napolab
收藏Hugging Face2024-09-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ruanchaves/napolab
下载链接
链接失效反馈官方服务:
资源简介:
Napolab是一个用于评估大型语言模型的葡萄牙语数据集集合,包含多种任务类别,支持多种语言,并且遵循特定的指导原则。数据集大小在10万到100万条记录之间,并提供专门为大型语言模型设计的格式。
Napolab is a Portuguese dataset collection for evaluating large language models (LLMs) that includes multiple task categories, supports multiple languages, and adheres to specific guiding principles. The dataset ranges in size from 100,000 to 1,000,000 records and provides formats specifically designed for large language models.
创建时间:
2024-08-25
原始信息汇总
自然葡萄牙语基准 (Napolab)
数据集描述
- 主页: https://github.com/ruanchaves/napolab
- 仓库: https://github.com/ruanchaves/napolab
- 联系人: https://ruanchaves.github.io/
Napolab 是一个专为评估大型语言模型而收集的葡萄牙语数据集集合。
数据集格式
针对大型语言模型 (LLMs) 研究的 Napolab 格式包含以下两个主要字段:
- Prompt: 输入到 LLM 的提示。
- Answer: LLM 预期的分类输出标签,始终是一个介于 0 和 5 之间的数字。
该格式的数据集可通过 Hugging Face 访问。
数据集包含
Napolab 目前包含以下数据集:
数据集指南
Napolab 采用以下指南来包含数据集:
- 自然: 尽可能包含自然葡萄牙语文本或专业翻译文本。
- 可靠: 指标与人类判断可靠相关(准确性、F1 分数、Pearson 相关性等)。
- 公开: 每个数据集都通过公共链接提供。
- 人类: 仅包含专家人工标注,无自动或不可靠标注。
- 通用: 解决数据集任务不需要特定领域的知识或高级准备。
模型
我们在 Hugging Face Hub 上提供了多个在此基准上微调的模型:
| 数据集 | mDeBERTa v3 | BERT Large | BERT Base |
|---|---|---|---|
| ASSIN 2 - STS | 链接 | 链接 | 链接 |
| ASSIN 2 - RTE | 链接 | 链接 | 链接 |
| ASSIN - STS | 链接 | 链接 | 链接 |
| ASSIN - RTE | 链接 | 链接 | 链接 |
| HateBR | 链接 | 链接 | 链接 |
| FaQUaD-NLI | 链接 | 链接 | 链接 |
| PorSimplesSent | 链接 | 链接 | 链接 |
引用
如果您想在论文发表前引用我们的工作或模型,请使用以下 BibTeX 引用:
@software{Chaves_Rodrigues_napolab_2023, author = {Chaves Rodrigues, Ruan and Tanti, Marc and Agerri, Rodrigo}, doi = {10.5281/zenodo.7781848}, month = {3}, title = {{Natural Portuguese Language Benchmark (Napolab)}}, url = {https://github.com/ruanchaves/napolab}, version = {1.0.0}, year = {2023} }
免责声明
HateBR 数据集及其所有组件仅供学术和研究目的使用。未经 SINCH 事先书面同意,禁止将 HateBR 数据集用于任何商业或非学术目的。
搜集汇总
数据集介绍
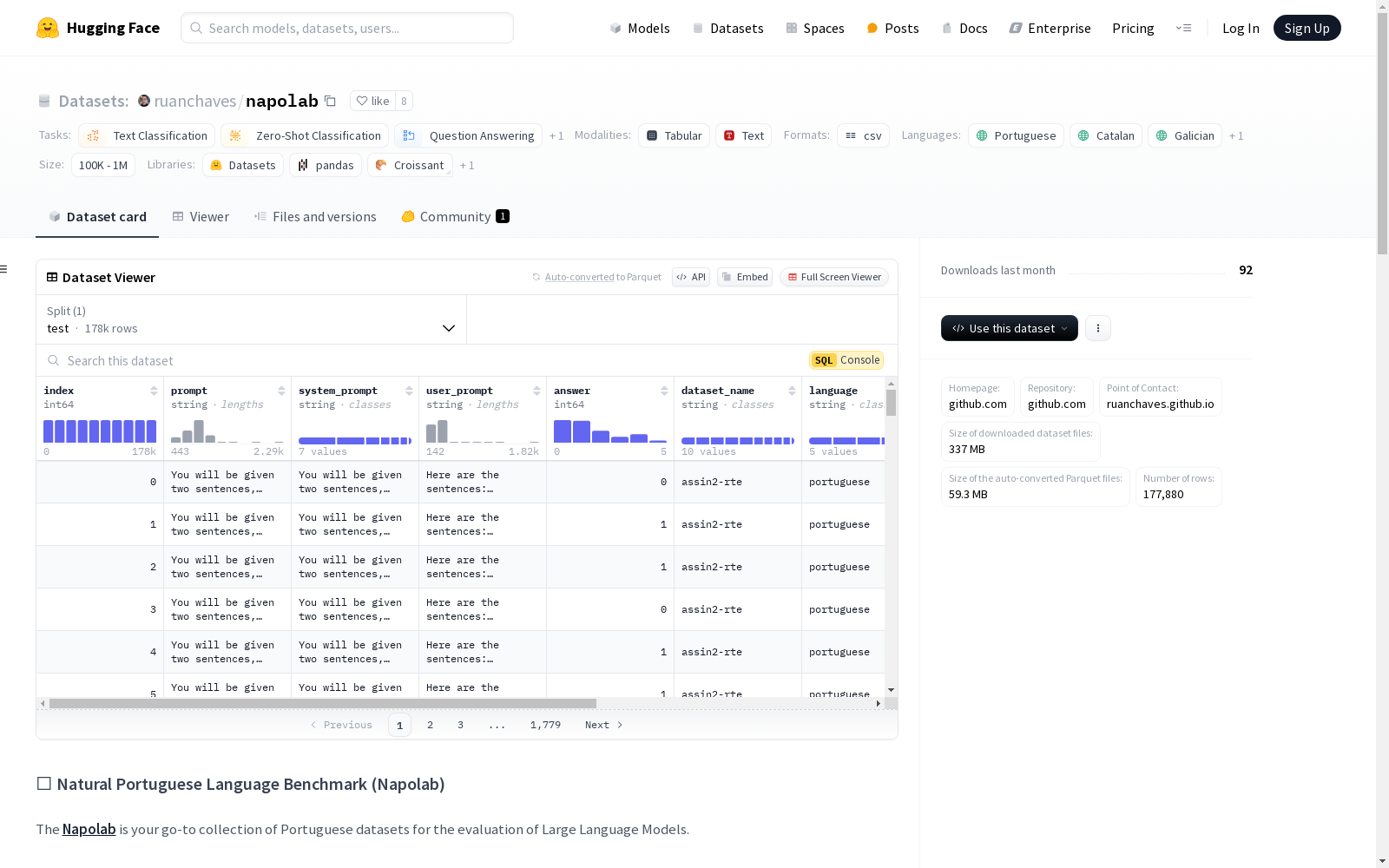
构建方式
Napolab数据集的构建基于自然葡萄牙语文本,涵盖了多种任务类别,如文本分类、零样本分类、问答和句子相似性。数据集通过专家人工标注确保质量,避免自动或不可靠的标注。所有数据集均通过公开链接提供,确保了数据的透明性和可访问性。此外,数据集还通过Easy-Translate工具翻译为加泰罗尼亚语、英语、加利西亚语和西班牙语,进一步扩展了其应用范围。
特点
Napolab数据集的特点在于其多样性和高质量。数据集包含超过10万条数据,涵盖了多种语言和任务类型,适用于大规模语言模型的评估。其标注过程严格遵循专家人工标注的原则,确保了数据的可靠性和准确性。此外,数据集的设计注重通用性,无需特定领域的知识即可完成任务,使其适用于广泛的研究场景。
使用方法
Napolab数据集的使用方法主要围绕大规模语言模型的评估展开。研究人员可以通过Hugging Face平台访问数据集,并将其用于模型训练和评估。数据集中的每个样本包含一个输入提示(Prompt)和一个预期的分类输出标签(Answer),便于直接应用于模型测试。此外,数据集还支持多语言任务,研究人员可以通过翻译版本进行跨语言模型的评估。使用该数据集的研究成果可通过Open PT LLM Leaderboard进行分享和比较。
背景与挑战
背景概述
Napolab数据集是由Ruan Chaves Rodrigues、Marc Tanti和Rodrigo Agerri等人于2023年推出的自然葡萄牙语基准测试数据集,旨在为大语言模型(LLMs)的评估提供高质量的葡萄牙语数据资源。该数据集涵盖了文本分类、零样本分类、问答和句子相似性等多种任务,支持葡萄牙语、加泰罗尼亚语、加利西亚语和英语等多语言环境。Napolab的创建不仅填补了葡萄牙语自然语言处理领域的数据空白,还为研究者提供了一个标准化的评估平台,推动了葡萄牙语语言模型的发展。
当前挑战
Napolab数据集在构建和应用过程中面临多重挑战。首先,葡萄牙语作为一种资源相对较少的语言,获取高质量、多样化的自然语言数据较为困难,尤其是在确保数据的自然性和可靠性方面。其次,数据集的构建依赖于专家的人工标注,这增加了时间和成本的投入,同时也对标注的一致性和准确性提出了更高要求。此外,尽管数据集支持多语言翻译,但如何确保翻译后的文本在语义和语法上与原语言保持一致,仍然是一个技术难题。最后,如何将Napolab数据集有效应用于大语言模型的评估,并确保评估结果的普适性和可重复性,也是研究者需要解决的关键问题。
常用场景
经典使用场景
Napolab数据集在自然语言处理领域中被广泛用于评估大型语言模型(LLMs)的性能。其经典使用场景包括文本分类、零样本分类、问答系统以及句子相似度计算。通过提供多样化的葡萄牙语文本数据,Napolab为研究人员提供了一个标准化的基准,用于测试和比较不同模型在葡萄牙语任务上的表现。
实际应用
在实际应用中,Napolab数据集被广泛用于开发葡萄牙语的智能助手、情感分析工具以及自动翻译系统。例如,基于Napolab训练的模型可以用于社交媒体上的情感分析,帮助企业了解用户对产品的反馈。此外,该数据集还被用于开发多语言问答系统,提升葡萄牙语用户的使用体验。
衍生相关工作
Napolab数据集衍生了许多经典的研究工作,特别是在葡萄牙语NLP领域。基于该数据集,研究人员开发了多个高性能的预训练模型,如mDeBERTa v3和BERT Large等。这些模型在文本相似度、情感分析等任务上表现出色,并被广泛应用于学术界和工业界。此外,Napolab还推动了Open PT LLM Leaderboard的发展,为葡萄牙语LLM的性能评估提供了标准化平台。
以上内容由遇见数据集搜集并总结生成


