FatimahEmadEldin/Moroccan-Arabic-Multimodal-Emotion-Recognition
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/FatimahEmadEldin/Moroccan-Arabic-Multimodal-Emotion-Recognition
下载链接
链接失效反馈官方服务:
资源简介:
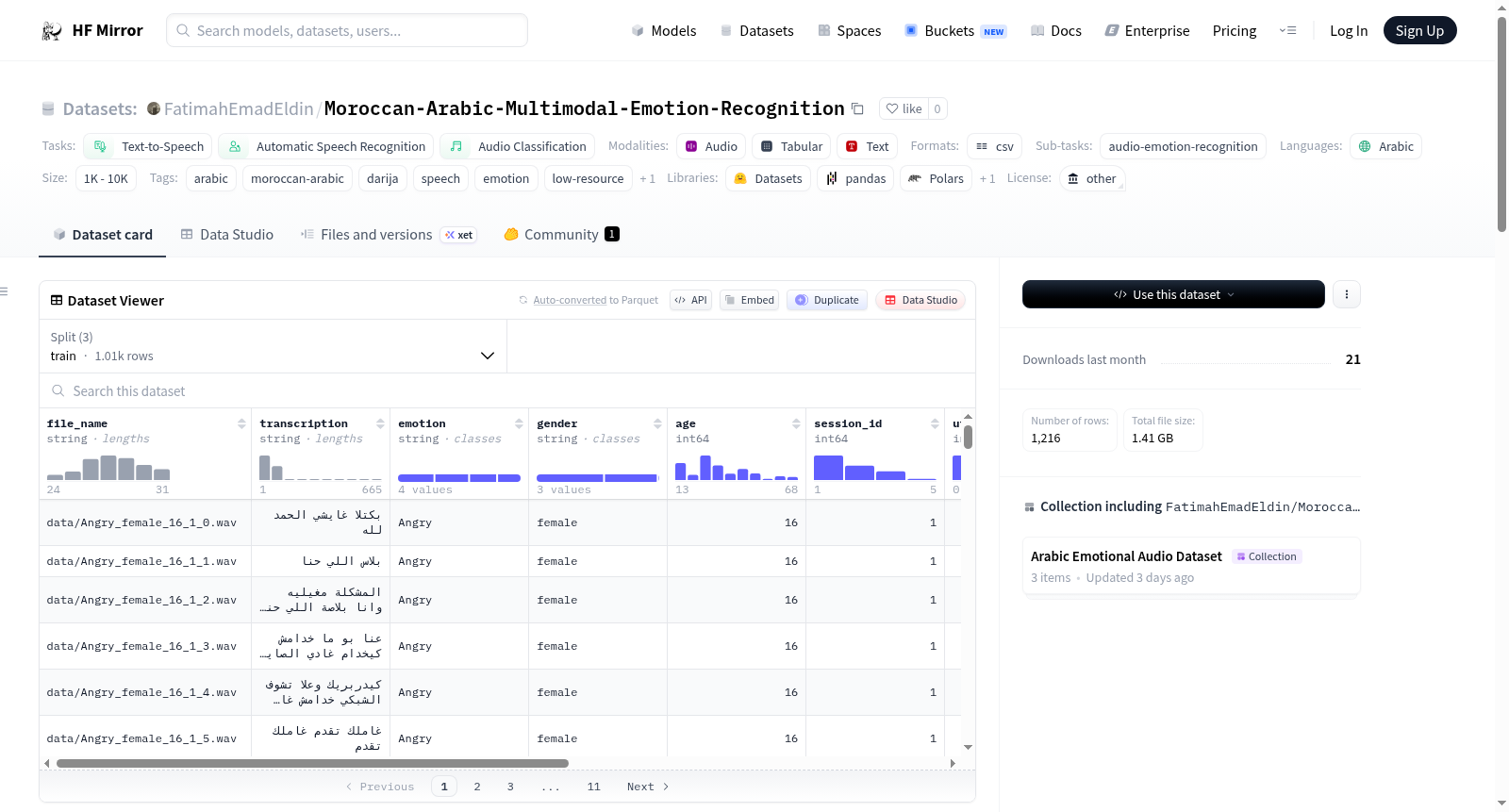
MDER-MA数据集是一个多模态情感识别数据集,专门针对摩洛哥阿拉伯语(Darija)设计。它包含了1216个音频与文本的配对,覆盖4种情感类别:愤怒、快乐、中性和悲伤。音频文件为48 kHz的立体声.wav格式,中位持续时间约为5秒。数据集还包含了说话者的性别、年龄、会话ID等详细信息,并且数据分割是说话者不相交的,以确保模型的泛化能力。该数据集适用于文本到语音、自动语音识别和音频分类等任务。
The MDER-MA dataset is a multimodal emotion recognition dataset specifically designed for Moroccan Arabic (Darija). It includes 1216 audio↔transcript pairs covering 4 emotion classes: Angry, Happy, Neutral, and Sad. The audio files are in 48 kHz stereo .wav format with a median duration of ≈5 seconds. The dataset also provides detailed information about the speakers gender, age, session ID, etc., and the splits are speaker-disjoint to ensure model generalization. This dataset is suitable for tasks such as text-to-speech, automatic speech recognition, and audio classification.
提供机构:
FatimahEmadEldin
搜集汇总
数据集介绍
构建方式
该数据集源自MDER-MA原始多模态情感语料库,经过文本对齐与重新封装,最终形成1216对音频与摩洛哥阿拉伯语(Darija方言)转录文本的配对样本。构建过程中,严格剔除了83条缺失转录的音频与20条无对应音频的文本文件,同时将原始语料中的语谱图与梅尔语谱图模态排除以控制存储规模。数据集依据66个独特说话人会话(以性别-年龄-会话ID三元组标识)进行划分,确保训练集、验证集与测试集之间说话人完全不相交,从而有效评估跨说话人的泛化能力。最终划分包含训练集1009条、验证集49条与测试集158条。
特点
该数据集的核心特色在于聚焦低资源语言摩洛哥阿拉伯语(Darija)的情感识别任务,覆盖愤怒、快乐、中性、悲伤四种基本情感类别。音频文件以48kHz立体声.wav格式存储,中位时长约5秒,并附带完整的转录文本、说话人性别、年龄、会话编号等元信息。尤其值得关注的是,数据集采用了说话人不相交的划分策略,使得模型性能评估更具客观性与泛化能力。此外,原始标注由五位母语者共同完成,确保了情感标签的信度。数据集还提供对原始论文与Mendeley存储库的引用,方便研究者获取完整多模态资源。
使用方法
研究者可通过HuggingFace的datasets库直接加载该数据集,一行代码即可获取划分好的训练、验证与测试集。加载后每条样本包含音频数组、采样率、转录文本、情感标签及说话人属性等字段,便于快速接入语音情感识别或情感语音合成流水线。由于数据集仅包含音频与文本模态,若需结合语谱图进行实验,用户可自行从音频文件生成。值得注意,该数据集针对摩洛哥Darija方言构建,直接用于现代标准阿拉伯语会面临领域迁移挑战,且说话人年龄与性别分布受原始语料限制,使用前需验证其对目标场景的适用性。
背景与挑战
背景概述
情感识别在人机交互、心理健康监测和智能客服等领域具有重要应用价值,然而多数研究聚焦于英语等高资源语言,低资源语言的情感识别研究长期处于边缘地带。摩洛哥阿拉伯语(Darija)作为一种广泛使用但标准语料匮乏的方言,其情感表达具有独特的文化特征和语音韵律,亟需专门的数据集支持。2025年,Soufiyan Ouali与Said El Garouani等研究者发布了MDER-MA数据集,该多模态情感识别数据集包含1216个音频-文本对,覆盖愤怒、快乐、中性和悲伤四类情感,由66个独立说话人录制,并通过说话人分离的划分方式确保评估的泛化性。该工作发表于《Data in Brief》,为低资源阿拉伯方言情感计算提供了基准资源,推动了非标准语言情感建模的进展。
当前挑战
该数据集所解决的领域挑战在于低资源场景下情感识别的数据稀缺性问题,特别是摩洛哥阿拉伯语(Darija)缺乏大规模标注语音语料库,且其口语化表达与标准阿拉伯语差异显著,导致现有模型难以直接迁移。在构建过程中,数据集面临的挑战包括:原始多模态数据中音频与文本模态不匹配,83份音频缺失对应转录、20份转录缺失对应音频,最终经筛选后才获得完整配对;情感标注依赖5名母语者的手动判断,可能存在标注偏差;说话人年龄范围与性别分布不均匀,且情感类别间说话人数量不均衡,容易引起模型偏向。此外,音频仅含语音模态而排除光谱图等其他模态,限制了多模态融合方法的全面评估。
常用场景
经典使用场景
在情感计算与自然语言处理的交叉领域中,低资源语言的语音情感识别始终是一项极具挑战性的课题。Moroccan-Arabic-Multimodal-Emotion-Recognition 数据集应运而生,专为摩洛哥阿拉伯语(Darija)这一资源匮乏的方言而构建。其最经典的用法在于为研究者提供经过文本-语音对齐的多模态情感数据,涵盖愤怒、快乐、中性、悲伤四种基本情感类别,每个音频片段均配有对应的阿拉伯语转录文本。该数据集特别设计了说话人无关的训练/验证/测试划分,使得模型在跨说话人场景下的泛化能力得以被严格评估,从而成为了低资源阿拉伯方言情感识别研究的标杆性基准。
衍生相关工作
基于该数据集,研究者已衍生出若干具有代表性的学术工作。原始论文(Ouali & El Garouani, 2025)发表于《Data in Brief》,详细介绍了数据集的构建流程、标注协议以及模态对齐方法,为后续研究奠定了方法论基础。围绕该数据集,后续工作可包括:针对摩洛哥方言的语音情感识别基线模型研究,比较传统声学特征与深度学习特征在该方言上的表现;探索基于预训练语音模型(如Wav2Vec 2.0)在该数据集上的微调策略,以验证跨语言迁移学习的有效性;以及利用文本模态进行情感增强的多模态融合方法,进一步提升低资源场景下的分类精度。这些衍生工作共同推动了北非方言情感计算方向的学术积累。
数据集最近研究
最新研究方向
随着多模态情感计算与低资源语言处理成为学界焦点,该数据集将摩洛哥阿拉伯语方言(Darija)与语音-文本对齐的情绪识别任务巧妙结合,开辟了阿拉伯语系非标准变体情感智能研究的新疆域。当前前沿方向聚焦于构建鲁棒的跨说话人泛化模型,以应对仅有52个训练说话人、六个验证说话人的严格说话人不重叠分割挑战,从而真实评估模型对未见声学特征的适应能力。该数据集涵盖愤怒、高兴、中性、悲伤四种基本情绪,并与语音合成(TTS)任务对齐,为探索情感驱动的低资源方言语音生成模型提供了稀缺的配对资源。研究热点还包括利用迁移学习从现代标准阿拉伯语(MSA)预训练模型向摩洛哥方言微调,以及验证五名母语标注者一致性在非标准变体上的可靠性,进而推动北非地区多元语言文化背景下的情感计算伦理与包容性发展。
以上内容由遇见数据集搜集并总结生成


