与可靠性,对推动自然语言处理领域的模型优化与评估方法创新具有重要意义。
当前挑战
sal数据集面临的挑战主要体现在两个方面:领域问题的复杂性与数据构建的技术难度。在领域问题方面,如何准确评估模型在不同学科、不同难度级别问题上的表现,尤其是处理多步骤推理和跨学科知识融合的问题,仍是一个开放性的研究难题。在数据构建过程中,设计合理的评分体系以捕捉生成答案的细微差异,以及确保不同预测策略之间的可比性,均对数据标注与质量控制提出了极高要求。此外,随着模型规模的扩大,如何平衡计算资源消耗与评估效率也成为亟待解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,sal数据集以其结构化的数学问题解决记录而著称,特别适用于算法生成与评估研究。该数据集通过包含问题描述、解决方案、评分序列等多元特征,为研究者提供了分析模型在不同复杂度数学题上表现能力的标准测试平台。其多层次预测结果和加权评分机制,使得该数据集成为验证模型推理能力与决策过程透明度的理想选择。
解决学术问题
sal数据集有效解决了自动解题系统中答案生成质量评估的基准缺失问题。通过提供带权重评分的多版本预测结果,该数据集使研究者能够量化分析不同采样策略对模型输出的影响。其细粒度的评分序列和学科分类信息,为研究领域自适应学习和知识迁移提供了重要实验数据,推动了教育智能化领域评估方法论的发展。
实际应用
在教育科技领域,sal数据集可应用于智能辅导系统的核心算法开发。基于其丰富的解题轨迹数据,开发者能够训练系统识别最优解题路径,并为学生提供个性化反馈。医疗诊断辅助系统也可借鉴其加权决策机制,通过多专家意见整合提高诊断准确性。金融领域的风险评估模型同样能利用类似的集成预测方法提升决策可靠性。
数据集最近研究
最新研究方向
在自然语言处理领域,sal数据集以其独特的多维度评估框架成为研究热点。该数据集通过整合问题、解决方案、答案及学科分类等特征,为大型语言模型的性能评估提供了丰富基准。当前研究聚焦于探索不同加权策略(如pred_weighted@N与pred_maj@N)对模型输出的影响,特别是在数学推理和科学问题求解任务中的表现差异。随着Qwen等开源模型的崛起,基于completions序列和scores矩阵的对比分析成为验证模型鲁棒性的重要手段,相关成果正推动着自适应权重算法和集成推理技术的发展。
以上内容由遇见数据集搜集并总结生成


