Vl-RewardBench
收藏Hugging Face2024-12-08 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Zhihui/Vl-RewardBench
下载链接
链接失效反馈官方服务:
资源简介:
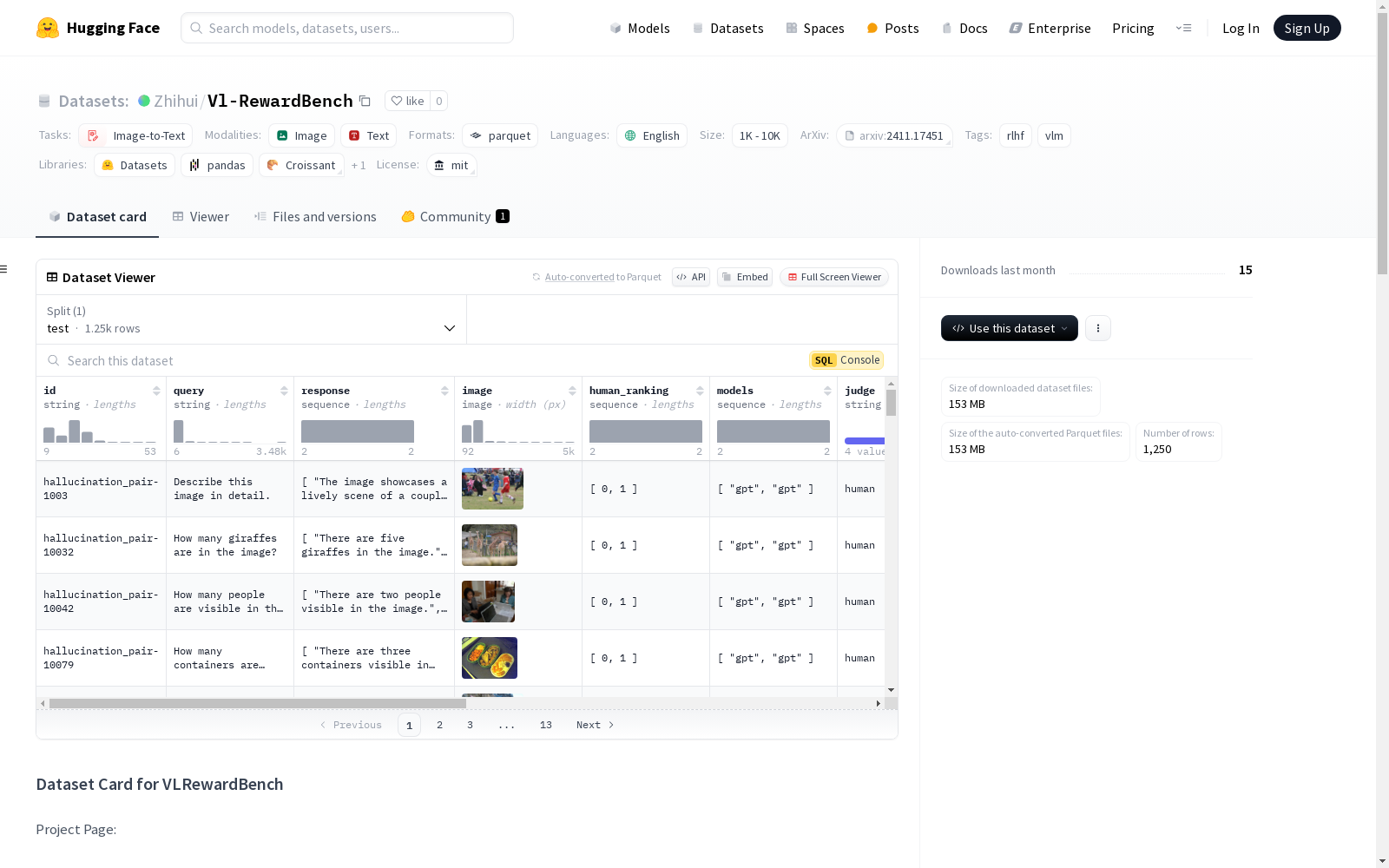
VLRewardBench是一个综合性的基准测试,旨在评估视觉语言生成奖励模型(VL-GenRMs)在视觉感知、幻觉检测和推理任务中的表现。该基准包含1,250个高质量的示例,专门设计用于探测模型的局限性。每个实例包含多模态查询,涵盖三个关键领域:一般多模态查询、视觉幻觉检测任务和多模态知识与数学推理。数据集的结构包括多个字段,如实例ID、多模态提示的文本查询、图像输入、由模型生成的两个候选响应、人类对两个响应的排名、错误分析标签、生成响应的模型以及实例的来源数据集。数据集的目的是用于研究用途,特别是评估和改进视觉语言奖励模型,研究模型在视觉感知和推理中的局限性,以及开发更好的多模态AI系统。
VLRewardBench is a comprehensive benchmark designed to evaluate Visual-Language Generation Reward Models (VL-GenRMs) on visual perception, hallucination detection and reasoning tasks. This benchmark comprises 1,250 high-quality examples specifically crafted to probe the limitations of such models. Each instance contains multimodal queries spanning three core domains: general multimodal queries, visual hallucination detection tasks, and multimodal knowledge and mathematical reasoning. The dataset structure includes multiple fields, such as instance ID, text query of multimodal prompts, image input, two candidate responses generated by the model, human rankings of the two responses, error analysis labels, the model that generated the responses, and the source dataset of the instance. The dataset is intended for research purposes, specifically to evaluate and improve visual-language reward models, investigate the limitations of models in visual perception and reasoning, and develop better multimodal AI systems.
创建时间:
2024-11-29
原始信息汇总
VLRewardBench 数据集概述
数据集摘要
VLRewardBench 是一个综合基准,旨在评估视觉-语言生成奖励模型(VL-GenRMs)在视觉感知、幻觉检测和推理任务中的表现。该基准包含 1,250 个高质量示例,专门设计用于探测模型的局限性。
数据集结构
每个实例包含跨三个关键领域的多模态查询:
- 来自真实用户的通用多模态查询
- 视觉幻觉检测任务
- 多模态知识和数学推理
数据字段
关键字段:
id: 实例 IDquery: 多模态提示的文本查询image: 多模态提示的图像输入response: 由模型生成的两个候选响应列表human_ranking: 两个响应的排名,[0, 1]表示第一个响应更优,[1, 0]表示第二个响应更优human_error_analysis: 偏好对的注释错误标签models: 生成响应的相应模型,适用于wildvision子集的实例query_source: 实例的来源数据集- WildVision
- POVID
- RLAIF-V
- RLHF-V
- MMMU-Pro
- MathVerse
注释
- 使用小型 LVLMs 过滤具有挑战性的样本
- 强大的商业模型生成带有显式推理路径的响应
- GPT-4o 进行质量评估
- 所有偏好标签都经过人工验证
使用目的
该数据集仅用于研究目的,具体用于:
- 评估和改进视觉-语言奖励模型
- 研究模型在视觉感知和推理中的局限性
- 开发更好的多模态 AI 系统
许可证
仅限研究使用。使用受 GPT-4o 和 Claude 的许可证协议限制。
引用信息
bibtex @article{VLRewardBench, title={VLRewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models}, author={Lei Li and Yuancheng Wei and Zhihui Xie and Xuqing Yang and Yifan Song and Peiyi Wang and Chenxin An and Tianyu Liu and Sujian Li and Bill Yuchen Lin and Lingpeng Kong and Qi Liu}, year={2024}, journal={arXiv preprint arXiv:2411.17451} }
搜集汇总
数据集介绍
构建方式
VLRewardBench数据集的构建旨在评估视觉-语言生成奖励模型(VL-GenRMs)在视觉感知、幻觉检测和推理任务中的表现。该数据集精心挑选了1,250个高质量样本,涵盖了多模态查询的三个关键领域:真实用户的通用多模态查询、视觉幻觉检测任务以及多模态知识和数学推理。数据集中的每个实例包括一个多模态查询、对应的图像输入、由模型生成的两个候选响应、人类对响应的排名、错误分析标签以及生成响应的模型信息。所有标注均经过人工验证,确保数据集的高质量和可靠性。
特点
VLRewardBench数据集的显著特点在于其多模态性和高质量的标注。数据集不仅涵盖了广泛的多模态查询,还特别关注了视觉幻觉检测和复杂推理任务,这使得该数据集在评估和提升视觉-语言模型的能力方面具有独特优势。此外,数据集中的每个实例都包含了详细的错误分析和模型信息,这为研究者提供了深入分析模型性能和局限性的机会。
使用方法
VLRewardBench数据集主要用于研究目的,特别适用于评估和改进视觉-语言奖励模型。研究者可以利用该数据集进行模型性能的基准测试,分析模型在视觉感知和推理任务中的局限性,并探索如何开发更先进的多模态AI系统。由于数据集的复杂性和高质量标注,它为研究者提供了一个理想的平台,用于推动视觉-语言模型领域的研究进展。
背景与挑战
背景概述
VLRewardBench数据集由Lei Li等人于2024年创建,旨在为视觉-语言生成奖励模型(VL-GenRMs)提供一个全面的评估基准。该数据集聚焦于视觉感知、幻觉检测和推理任务,包含1,250个高质量的多模态查询实例,涵盖了从真实用户查询到复杂的数学推理等多种场景。其核心研究问题在于揭示和评估多模态模型在这些任务中的表现,尤其是模型在处理视觉信息和语言生成时的局限性。VLRewardBench的发布对多模态AI系统的发展具有重要意义,为研究人员提供了一个标准化的测试平台,以推动该领域的技术进步。
当前挑战
VLRewardBench数据集在构建过程中面临多重挑战。首先,多模态查询的复杂性要求数据集能够覆盖广泛的场景,包括视觉幻觉检测和多模态知识推理,这增加了数据收集和标注的难度。其次,生成高质量的候选响应需要依赖强大的商业模型,如GPT-4o,这些模型的使用受到严格的许可限制,进一步增加了数据集的构建成本。此外,为了确保标注的准确性,所有偏好标签都经过了人工验证,这一过程耗时且资源密集。最后,数据集的使用受到相关模型的许可协议限制,限制了其在更广泛范围内的应用。
常用场景
经典使用场景
VLRewardBench数据集的经典使用场景主要集中在视觉-语言生成奖励模型(VL-GenRMs)的评估与改进上。该数据集通过包含多模态查询、图像输入、模型生成的候选响应以及人类排序等字段,能够有效评估模型在视觉感知、幻觉检测和推理任务中的表现。研究者可以利用此数据集对模型进行细致的性能分析,识别并改进其在多模态任务中的不足。
衍生相关工作
VLRewardBench数据集的发布催生了一系列相关研究工作,特别是在多模态生成模型和奖励机制的优化方面。研究者们基于该数据集开发了新的评估方法和模型架构,以提升视觉-语言生成模型的性能。此外,该数据集还激发了对多模态任务中模型局限性的深入研究,推动了多模态AI领域的技术进步和创新。
数据集最近研究
最新研究方向
在视觉语言生成领域,VLRewardBench数据集的最新研究方向主要聚焦于提升视觉语言奖励模型(VL-GenRMs)的性能,特别是在视觉感知、幻觉检测和推理任务中的表现。该数据集通过精心设计的1,250个高质量实例,深入探索了模型在这些复杂任务中的局限性。研究者们正致力于通过分析模型生成的响应与人类偏好之间的差异,进一步优化模型的多模态理解和生成能力。此外,VLRewardBench还为开发更先进的视觉语言AI系统提供了宝贵的资源,推动了多模态AI技术在实际应用中的发展。
以上内容由遇见数据集搜集并总结生成


