tw-bar-examination-2020-chat
收藏Hugging Face2024-08-07 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/lianghsun/tw-bar-examination-2020-chat
下载链接
链接失效反馈官方服务:
资源简介:
本数据集是基于Jamie0510/taiwan-law-exam数据集的后处理版本,去除了缺少数据的栏位,并转换为Alpaca数据集格式。数据集包含繁体中文的法律考试题目,适用于监督式微调任务,帮助模型学习如何回答繁体中文法律题目。数据集分为训练集和测试集,分别包含269笔和30笔数据。数据集的创建过程中没有涉及个人和敏感信息。
This dataset is a post-processed version based on the Jamie0510/taiwan-law-exam dataset, with fields containing missing data removed and converted to the Alpaca dataset format. It includes Traditional Chinese law examination questions, and is designed for supervised fine-tuning tasks to assist models in learning to answer Traditional Chinese law-related questions. The dataset is split into training and test sets, containing 269 and 30 samples respectively. No personal or sensitive information was involved in the process of creating this dataset.
创建时间:
2024-08-07
原始信息汇总
中華民國2020年律師考試題目(tw-bar-examination-2020-chat)
数据集概述
本数据集是从 Jamie0510/taiwan-law-exam 经过后处理得到的,去除了缺少数据的字段,并转换为 Alpaca 数据集格式。
支持的任务和排行榜
该数据集适用于监督式微调,使模型学会如何回答繁体中文法律题目。建议在训练过本数据集后,再进行 lianghsun/tw-legal-benchmark-v1 的评测,以获得更好的表现。
语言
繁体中文。
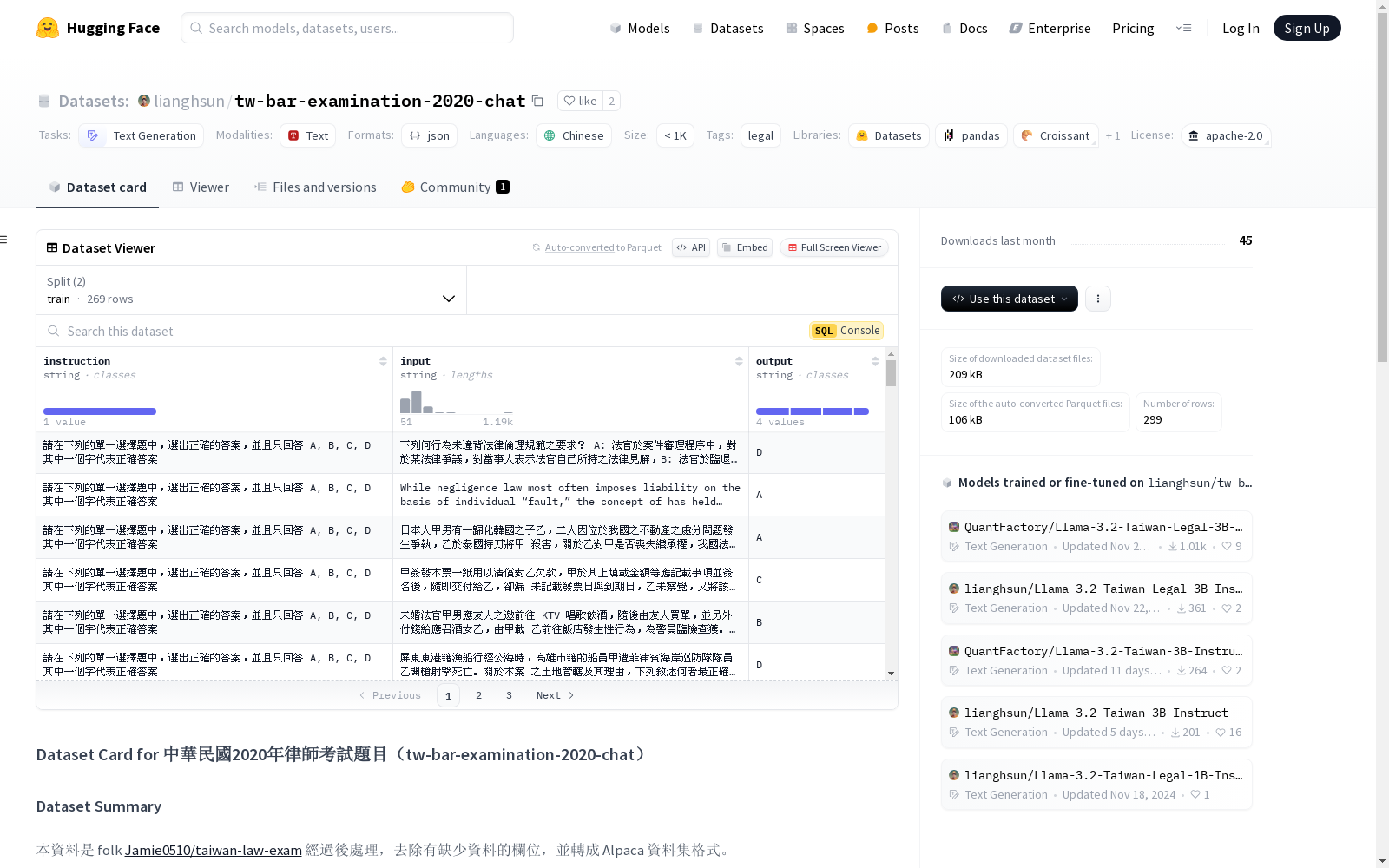
数据集结构
数据分割
train.jsonl: 包含 269 条数据,从 Jamie0510/taiwan-law-exam 中的四类考试合并后抽取 90% 的题目。test.jsonl: 包含 30 条数据,从 Jamie0510/taiwan-law-exam 中的四类考试合并后抽取 10% 的题目。
数据集创建
源数据
个人和敏感信息
无。
许可证
apache-2.0
搜集汇总
数据集介绍
构建方式
tw-bar-examination-2020-chat数据集基于Jamie0510/taiwan-law-exam数据集进行构建,经过后处理步骤,剔除了存在数据缺失的字段,并将其转换为Alpaca数据集格式。该数据集整合了四类考试题目,从中抽取90%的题目作为训练集,剩余10%作为测试集,确保了数据的完整性和适用性。
特点
该数据集专注于繁体中文法律题目的文本生成任务,特别适用于监督式微调(Supervised Fine-tuning)场景。数据集中的题目涵盖了广泛的法律领域,能够帮助模型学习如何准确回答复杂的法律问题。此外,该数据集与tw-legal-benchmark-v1评测集结合使用,可进一步提升模型在法律领域的表现。
使用方法
使用tw-bar-examination-2020-chat数据集时,建议首先对模型进行监督式微调,使其熟悉繁体中文法律题目的回答模式。训练完成后,可将模型应用于tw-legal-benchmark-v1评测集,以验证其在实际法律问题中的表现。数据集以JSONL格式提供,便于直接加载和使用,适用于各类自然语言处理框架。
背景与挑战
背景概述
tw-bar-examination-2020-chat数据集源自2020年中华民国律师考试题目,经过后处理并转换为Alpaca数据集格式,旨在支持繁体中文法律题目的生成任务。该数据集的创建由Jamie0510发起,主要研究人员通过整合和筛选原始数据,确保了数据的完整性和适用性。该数据集不仅为法律领域的自然语言处理研究提供了宝贵的资源,还推动了法律智能问答系统的发展,对提升法律文本理解和生成能力具有重要意义。
当前挑战
该数据集在应用过程中面临多重挑战。首先,法律文本的复杂性和专业性要求模型具备高度的语义理解和推理能力,这对模型的训练和优化提出了较高要求。其次,数据集的构建过程中,如何确保数据的准确性和完整性是一个关键问题,尤其是在处理繁体中文法律文本时,语言的特殊性和法律术语的精确性增加了数据处理的难度。此外,数据集的规模相对较小,可能限制了模型的泛化能力,如何在有限的数据基础上提升模型的性能是另一个亟待解决的问题。
常用场景
经典使用场景
tw-bar-examination-2020-chat数据集主要用于监督微调(Supervised Fine-tuning)任务,帮助模型学习如何回答繁体中文的法律考试题目。通过对该数据集的训练,模型能够更好地理解和应对复杂的法律问题,从而在法律领域的自然语言处理任务中表现出色。
衍生相关工作
基于tw-bar-examination-2020-chat数据集,研究者们开发了一系列相关的工作,如法律文本生成模型、法律问答系统等。这些工作不仅提升了模型在法律领域的表现,还为法律智能化的进一步发展奠定了基础。
数据集最近研究
最新研究方向
近年来,随着自然语言处理技术的飞速发展,法律领域的文本生成任务逐渐成为研究热点。tw-bar-examination-2020-chat数据集作为繁体中文法律题目的重要资源,为模型在监督式微调(Supervised Fine-tuning)中的应用提供了坚实基础。该数据集不仅能够帮助模型理解和生成符合法律规范的文本,还为后续在lianghsun/tw-legal-benchmark-v1等法律基准测试中的表现优化提供了关键支持。通过结合深度学习与法律知识,该数据集推动了法律智能化的发展,为法律文本的自动化处理与生成开辟了新的研究方向。
以上内容由遇见数据集搜集并总结生成


