FirstBML1/afrofinchain-multilingual-web3
收藏Hugging Face2026-04-30 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/FirstBML1/afrofinchain-multilingual-web3
下载链接
链接失效反馈官方服务:
资源简介:
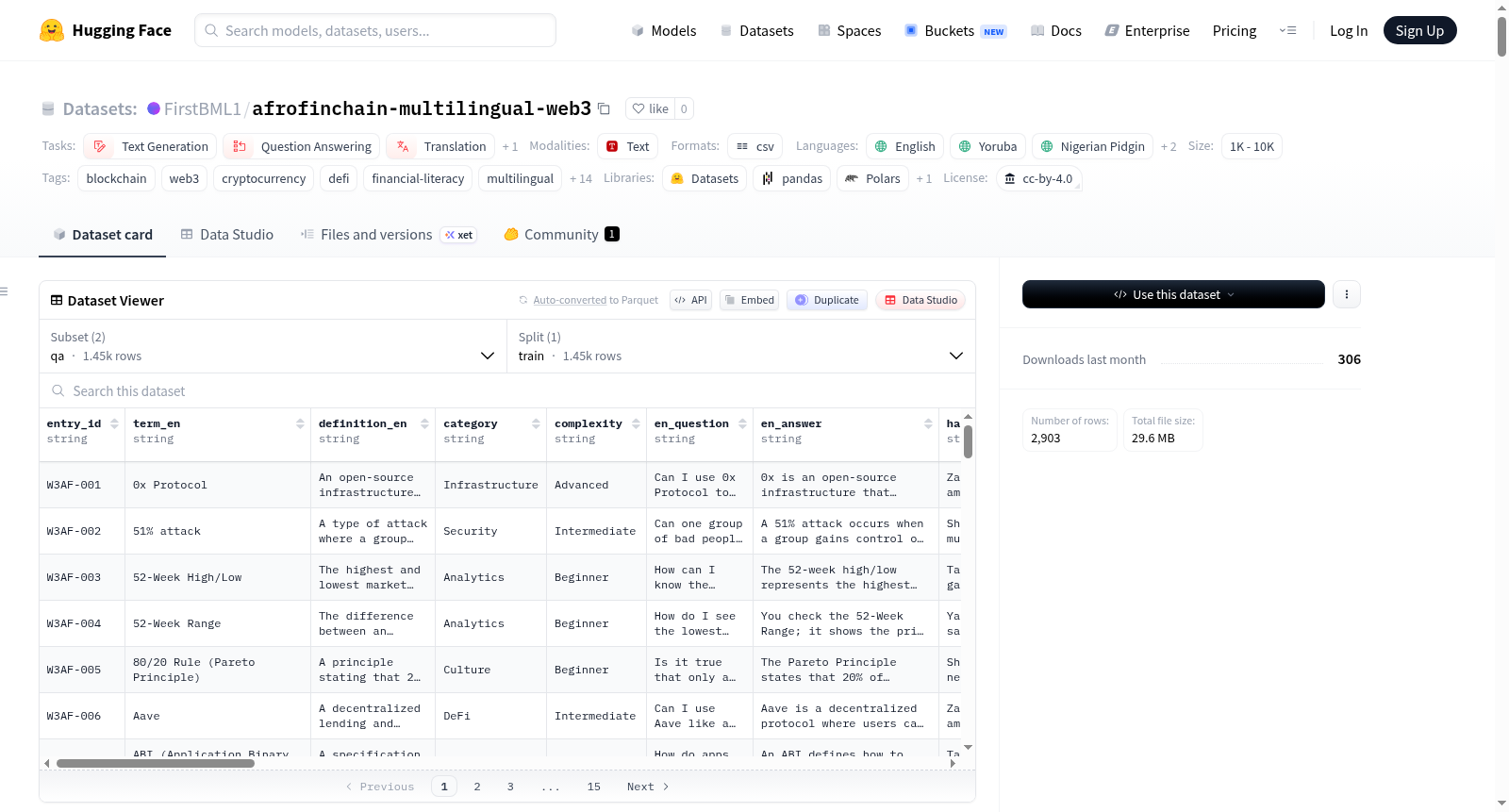
AfroFinChain是一个多语言的Web3和区块链数据集,涵盖英语、约鲁巴语、尼日利亚皮钦语、豪萨语和伊博语。该数据集包含1,451个术语条目和1,451个问答对,专为低资源非洲语言的LLM训练、金融素养和对话式AI设计。数据集分为两部分:术语数据集和问答数据集,每部分都有详细的列和部分。术语数据集包括每个术语的自然语言定义、使用示例和基于尼日利亚日常生活的文化类比。问答数据集则包含所有五种语言的对话式问答对,风格类似于WhatsApp、Telegram和Twitter的查询。该数据集旨在弥合非洲区块链教育的鸿沟,通过文化类比使区块链概念更易于理解。
AfroFinChain is a multilingual Web3 and blockchain dataset covering English, Yoruba, Nigerian Pidgin, Hausa, and Igbo. It includes 1,451 terminology entries and 1,451 Q&A pairs designed for LLM training, financial literacy, and conversational AI in low-resource African languages. The dataset is structured into two parts: terminology and Q&A, each with detailed columns and sections. The terminology dataset provides natural-language definitions, usage examples, and culturally specific analogies grounded in Nigerian daily life for each term. The Q&A dataset contains conversational question-and-answer pairs in all five languages, written in the register of WhatsApp, Telegram, and Twitter queries. The dataset aims to close the blockchain education gap in Africa by making blockchain concepts more understandable through cultural analogies.
提供机构:
FirstBML1
搜集汇总
数据集介绍
构建方式
AfroFinChain数据集基于对尼日利亚低资源语言的深刻洞察而构建,其核心目标是为约鲁巴语、豪萨语、伊博语和尼日利亚洋泾浜英语等语言提供Web3与区块链领域的教育资源。数据集的构建历经四个阶段:首先,从12个权威区块链参考文献中收集英语种子定义,并利用一个包含5106个术语的查找表进行映射;其次,利用Adaptive Data技术,通过定制化的蓝图(Blueprint)对术语和问答对进行多语言内容生成,不仅提供自然化的定义与使用示例,还融入了如Ajo、Adashi等本土文化类比;再次,针对生成过程中出现的12个异常行进行了识别与重新生成;最后,通过后处理流水线提取结构化字段,并将人工验证结果整合至主数据集中,确保了数据的规范性与可追溯性。
使用方法
AfroFinChain数据集设计为可直接用于机器学习与自然语言处理任务,适用于文本生成、问答、翻译和文本分类等领域。用户可通过HuggingFace平台加载数据,数据集分为术语表(terminology)和问答对(qa)两个配置,均以CSV格式提供。术语表包含丰富的列字段,如过滤后的ec_*列用于ML训练,以及完整的pipeline元数据用于审计。问答对则提供了多种语言的自然对话示例,特别适合微调大型语言模型(如GPT、LLaMA)以构建面向非洲市场的金融素养教育与防欺诈对话AI。研究人员可基于其多语言对齐特性进行跨语言迁移学习,或直接使用清洗后的数据文件进行模型训练与评估。
背景与挑战
背景概述
AfroFinChain多语言Web3与区块链数据集由Adaption Labs于2026年4月至5月间,在Adaption未知数据挑战赛(Uncharted Data Challenge)的框架下构建。该数据集聚焦于尼日利亚四种低资源语言(约鲁巴语、豪萨语、伊博语及尼日利亚皮钦语)与英语的跨语言迁移学习,核心研究问题在于弥合区块链技术与非洲本土金融知识之间的认知鸿沟。当前HuggingFace平台上尚无针对这些语言且结合区块链术语与问答对的公开数据集,AfroFinChain通过提供1,451条术语条目与等量的对话式问答对,填补了这一空白。数据集引入文化类比(如Ajo、Adashi、Isusu)将去中心化金融概念嵌入非洲社区熟悉的互助储蓄框架,为后续大语言模型微调、金融素养提升及欺诈防范工具开发奠定了稀缺的多语言基础资源。
当前挑战
该数据集面临的挑战首先来自领域问题:尼日利亚民众对加密资产普遍存在认知误解,庞氏骗局(如MMM)的历史阴影使得区块链与欺诈被混为一谈,而缺乏可信的本地化教育资源则成为技术普及与风险识别的根本障碍。在构建过程中,跨语言术语的自然化转写与文化类比的多样性不足构成核心难题——例如皮钦语类比池在生成时过度依赖有限参照,导致34条问答对出现类比薄弱标记。此外,低资源语言的语法深度(如伊博语变音符校正)、对话风格偏离日常通信纪实(如WhatsApp/Telegram语域还原),以及12条结构化输出的行级破损均需逐一修复。最终经由母语者抽样验证,术语与问答两分集分别达到98.1%和98.5%的通过率,印证了数据质量的可靠性。
常用场景
经典使用场景
在低资源语言的自然语言处理与金融教育交叉领域中,AfroFinChain多语种Web3数据集为构建面向非洲本土语言的区块链知识系统提供了稀缺的数据基础。其最经典的使用场景是在约鲁巴语、豪萨语、伊博语和尼日利亚皮钦语四种语言上微调大语言模型,使其具备理解与生成Web3、DeFi相关术语及对话的能力。数据集包含1,451条术语条目与同等数量的问答对,每条数据不仅提供定义和用法示例,更辅以本土文化类比(如Ajo、Adashi、Isusu等民间储蓄模式),将抽象的区块链概念转化为用户熟悉的日常生活经验。这种设计使得模型能够在真实对话语境中,而非教科书式的翻译中,完成对加密资产、去中心化金融等概念的跨语种解释,极大提升了信息传递的亲切感与可接受度。
解决学术问题
该数据集着力解决低资源非洲语言在区块链领域严重缺失的结构化知识资源这一学术瓶颈。在现有公开数据平台中,同时以yo、ha、ig、pcm为语言标签并涵盖区块链、Web3、加密货币术语的数据集完全空白,使得面向尼日利亚等非洲国家的多语种金融素养研究与跨语言迁移学习长期受限于数据匮乏。AfroFinChain的推出从根本上破除了这一障碍,为研究者提供了经过人工校验的术语定义、文化类比及对话式问答对,从而支撑起欺诈检测工具的语言适配、跨语种语义对齐模型的训练,以及从“加密货币即骗局”到“加密货币可理解”的知识传播范式转变。数据集的高质量验证结果(术语通过率98.1%,问答对通过率98.5%)确保了学术结论的可复现性与可靠性。
实际应用
在实际应用层面,AfroFinChain数据集直接服务于面向非洲用户的Web3金融教育产品与反欺诈工具的开发。基于该数据集微调的对话式AI系统,能够在WhatsApp、Telegram等即时通讯平台上以用户母语解释质押、流动性挖矿、私钥管理等概念,并以本地储蓄互助社(Ajo、Adashi、Isusu)为类比降低理解门槛。金融机构与科技企业可以借此构建面向尼日利亚市场的多语种DeFi知识问答机器人,帮助用户区分合法区块链项目与庞氏骗局,在源头上减少因信息不对称导致的资产损失。此外,该数据集还能支撑本地化金融合规文档的自动生成、政府普惠金融教育内容的跨语种分发,以及非英语Web3社区的社区支持系统建设,切实推动区块链技术在新兴市场的负责任落地。
数据集最近研究
最新研究方向
针对低资源非洲语言(约鲁巴语、豪萨语、伊博语、尼日利亚皮钦语)的Web3与区块链多语言数据集构建,近期研究前沿聚焦于将去中心化金融(DeFi)与加密货币的抽象概念,通过扎根于本土文化的类比(如Ajo、Adashi、Isusu等传统储蓄与互助体系)实现语义映射与认知降维,从而破解尼日利亚社区中因庞氏骗局历史与语言隔阂所催生的普遍信任赤字。该数据集填补了HuggingFace平台上该语种-领域交叉组合的空白,其1,451条术语与1,451条对话式问答对均经母语者人工校验,通过将刻板技术术语转化为融入日常语境的叙事范例,直接服务于大语言模型微调、跨语言金融素养教育及欺诈预防工具的研发,为新兴市场实现包容性数字金融启蒙提供了可复现、可审计的基础设施级资源。
以上内容由遇见数据集搜集并总结生成


