CFMM
收藏arXiv2024-04-24 更新2024-08-06 收录
下载链接:
http://arxiv.org/abs/2404.12966v2
下载链接
链接失效反馈官方服务:
资源简介:
CFMM数据集,由复旦大学智能信息处理上海市重点实验室创建,旨在评估多模态大型语言模型在反事实推理任务上的能力。该数据集包含1200张来自COCO-2014验证集的图像,每张图像配有一个基本问题和一个反事实问题,用于测试模型是否能正确理解反事实前提。数据集涵盖计数、颜色、大小、形状、方向和常识等六个评估维度,通过精心的人工标注确保数据质量。CFMM数据集的应用领域主要集中在提升多模态语言模型在复杂推理任务上的表现,特别是在处理视觉和语言结合的反事实问题上的能力。
The CFMM dataset, created by the Shanghai Key Laboratory of Intelligent Information Processing at Fudan University, is designed to evaluate the capabilities of multimodal large language models on counterfactual reasoning tasks. This dataset includes 1200 images sourced from the COCO-2014 validation set, with each image paired with a baseline question and a counterfactual question to test whether the model can correctly understand counterfactual premises. The dataset covers six evaluation dimensions: counting, color, size, shape, orientation and common sense, and its data quality is ensured through meticulous manual annotation. The main application scenarios of the CFMM dataset focus on improving the performance of multimodal language models on complex reasoning tasks, particularly their ability to handle vision-language combined counterfactual problems.
提供机构:
复旦大学智能信息处理上海市重点实验室
创建时间:
2024-04-19
搜集汇总
数据集介绍
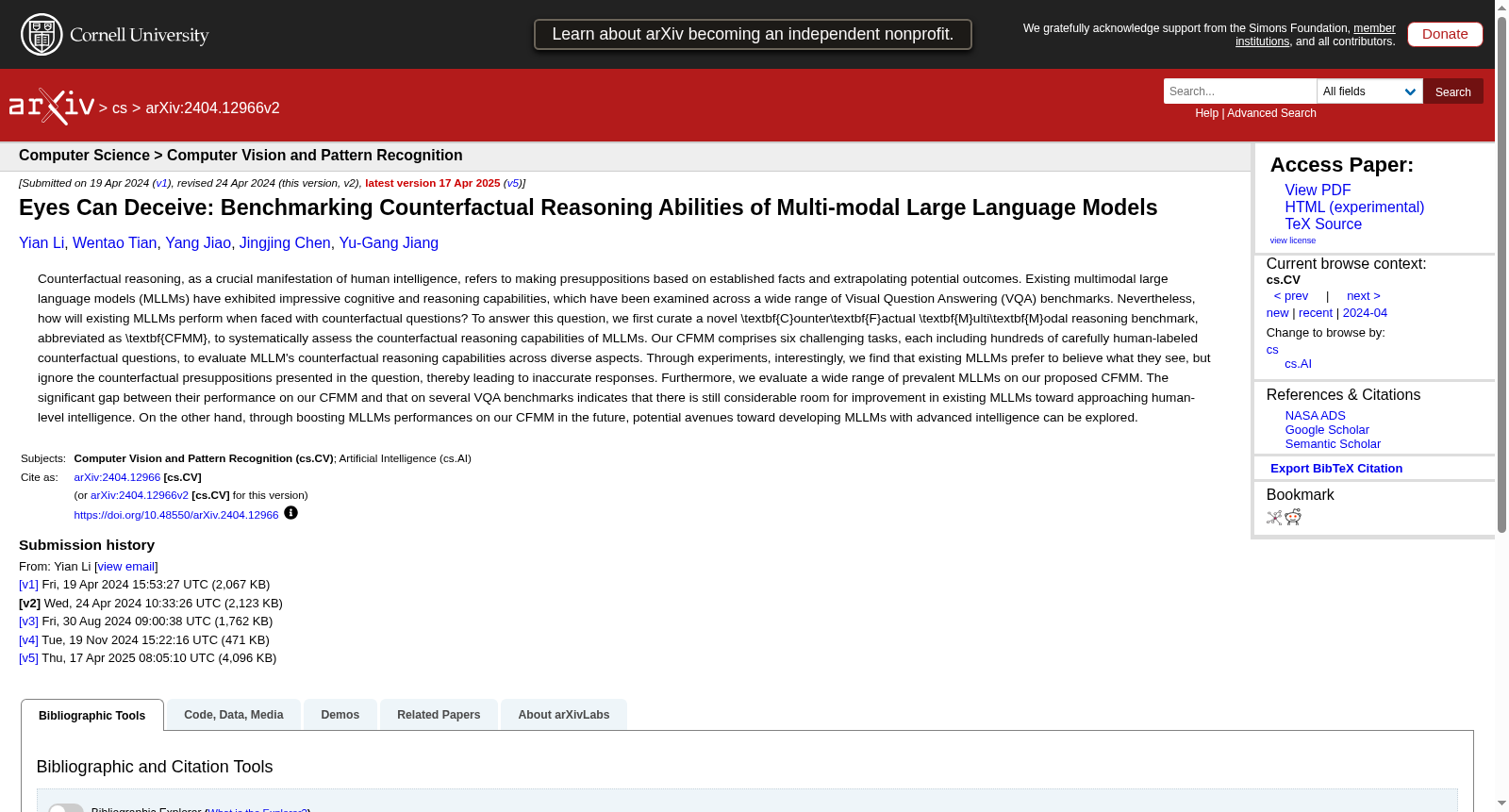
构建方式
反事实推理能力是人类智能的重要体现,然而现有多模态大语言模型在面对反事实问题时表现欠佳。为系统评估这一能力,CFMM数据集从COCO-2014验证集中精心筛选了1200张图像,并采用人工标注方式为每张图像构建成对的问题:一个为基础问题,用于测试基础的视觉理解;另一个为反事实问题,通过引入假设性前提来挑战模型的推理能力。标注过程严格遵循质量控制协议,由作者逐一审核,剔除信息泄露或答案模糊的样本。最终,数据集涵盖计数、颜色、大小、形状、方向和常识六大任务,每个任务包含数百个经过人工验证的样本,确保评估的全面性与可靠性。
特点
CFMM数据集的核心特点在于其针对多模态反事实推理的深度设计。与现有VQA基准不同,CFMM通过成对的基础与反事实问题,精准揭示模型是否真正理解了反事实前提,而非仅依赖视觉线索。数据集覆盖六大推理维度,从数值运算到空间关系,再到常识推理,层次化地评测模型的认知边界。此外,所有答案均以二元选择题形式呈现,并采用答案排序策略计算生成损失,以消除模型对选项位置的偏好,确保评估的客观性。实验表明,现有MLLMs在CFMM上的表现显著低于传统VQA基准,凸显了反事实推理作为衡量高级智能的试金石作用。
使用方法
使用CFMM数据集时,研究者可将图像与成对问题输入多模态大语言模型,通过计算每个选项的生成损失来提取模型的选择。评估指标包括基础问题准确率、反事实问题准确率以及两者均正确的联合准确率,总分600分。为深入分析,可引入少样本学习或思维链提示等轻量级技术,探究其对反事实推理能力的提升效果。实验结果显示,1-shot ICL能带来有限改进,而1-shot CoT在7B级模型上甚至可能降低性能,这为未来优化方向提供了启示。CFMM旨在为社区提供一个可靠的平台,以推动多模态反事实推理研究的发展。
背景与挑战
背景概述
反事实推理是人类智能的核心体现,要求个体基于既定事实提出假设并推演可能结果。近年来,多模态大语言模型(MLLMs)在视觉问答(VQA)基准上展现出卓越的认知与推理能力,然而其在反事实场景下的表现仍鲜有探究。为此,复旦大学上海智能信息处理重点实验室的研究团队于2024年提出了CFMM(CounterFactual MultiModal reasoning)基准数据集,旨在系统评估MLLMs的反事实推理能力。CFMM包含1200张来自COCO验证集的人工标注图像,每张图像配有一对基础问题与反事实问题,覆盖计数、颜色、尺寸、形状、方向及常识六大维度。该数据集通过二元选择题形式与答案排序策略确保评估客观性,揭示了现有MLLMs在反事实推理任务中的显著性能退化,为迈向人类级智能提供了关键评测平台。
当前挑战
CFMM所面临的挑战涵盖领域问题与构建过程双重层面。在领域问题层面,反事实推理要求模型突破“眼见为实”的认知惯性,需同时理解图像事实与文本假设并执行逻辑推演,而现有MLLMs倾向于依赖视觉线索而忽视反事实前提,导致在计数、颜色等基础属性任务上平均准确率骤降逾30个百分点,尤其在空间方位关系任务中表现最弱。在构建过程中,挑战包括:1)避免信息泄露,即反事实前提中不应隐含答案;2)消除答案歧义,确保从图像中可推导出精确结论;3)维持六类问题的均衡分布,其中形状类因易引发信息泄露而标注难度最高。此外,人工标注需严格质控,每道问题须经至少一位论文作者核验,以确保数据质量与评测可靠性。
常用场景
经典使用场景
在视觉与语言交叉领域,CFMM(CounterFactual MultiModal Reasoning benchmark)被设计用于评估多模态大语言模型的反事实推理能力。该数据集包含1200张来自COCO验证集的图像,每张图像配备一对人工标注的问题:一个为基础视觉问题,另一个为引入假设前提的反事实问题。反事实问题涵盖计数、颜色、形状、大小、方向与常识六大维度,旨在系统性地挑战模型在理解图像事实基础上,对假设性情景进行逻辑推演的能力。研究者通常利用CFMM来检验模型是否真正理解反事实前提,而非仅依赖视觉线索作答。
衍生相关工作
CFMM的出现催生了多项后续研究。例如,研究者尝试通过1-shot In-Context Learning(ICL)和Chain-of-Thought(CoT)提示策略来提升模型的反事实推理表现,但发现效果有限,仅对部分模型(如Qwen-VL)带来小幅提升,而对小规模模型甚至造成性能下降。这些发现激发了关于如何有效设计多模态ICL示例以及CoT在7B级MLLMs中适用性的深入探讨。此外,CFMM与C-VQA、CRASS等数据集形成了互补,共同推动了反事实推理在VQA和文本QA领域的系统化研究,为未来构建更高级的认知评估基准奠定了基础。
数据集最近研究
最新研究方向
当前,多模态大语言模型在视觉问答基准上展现出卓越性能,但其反事实推理能力仍是一个亟待探索的前沿方向。CFMM数据集的提出,正是为了系统性地评估MLLMs在面对假设性前提时的认知短板。该基准涵盖计数、颜色、形状、大小、方向及常识六大维度,通过精心设计的人工地标问题,揭示出模型倾向于“眼见为实”而忽略文本中的反事实预设,导致性能显著下降。这一发现与人工智能追求类人智能的热点紧密相关,尤其在推理鲁棒性和情境理解方面,CFMM为衡量和提升模型的深层认知能力提供了关键标尺,推动了多模态系统从感知向真正理解的跨越。
相关研究论文
- 1Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models复旦大学智能信息处理上海市重点实验室 · 2024年
以上内容由遇见数据集搜集并总结生成


