CMRC 2018
收藏arXiv2025-09-30 收录
下载链接:
http://ymcui.com/cmrc2018/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个跨度提取式的机器阅读理解数据集,它要求针对给定的问题提取出一个篇章跨度。此外,该数据集还用于评估SkillNet-NLU模型的性能。其所涉及的任务是阅读理解。
This dataset is a span-extractive machine reading comprehension dataset, which requires extracting a text span from a given passage based on the provided question. Additionally, this dataset is used to evaluate the performance of the SkillNet-NLU model, and the task it involves is machine reading comprehension.
搜集汇总
数据集介绍
构建方式
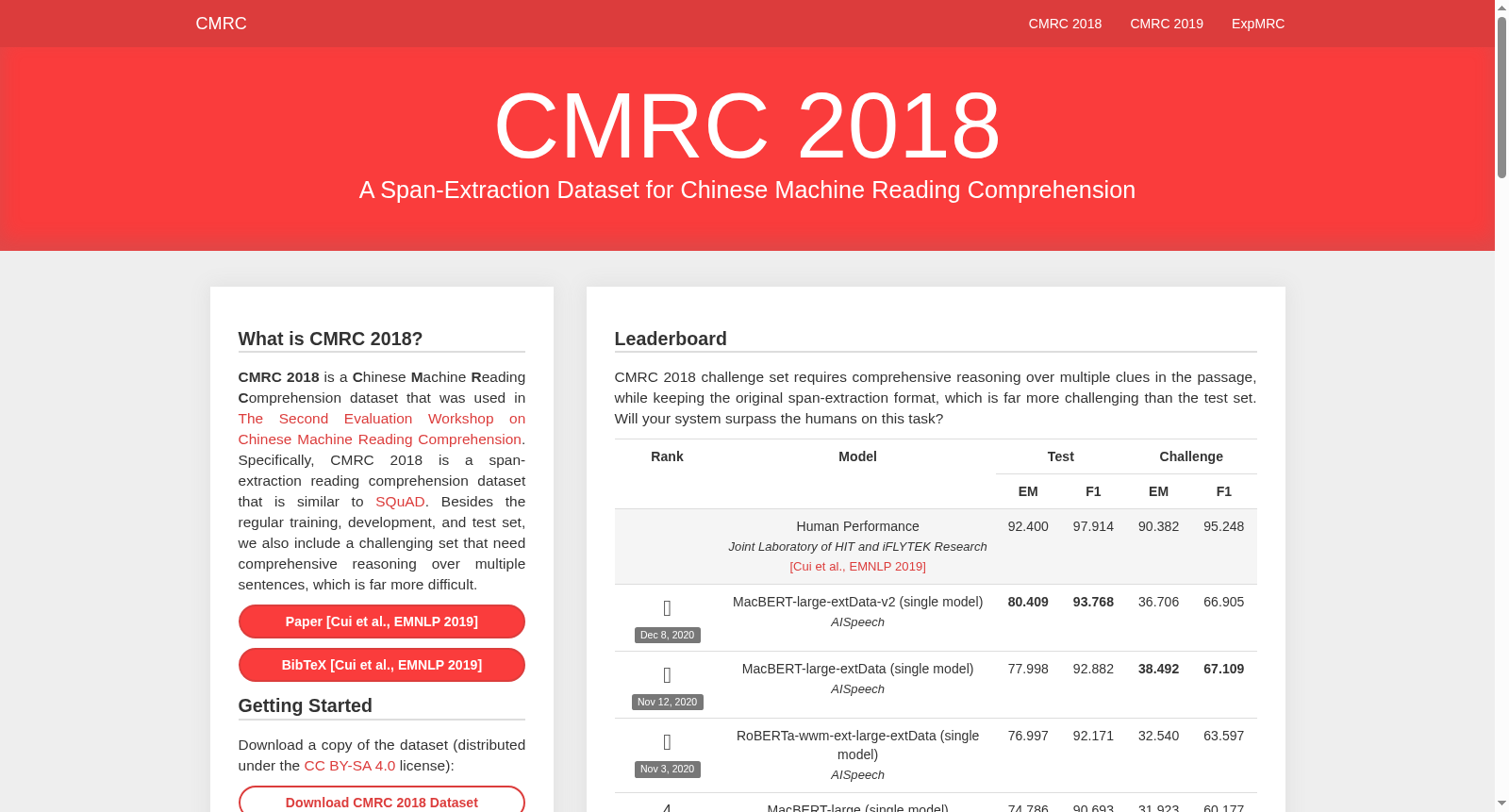
机器阅读理解领域长期以英文数据集为主导,CMRC 2018的诞生为中文自然语言处理注入了新的语言多样性。该数据集基于2018年1月的中文维基百科转储,经预处理后分割为不超过500个中文字符的段落,由人类专家进行完全人工标注。标注者首先评估段落适宜性,剔除含大量非中文字符、专业术语过多或使用文言文的文本,随后针对每个段落提出至多五个问题,确保答案严格为段落中的连续片段,并鼓励使用改写或句法变换来提升问题难度。评估集(开发、测试与挑战集)中每道问题配备三个独立标注的答案,以增强评价的鲁棒性。挑战集则额外要求问题需跨句子综合推理,且答案对应的实体类型在上下文中至少出现两次,从而增加模型的判别难度。
使用方法
CMRC 2018严格遵循跨度抽取式阅读理解范式,任务定义为给定段落与问题,预测答案在段落中的起始和结束位置。研究者可采用类似SQuAD的处理流程,将段落与问题拼接后输入预训练模型(如BERT),通过预测两个指针来定位答案片段。官方提供了基于run_squad.py的基线系统,设置学习率3e-5、批次大小32、训练2轮,文档与问题最大长度分别为512和64。评估指标采用精确匹配(EM)和基于最长公共子序列的字符级F1分数,忽略标点与空格。用户可通过CodaLab平台提交模型,在隐藏的测试集和挑战集上验证泛化能力,尤其适合跨语言迁移学习研究,与SQuAD等英文数据集协同使用,探索语言差异对阅读理解性能的影响。
背景与挑战
背景概述
机器阅读理解(MRC)作为自然语言处理领域的核心任务,旨在赋予机器从文本中提取信息并回答问题的能力。然而,长期以来,该领域的研究多聚焦于英语数据集,语言多样性的缺失限制了模型的泛化能力与跨语言迁移研究。为弥补这一空白,哈尔滨工业大学社会计算与信息检索研究中心与科大讯飞联合实验室于2018年发布了CMRC 2018数据集,这是一个面向中文的跨度抽取式阅读理解数据集。该数据集由近两万个基于维基百科段落的人工标注问题构成,并特别设计了挑战集,以考察模型对多线索推理与深层语义理解的能力。CMRC 2018的推出不仅丰富了中文MRC的资源库,还通过举办第二届中文机器阅读理解评测(CMRC 2018)推动了该领域的实证研究,成为跨语言阅读理解研究的重要基准。
当前挑战
CMRC 2018数据集所面临的挑战主要体现在两个层面。在领域问题层面,尽管当前模型在开发集与测试集上表现优异,但在挑战集上却遭遇显著性能滑坡,即便采用BERT等先进架构,其F1分数仍低于50%,远低于人类表现(约95%),凸显了模型在处理需跨句子、多线索综合推理的复杂问题时的脆弱性。在数据集构建过程中,挑战同样严峻:首先,人工标注需严格遵循规则,如答案必须为原文片段且长度受限,同时鼓励问题多样性(如为何、如何等),这对标注者的语言理解与创造力提出较高要求;其次,挑战集的设计需确保答案不可仅由单一句子推断,且需避免实体类型唯一性导致的简单匹配,这增加了数据筛选与质量控制的难度。
常用场景
经典使用场景
在自然语言处理领域,机器阅读理解(MRC)旨在赋予计算机从文本中提取精确信息的能力。CMRC 2018数据集作为一个中文跨度抽取(span-extraction)阅读理解基准,其经典使用场景是评估模型在给定中文段落中定位并抽取答案片段的能力。研究者通常将数据集划分为训练集、开发集和测试集,利用其近两万条由人工标注的高质量问答对,训练模型预测答案在原文中的起始与结束位置。该数据集特别设计了挑战集,要求模型具备跨多句的综合推理能力,从而成为检验中文MRC系统深层语义理解水平的试金石。
解决学术问题
CMRC 2018数据集有效填补了中文机器阅读理解领域缺乏大规模、高质量跨度抽取数据集的空白。在学术研究层面,它解决了两个核心问题:一是为跨语言MRC研究提供了与SQuAD等英文数据集对标的资源,促进了多语言模型的迁移学习与泛化能力评估;二是通过精心设计的挑战集,揭示了现有模型(包括BERT等预训练模型)在处理需要多线索推理的复杂问题时存在的显著短板——即便在常规测试集上表现优异,模型在挑战集上的F1值仍远低于人类水平,这推动了学术界对深层推理机制的深入探索。
实际应用
在实际应用层面,CMRC 2018数据集为构建中文智能问答系统提供了坚实的数据基础。其技术成果可广泛应用于搜索引擎的精准答案抽取、智能客服的自动回复、教育领域的阅读理解辅助批改以及知识图谱的自动化构建等场景。例如,基于该数据集训练的模型能高效地从长篇百科文档中定位用户查询的具体答案,显著提升信息检索的准确率与效率。此外,该数据集还催生了面向中文文档的自动化摘要与信息抽取工具,助力企业从海量文本中快速提取关键知识,降低人工阅读成本。
数据集最近研究
最新研究方向
在自然语言处理领域,机器阅读理解(MRC)的研究正从单一语言基准向多语言与跨语言泛化能力迈进。CMRC 2018作为首个大规模中文跨度抽取数据集,填补了非英语MRC资源的空白,其构建过程强调人工标注的精细化与挑战集的难度设计,尤其关注需要多句推理的复杂问题。当前前沿方向聚焦于如何利用预训练语言模型(如BERT)提升模型在中文语境下的边界识别与语义理解能力,同时该数据集被广泛用于评估模型在跨语言迁移场景下的鲁棒性。与SQuAD等英文基准的联合研究,推动了多语言阅读理解系统的对齐与优化,成为检验模型深层推理能力的重要标杆。
相关研究论文
- 1A Span-Extraction Dataset for Chinese Machine Reading Comprehension哈尔滨工业大学社会计算与信息检索研究中心 · 2019年
以上内容由遇见数据集搜集并总结生成


